class: center, middle # Text Mining in R Andrew Stewart<br><br> Division of Neuroscience and Experimental Psychology<br><br> University of Manchester<br><br> Email: andrew.stewart@manchester.ac.uk<br><br> Twitter: @ajstewart_lang<br><br> .pull-left[ <img src="images/ssi.png" width="100%" /> ] .pull-right[ <img src="images/bsbr.jpg" width="50%" /> ] --- # Text Mining There's a great book on text mining by Julia Silge and David Robinson all written to work with data in Tidy format. .pull-left[ <img src="images/text_mining.png" width="261" height="25%" /> ] .pull-right[ <img src="images/julia.png" width="180" height="180" /><img src="images/david.png" width="180" height="180" /> ] --- # What we'll cover today... Summarising text data. Sentiment analysis. Extracting frequency information (and demonstrating Zipf's law). Characterising text that plays a unique contribution in two different corpora. N-gram analysis. Scraping Twitter and visualising Twitter data. --- # Downloading some text data We are going to download from Project Gutenberg the text of four books by HG Wells. We will combine these four books into a dataframe called 'books'. ```r titles <- c("The War of the Worlds", "The Time Machine", "Twenty Thousand Leagues under the Sea", "The Invisible Man: A Grotesque Romance") books <- gutenberg_works(title %in% titles) %>% gutenberg_download(meta_fields = "title") ``` --- # Visualising the dataframe ```r vis_dat(books) ``` .center[ 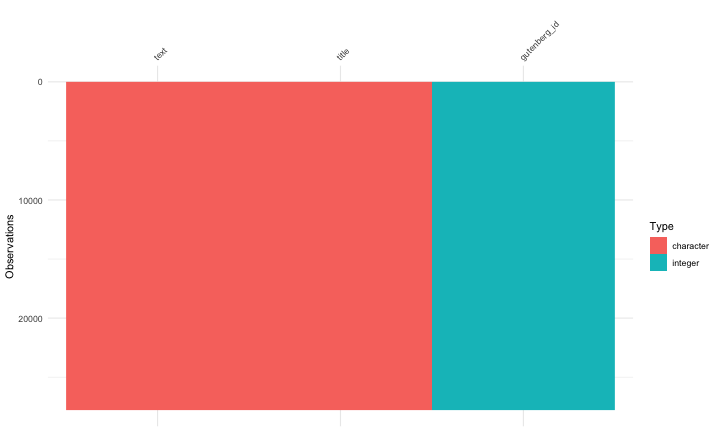<!-- --> ] --- ```r books$text ``` <img src="images/text.png" width="729" /> --- Currently the text is all in one column in our dataframe - we need to transform it into tidy format such that one word appears in each row. We do this by 'unnesting' the text column and removing 'stop words'. These are common words (e.g., function words like 'the' and 'of'). ```r all_text <- books %>% unnest_tokens(word, text) %>% anti_join(stop_words) ``` ``` ## Joining, by = "word" ``` ```r head(all_text) ``` ``` ## # A tibble: 6 x 3 ## gutenberg_id title word ## <int> <chr> <chr> ## 1 35 The Time Machine time ## 2 35 The Time Machine machine ## 3 35 The Time Machine 1898 ## 4 35 The Time Machine time ## 5 35 The Time Machine traveller ## 6 35 The Time Machine convenient ``` --- # Summary Data of the Corpus ```r all_text %>% group_by(title, word) %>% count(sort = TRUE) %>% ungroup() %>% top_n(8) ``` ``` ## Selecting by n ``` ``` ## # A tibble: 8 x 3 ## title word n ## <chr> <chr> <int> ## 1 Twenty Thousand Leagues under the Sea captain 607 ## 2 Twenty Thousand Leagues under the Sea nautilus 520 ## 3 Twenty Thousand Leagues under the Sea sea 349 ## 4 Twenty Thousand Leagues under the Sea nemo 347 ## 5 Twenty Thousand Leagues under the Sea ned 320 ## 6 Twenty Thousand Leagues under the Sea conseil 271 ## 7 Twenty Thousand Leagues under the Sea land 240 ## 8 Twenty Thousand Leagues under the Sea water 236 ``` --- # Summary Data of War of the Worlds ```r all_text %>% filter(title == "The War of the Worlds") %>% group_by(word) %>% tally(sort = TRUE) %>% top_n(10) ``` ``` ## # A tibble: 10 x 2 ## word n ## <chr> <int> ## 1 martians 163 ## 2 people 159 ## 3 black 122 ## 4 time 121 ## 5 road 104 ## 6 night 102 ## 7 brother 91 ## 8 pit 83 ## 9 martian 79 ## 10 water 79 ``` --- class: center, middle <img src="Chester_talk_files/figure-html/unnamed-chunk-14-1.png" width="720" /> --- # Sentiment Analysis We can use one of the sentiment databases built-in to the tidytext package. The 'bing' database has sentiment ratings (positive vs. negative) for almost 7,000 words. ```r get_sentiments("bing") ``` ``` ## # A tibble: 6,786 x 2 ## word sentiment ## <chr> <chr> ## 1 2-faces negative ## 2 abnormal negative ## 3 abolish negative ## 4 abominable negative ## 5 abominably negative ## 6 abominate negative ## 7 abomination negative ## 8 abort negative ## 9 aborted negative ## 10 aborts negative ## # … with 6,776 more rows ``` --- We can 'join' our books dataframe to this database using the inner_join() function from the dplyr package. ```r all_text_sent <- all_text %>% inner_join(get_sentiments("bing")) ``` ``` ## Joining, by = "word" ``` ```r head(all_text_sent) ``` ``` ## # A tibble: 6 x 4 ## gutenberg_id title word sentiment ## <int> <chr> <chr> <chr> ## 1 35 The Time Machine convenient positive ## 2 35 The Time Machine pale negative ## 3 35 The Time Machine burned negative ## 4 35 The Time Machine soft positive ## 5 35 The Time Machine radiance positive ## 6 35 The Time Machine luxurious positive ``` --- ```r all_text_sent %>% filter(title == "The War of the Worlds") %>% count(word, sentiment, sort = TRUE) %>% top_n(25) %>% mutate(n = ifelse(sentiment == "negative", -n, n)) %>% mutate(word = reorder(word, n)) %>% ggplot(aes(x = word, y = n, fill = sentiment)) + geom_col() + coord_flip() + labs(title = "Sentiment Analysis of Top 25 Words in The War of the Worlds", x = "Word", y = "Count") + theme(text = element_text(size = 20)) ``` --- <img src="Chester_talk_files/figure-html/unnamed-chunk-18-1.png" width="720" /> --- # Examining proprtion of usage of each word ```r book_words <- all_text %>% group_by(title) %>% count(title, word, sort = TRUE) total_words <- book_words %>% group_by(title) %>% summarise(total = sum(n)) book_words <- left_join(book_words, total_words) ``` ``` ## Joining, by = "title" ``` --- ```r book_words %>% mutate(proportion = n/total) %>% group_by(title) %>% arrange(desc(proportion)) %>% top_n(3) %>% select(-n, -total) ``` ``` ## Selecting by proportion ``` ``` ## # A tibble: 12 x 3 ## # Groups: title [4] ## title word proportion ## <chr> <chr> <dbl> ## 1 The Time Machine time 0.0180 ## 2 Twenty Thousand Leagues under the Sea captain 0.0153 ## 3 Twenty Thousand Leagues under the Sea nautilus 0.0131 ## 4 The Invisible Man: A Grotesque Romance kemp 0.0121 ## 5 The Invisible Man: A Grotesque Romance invisible 0.0102 ## 6 The Invisible Man: A Grotesque Romance door 0.00961 ## 7 Twenty Thousand Leagues under the Sea sea 0.00880 ## 8 The Time Machine machine 0.00765 ## 9 The War of the Worlds martians 0.00722 ## 10 The War of the Worlds people 0.00704 ## 11 The War of the Worlds black 0.00540 ## 12 The Time Machine white 0.00531 ``` --- # Visualizing the data - Zipf's Law 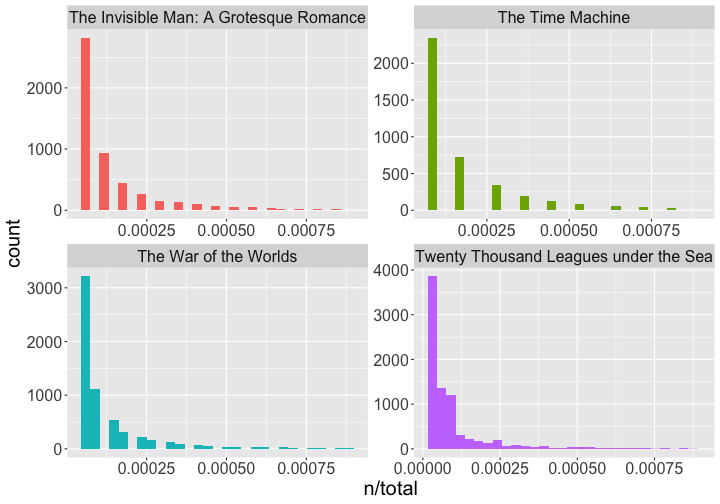<!-- --> --- # Which words are most important (and unique) to each book? The bind_tf_idf() function works out the important words for each book by adding a weighting to each word - decreasing the weight for commonly used words and increasing the weight for words not used much in the overall corpus. This allows us to identify what words tend to be uniquely associated with each of the four books. ```r book_words <- book_words %>% bind_tf_idf(word, title, n) ``` --- ```r book_words %>% group_by(title) %>% top_n(15) %>% ungroup %>% ggplot(aes(x = reorder(word, tf_idf), y = tf_idf, fill = title)) + geom_col(show.legend = FALSE) + labs(x = NULL, y = "tf_idf") + facet_wrap(~title, ncol = 2, scales = "free") + coord_flip() + theme(text = element_text(size = 20)) ``` --- 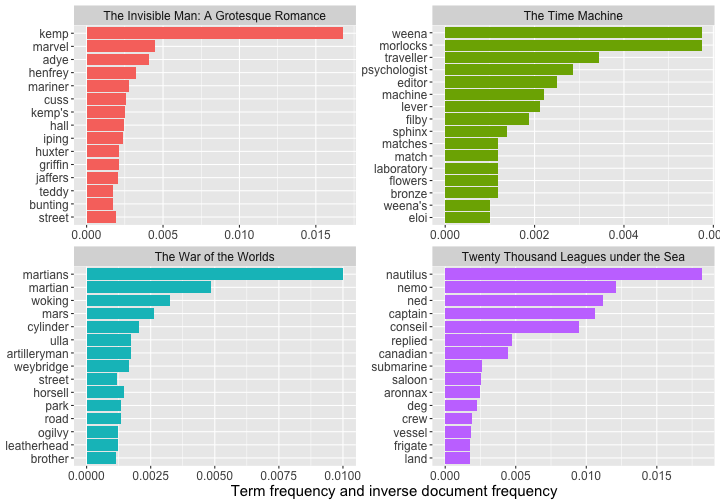<!-- --> --- # N-gram tokenizing So far we've unnested such that each word is separate. But we can also unnest by n-grams to capture sequences of words. In this example, let's look at tokenizing by bigram. ```r wells_bigrams <- books %>% filter(title == "The War of the Worlds") %>% unnest_tokens(bigram, text, token = "ngrams", n = 2) bigrams_separated <- wells_bigrams %>% separate(bigram, c("word1", "word2", sep = " ")) bigrams_filtered <- bigrams_separated %>% filter(!word1 %in% stop_words$word) %>% filter(!word2 %in% stop_words$word) bigrams_counts <- bigrams_filtered %>% count(word1, word2, sort = TRUE) ``` --- # Top bigrams in War of the Worlds ``` ## Selecting by n ``` ``` ## # A tibble: 12 x 3 ## word1 word2 n ## <chr> <chr> <int> ## 1 heat ray 35 ## 2 red weed 26 ## 3 black smoke 25 ## 4 ulla ulla 21 ## 5 handling machine 15 ## 6 sand pits 14 ## 7 pine trees 12 ## 8 fighting machine 10 ## 9 hundred yards 10 ## 10 fighting machines 9 ## 11 pine woods 9 ## 12 woking station 9 ``` --- # War of the Worlds bigram network graph <!-- --> --- # Scraping Twitter The package `rtweet()` by Mike Kearney allows us to scrape Twitter for data. First you need to set up a Twitter API access token. Full instructions are provide in one of the rtweet vignettes - there are two methods with the "2. Access token/secret method" the more straightforward: ```r vignette("auth") ``` <img src="images/auth.png" width="85%" /> --- # Visualising Data from Twitter Scraping Twitter using the rtweet() package for everyone's favourite progressive Swedish death metal band, Opeth! 🤘 ```r library(rtweet) ``` The code below uses the search_tweets() function from the rtweet package. The first parameter is the query to be searched for, n is the number of tweets to return. By setting include_rts to FALSE we are ignoring re-tweets that mention "Opeth". retryonratelimit means that if we get timed out by the Twitter API, the code will pause until the limit resets. ```r tweets <- search_tweets(q = "Opeth", n = 2000, include_rts = FALSE, retryonratelimit = TRUE) ``` --- Let's tidy the dataframe to separate out the data and time of each tweet, plus select only a small number of columns we're interested in. ```r tweets <- tweets %>% separate(col = created_at, into = c("date", "time"), sep = " ") %>% select(screen_name, date, time, text, coords_coords, bbox_coords, geo_coords) ``` --- The Tweets dataframe looks like this: .center[ ```r vis_dat(tweets) ``` 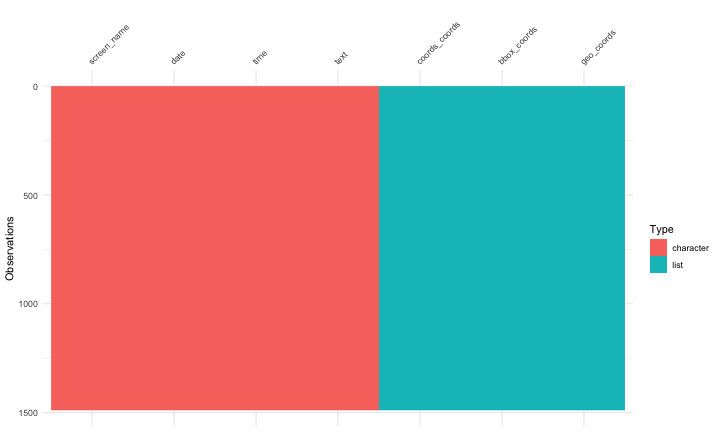<!-- --> ] --- 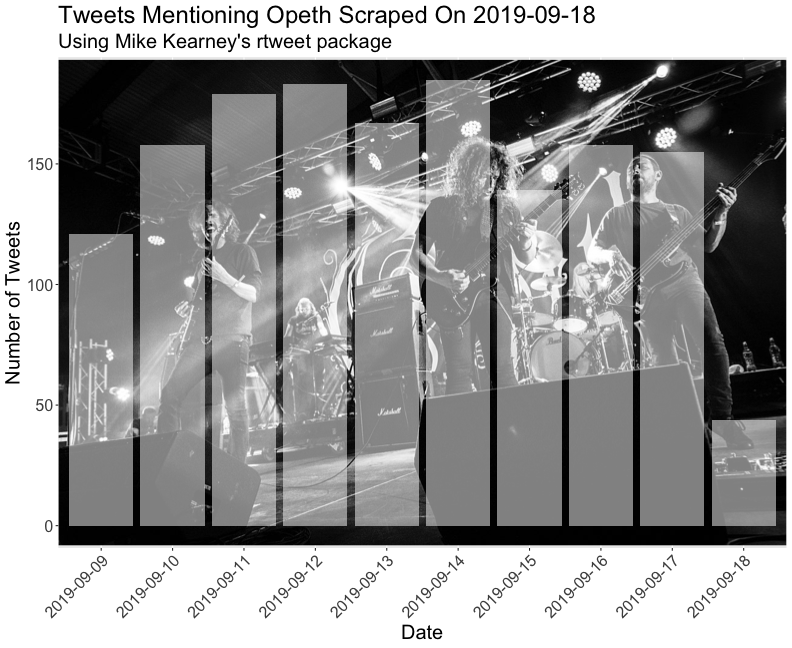<!-- --> --- class: centre # Geospatial Plotting of Tweets .center[ <div id="htmlwidget-cd0c88fa511477cc4215" style="width:576px;height:432px;" class="leaflet html-widget"></div> <script type="application/json" data-for="htmlwidget-cd0c88fa511477cc4215">{"x":{"options":{"crs":{"crsClass":"L.CRS.EPSG3857","code":null,"proj4def":null,"projectedBounds":null,"options":{}}},"calls":[{"method":"addTiles","args":["//{s}.tile.openstreetmap.org/{z}/{x}/{y}.png",null,null,{"minZoom":0,"maxZoom":18,"tileSize":256,"subdomains":"abc","errorTileUrl":"","tms":false,"noWrap":false,"zoomOffset":0,"zoomReverse":false,"opacity":1,"zIndex":1,"detectRetina":false,"attribution":"© <a href=\"http://openstreetmap.org\">OpenStreetMap<\/a> contributors, <a href=\"http://creativecommons.org/licenses/by-sa/2.0/\">CC-BY-SA<\/a>"}]},{"method":"addCircles","args":[[null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,52.20097375,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-22.781072,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,51.5261692,51.5261692,null,null,null,null,null,null,null,null,null,-33.4521612,-33.4521612,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,59.333671,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,40.4,43.7576727,40.655138,40.655138,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,63.85406,63.85406,63.85406,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,52.641483,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-6.842406,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,53.025,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,57.15064305,57.15064305,null,null,null,null,null,null,null,null,null,null,null,null,null,41.1160217822102,41.11602178,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-29.7498334,-29.7498334,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,35.209059,59.333671,59.333671,59.333671,59.333671,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,50.62897405,null,null,null,null,null,null,null,null,null,null,null,35.6310385,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-34.604315,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,38.8355538,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,37.5564177132517,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,41.83358445,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,59.58021095,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,26.33263415,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,41.83358445,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,40.37624085,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null],[null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,0.1359161,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-42.139657,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,0.445301,0.445301,null,null,null,null,null,null,null,null,null,-70.6596154,-70.6596154,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,17.9800589,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-3.68333,13.06007645,-73.9487755,-73.9487755,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,15.57374,15.57374,15.57374,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,1.2730815,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,106.9427665,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-0.868611,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,65.55684455,65.55684455,null,null,null,null,null,null,null,null,null,null,null,null,null,-74.0213986943672,-74.02139869,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-75.74854275,-75.74854275,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-80.8467855,17.9800589,17.9800589,17.9800589,17.9800589,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,3.07158865,null,null,null,null,null,null,null,null,null,null,null,-120.67429,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-58.4426431,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-9.36058945,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,126.911462975596,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-87.732013,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,15.87433535,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,17.26814,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-87.732013,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-80.0502625,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null],40,null,null,{"interactive":true,"className":"","stroke":true,"color":"#fb3004","weight":8,"opacity":0.5,"fill":true,"fillColor":"#fb3004","fillOpacity":0.8},null,null,null,{"interactive":false,"permanent":false,"direction":"auto","opacity":1,"offset":[0,0],"textsize":"10px","textOnly":false,"className":"","sticky":true},null,null]}],"limits":{"lat":[-34.604315,63.85406],"lng":[-120.67429,126.911462975596]}},"evals":[],"jsHooks":[]}</script> ] --- # Scraping Individual Timelines Let's get the last 1,000 Tweets by the authors Stephen King and Neil Gaiman. ```r timeline_tweets <- get_timeline(user = c("neilhimself", "StephenKing"), n = 1000, max_id = NULL, home = FALSE, parse = TRUE, check = TRUE) ``` --- # Top 20 words in each author's Tweets 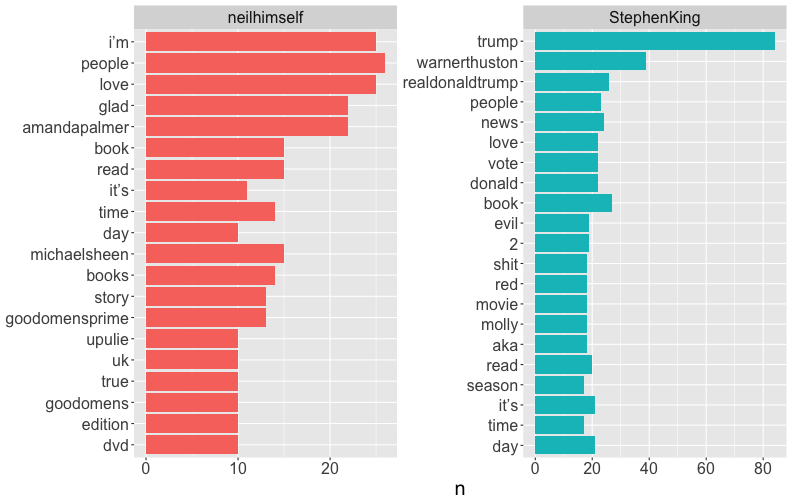<!-- --> --- # Which words characterise Neil Gaiman's vs. Stephen King's Tweets? 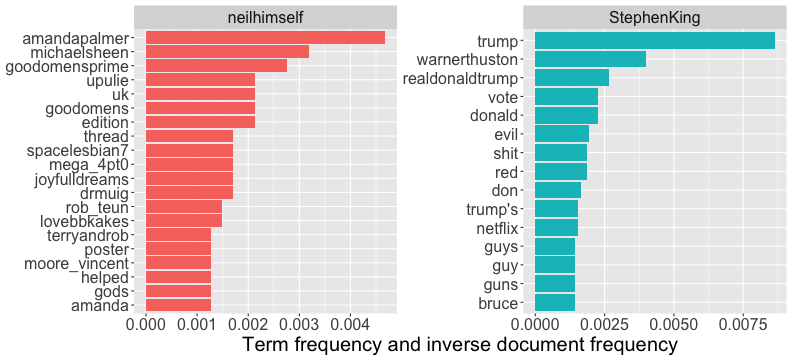<!-- --> --- # At what time do the authors Tweet? 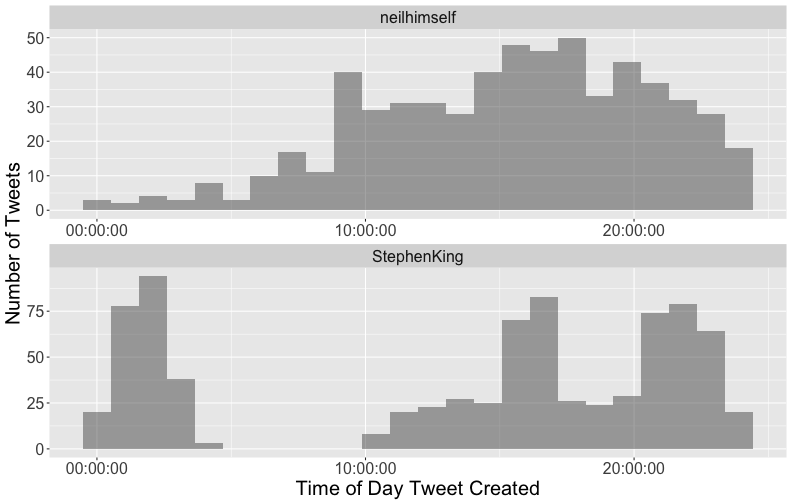<!-- --> --- # Neil Gaiman's Tweets by source 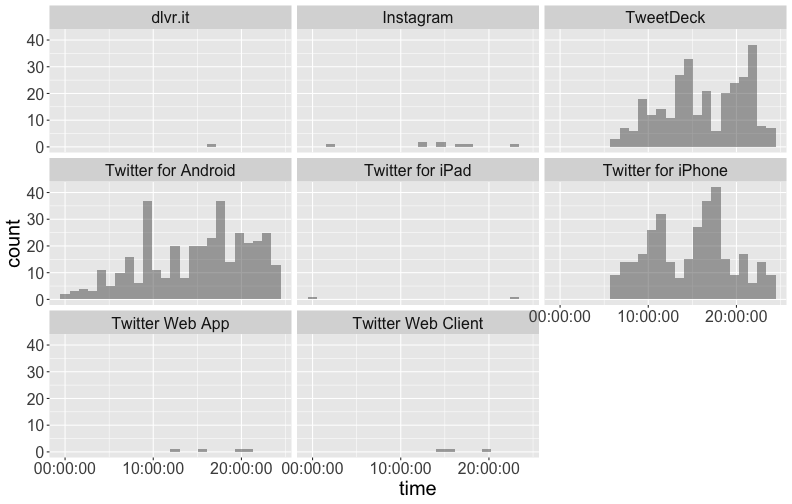<!-- --> --- # That was a fully reproducible talk (just add my accent) All slides and R code used to generate these slides available [here](https://github.com/ajstewartlang/Chester_text_mining_R) <br /> <img src="images/ssi.png" width="1575" height="50%" /> <br /> Slides created via the R package [**xaringan**](https://github.com/yihui/xaringan), [**knitr**](http://yihui.name/knitr), and [R Markdown](https://rmarkdown.rstudio.com).