class: center, middle, title-slide # Reproducible Data Visualisations ### Andrew Stewart<br>University of Manchester<br>Division of Neuroscience and Experimental Psychology<br>Software Sustainability Institute Fellow<br>Twitter: <span class="citation">@ajstewart_lang<br>GitHub</span>: github.com/ajstewartlang ### (updated: 2019-06-04) --- class: center # Science that can be replicated <i>vs.</i> science that can be reproduced .left[ <b>Replicable Science</b> is when someone else can run a study the same as or conceptually equivalent to your one, and find a similar pattern of effects. <b>Reproducible Science</b> is when someone else can take your data and your analysis code, run it and then find the same effects that you have reported. ] -- <b>How do we make our science more replicable? How do we make our science more reproducible?</b> --- # A move towards open science… You really should read this book! .pull-left[ <img src="images/deadly.jpg" width="80%" /> ] .pull-right[<br><br>Sins include <i>p</i>-hacking, lack of power, HARKing, failing (refusal) to share data and code, too many researcher degrees of freedom… ] --- <img src="images/Gelman.jpg" width="80%" /> http://www.stat.columbia.edu/~gelman/ Andrew Gelman gives the following recommendations to researchers: - Analyze all your data. - Present all your comparisons. - Put in the effort to take accurate measurements (low bias, low variance, and a large enough sample size). - Do repeated-measures comparisons where possible. - Make your data public. But it's not just the data you need to make public, but also your <b>code</b>! --- # What role can R play in Open and Reproducible Science? - R scripts are easy to share allowing for reproducibility and easy public sharing of data and code. - R is free, open source software that is much more flexible and powerful than SPSS. - There is an active R community continuously updating statistical tests and packages that run in R. - As R is a programming language, it forces you to <b>know</b> your data. --- # R <i>vs.</i> SPSS .middle[ “SPSS is like a bus - easy to use for the standard things, but very frustrating if you want to do something that is not already pre-programmed. R is a 4-wheel drive off-roader, with a bike on the back, a kayak on top, good walking and running shoes in the passenger seat, and mountain climbing and spelunking gear in the back. R can take you anywhere you want to go if you take time to learn how to use the equipment, but that is going to take longer than learning where the bus stops are in SPSS.” <i>(Greg Snow, 2010, stackoverflow.com)</i> ] --- # In meme form… <img src="images/meme.png" width="1203" /> --- # A workflow for reproducible science in the Tidyverse .center[ <img src="images/tidyverse.png" width="90%" /> ] --- # A workflow for reproducible science in the Tidyverse <img src="images/tidyflow.png" width="1200" /> https://www.tidyverse.org --- class: center, middle # Why Data Visualisation is Important --- class: center, middle # Anscombe's Quartert --- # Plot 1 .pull-left[ <!-- --> ] .pull-right[ ``` ## [1] "Mean of X is: 9" ``` ``` ## [1] "SD of X is: 3.32" ``` ``` ## [1] "Mean of Y is: 7.5" ``` ``` ## [1] "SD of Y is: 2.03" ``` ] ``` ## [1] "Pearson's r is 0.82" ``` --- # Plot 2 .pull-left[ <!-- --> ] .pull-right[ ``` ## [1] "Mean of X is: 9" ``` ``` ## [1] "SD of X is: 3.32" ``` ``` ## [1] "Mean of Y is: 7.5" ``` ``` ## [1] "SD of Y is: 2.03" ``` ] ``` ## [1] "Pearson's r is 0.82" ``` --- # Plot 3 .pull-left[ <!-- --> ] .pull-right[ ``` ## [1] "Mean of X is: 9" ``` ``` ## [1] "SD of X is: 3.32" ``` ``` ## [1] "Mean of Y is: 7.5" ``` ``` ## [1] "SD of Y is: 2.03" ``` ] ``` ## [1] "Pearson's r is 0.82" ``` --- # Plot 4 .pull-left[ <!-- --> ] .pull-right[ ``` ## [1] "Mean of X is: 9" ``` ``` ## [1] "SD of X is: 3.32" ``` ``` ## [1] "Mean of Y is: 7.5" ``` ``` ## [1] "SD of Y is: 2.03" ``` ] ``` ## [1] "Pearson's r is 0.82" ``` --- # Plots Based on Aggregated Data Can Mislead… .center[ ```r ggplot(data1, aes(x = Group, y = RT)) + geom_boxplot() ``` <!-- --> ] --- # But look more closely at the actual data… .center[ <!-- --> ] --- # The distribution of data matters The data on the previous slide are clearly bimodal with no data point near the mean. Distribution shape matters and we need to capture that in our data visualisations. If we only plotted and reported information related to aggregated data, we wouldn't be being honest about what our data look like. --- # Reasons for visualising data -- For yourself - once you have collected your data, you should visualise it before you build any statistical models - does the data look (roughly) as expected with the right number of data points? -- For others - when you present your work in a talk, on a poster, or in a published paper you want the viewer to be able to quickly and unambiguously extract the intended meaning from your visualisation. -- Just as the reproducibilty of statistical models is important in the context of engaging in open and reproducible science, so too is the reproducibilty of data visualisations. --- # ggplot2 The ggplot2 package is part of the Tidyverse and is based around the Grammar of Graphics (Wickham, 2010): https://byrneslab.net/classes/biol607/readings/wickham_layered-grammar.pdf Start with defining your data and aesthetics of the plot, before adding geometric objects (geoms), information about labelling, faceting etc. Each plot can be built up gradually, layer by layer like the following: --- .top[ <!-- --> ] .bottom[ ```r ggplot(data_long, aes(x = Condition, y = RT)) + geom_jitter(alpha = .25, position = position_jitter(0.05)) ``` ] --- .top[ <!-- --> ] .bottom[ ```r ggplot(data_long, aes(x = Condition, y = RT)) + geom_jitter(alpha = .25, position = position_jitter(0.05)) + stat_summary(fun.data = "mean_cl_boot", colour = "black", size = 1) ``` ] --- .top[ <!-- --> ] .bottom[ ```r ggplot(data_long, aes(x = Condition, y = RT)) + geom_jitter(alpha = .25, position = position_jitter(0.05)) + stat_summary(fun.data = "mean_cl_boot", colour = "black", size = 1) + geom_violin(aes(fill = Condition), alpha = .2) ``` ] --- .top[ <!-- --> ] .bottom[ ```r ggplot(data_long, aes(x = Condition, y = RT)) + geom_jitter(alpha = .25, position = position_jitter(0.05)) + stat_summary(fun.data = "mean_cl_boot", colour = "black", size = 1) + geom_violin(aes(fill = Condition), alpha = .2) + guides(fill = FALSE) ``` ] --- .top[ <!-- --> ] .bottom[ ```r ggplot(data_long, aes(x = Condition, y = RT)) + geom_jitter(alpha = .25, position = position_jitter(0.05)) + stat_summary(fun.data = "mean_cl_boot", colour = "black", size = 1) + geom_violin(aes(fill = Condition), alpha = .2) + guides(fill = FALSE) + coord_flip() ``` ] --- # Violin Plots These are Violin Plots - these are an example of an RDI plot as they capture the Raw data, information about the Distribution, and some Inferential statistics (e.g., Confidence Intervals). We can modify other characteristics of the plot such as the colour palette we're using, the orientation, and we can also add some labels: <!-- --> --- # Building interactive visualisations using the plotly package .center[ <div id="htmlwidget-bdaf8141eae0fc5dbe02" style="width:800px;height:400px;" class="plotly html-widget"></div> <script type="application/json" data-for="htmlwidget-bdaf8141eae0fc5dbe02">{"x":{"data":[{"x":[2111,2112.36203522505,2113.7240704501,2115.08610567515,2116.4481409002,2117.81017612524,2119.17221135029,2120.53424657534,2121.89628180039,2123.25831702544,2124.62035225049,2125.98238747554,2127.34442270059,2128.70645792564,2130.06849315068,2131.43052837573,2132.79256360078,2134.15459882583,2135.51663405088,2136.87866927593,2138.24070450098,2139.60273972603,2140.96477495108,2142.32681017613,2143.68884540117,2145.05088062622,2146.41291585127,2147.77495107632,2149.13698630137,2150.49902152642,2151.86105675147,2153.22309197652,2154.58512720157,2155.94716242661,2157.30919765166,2158.67123287671,2160.03326810176,2161.39530332681,2162.75733855186,2164.11937377691,2165.48140900196,2166.84344422701,2168.20547945205,2169.5675146771,2170.92954990215,2172.2915851272,2173.65362035225,2175.0156555773,2176.37769080235,2177.7397260274,2179.10176125245,2180.4637964775,2181.82583170254,2183.18786692759,2184.54990215264,2185.91193737769,2187.27397260274,2188.63600782779,2189.99804305284,2191.36007827789,2192.72211350294,2194.08414872798,2195.44618395303,2196.80821917808,2198.17025440313,2199.53228962818,2200.89432485323,2202.25636007828,2203.61839530333,2204.98043052838,2206.34246575342,2207.70450097847,2209.06653620352,2210.42857142857,2211.79060665362,2213.15264187867,2214.51467710372,2215.87671232877,2217.23874755382,2218.60078277886,2219.96281800391,2221.32485322896,2222.68688845401,2224.04892367906,2225.41095890411,2226.77299412916,2228.13502935421,2229.49706457926,2230.85909980431,2232.22113502935,2233.5831702544,2234.94520547945,2236.3072407045,2237.66927592955,2239.0313111546,2240.39334637965,2241.7553816047,2243.11741682975,2244.47945205479,2245.84148727984,2247.20352250489,2248.56555772994,2249.92759295499,2251.28962818004,2252.65166340509,2254.01369863014,2255.37573385519,2256.73776908024,2258.09980430528,2259.46183953033,2260.82387475538,2262.18590998043,2263.54794520548,2264.90998043053,2266.27201565558,2267.63405088063,2268.99608610568,2270.35812133072,2271.72015655577,2273.08219178082,2274.44422700587,2275.80626223092,2277.16829745597,2278.53033268102,2279.89236790607,2281.25440313112,2282.61643835616,2283.97847358121,2285.34050880626,2286.70254403131,2288.06457925636,2289.42661448141,2290.78864970646,2292.15068493151,2293.51272015656,2294.8747553816,2296.23679060665,2297.5988258317,2298.96086105675,2300.3228962818,2301.68493150685,2303.0469667319,2304.40900195695,2305.771037182,2307.13307240704,2308.49510763209,2309.85714285714,2311.21917808219,2312.58121330724,2313.94324853229,2315.30528375734,2316.66731898239,2318.02935420744,2319.39138943249,2320.75342465753,2322.11545988258,2323.47749510763,2324.83953033268,2326.20156555773,2327.56360078278,2328.92563600783,2330.28767123288,2331.64970645793,2333.01174168297,2334.37377690802,2335.73581213307,2337.09784735812,2338.45988258317,2339.82191780822,2341.18395303327,2342.54598825832,2343.90802348337,2345.27005870842,2346.63209393346,2347.99412915851,2349.35616438356,2350.71819960861,2352.08023483366,2353.44227005871,2354.80430528376,2356.16634050881,2357.52837573386,2358.8904109589,2360.25244618395,2361.614481409,2362.97651663405,2364.3385518591,2365.70058708415,2367.0626223092,2368.42465753425,2369.7866927593,2371.14872798434,2372.51076320939,2373.87279843444,2375.23483365949,2376.59686888454,2377.95890410959,2379.32093933464,2380.68297455969,2382.04500978474,2383.40704500978,2384.76908023483,2386.13111545988,2387.49315068493,2388.85518590998,2390.21722113503,2391.57925636008,2392.94129158513,2394.30332681018,2395.66536203522,2397.02739726027,2398.38943248532,2399.75146771037,2401.11350293542,2402.47553816047,2403.83757338552,2405.19960861057,2406.56164383562,2407.92367906067,2409.28571428571,2410.64774951076,2412.00978473581,2413.37181996086,2414.73385518591,2416.09589041096,2417.45792563601,2418.81996086106,2420.18199608611,2421.54403131115,2422.9060665362,2424.26810176125,2425.6301369863,2426.99217221135,2428.3542074364,2429.71624266145,2431.0782778865,2432.44031311155,2433.8023483366,2435.16438356164,2436.52641878669,2437.88845401174,2439.25048923679,2440.61252446184,2441.97455968689,2443.33659491194,2444.69863013699,2446.06066536204,2447.42270058708,2448.78473581213,2450.14677103718,2451.50880626223,2452.87084148728,2454.23287671233,2455.59491193738,2456.95694716243,2458.31898238748,2459.68101761252,2461.04305283757,2462.40508806262,2463.76712328767,2465.12915851272,2466.49119373777,2467.85322896282,2469.21526418787,2470.57729941292,2471.93933463796,2473.30136986301,2474.66340508806,2476.02544031311,2477.38747553816,2478.74951076321,2480.11154598826,2481.47358121331,2482.83561643836,2484.1976516634,2485.55968688845,2486.9217221135,2488.28375733855,2489.6457925636,2491.00782778865,2492.3698630137,2493.73189823875,2495.0939334638,2496.45596868885,2497.81800391389,2499.18003913894,2500.54207436399,2501.90410958904,2503.26614481409,2504.62818003914,2505.99021526419,2507.35225048924,2508.71428571429,2510.07632093933,2511.43835616438,2512.80039138943,2514.16242661448,2515.52446183953,2516.88649706458,2518.24853228963,2519.61056751468,2520.97260273973,2522.33463796478,2523.69667318982,2525.05870841487,2526.42074363992,2527.78277886497,2529.14481409002,2530.50684931507,2531.86888454012,2533.23091976517,2534.59295499022,2535.95499021526,2537.31702544031,2538.67906066536,2540.04109589041,2541.40313111546,2542.76516634051,2544.12720156556,2545.48923679061,2546.85127201566,2548.2133072407,2549.57534246575,2550.9373776908,2552.29941291585,2553.6614481409,2555.02348336595,2556.385518591,2557.74755381605,2559.1095890411,2560.47162426614,2561.83365949119,2563.19569471624,2564.55772994129,2565.91976516634,2567.28180039139,2568.64383561644,2570.00587084149,2571.36790606654,2572.72994129158,2574.09197651663,2575.45401174168,2576.81604696673,2578.17808219178,2579.54011741683,2580.90215264188,2582.26418786693,2583.62622309198,2584.98825831703,2586.35029354207,2587.71232876712,2589.07436399217,2590.43639921722,2591.79843444227,2593.16046966732,2594.52250489237,2595.88454011742,2597.24657534247,2598.60861056751,2599.97064579256,2601.33268101761,2602.69471624266,2604.05675146771,2605.41878669276,2606.78082191781,2608.14285714286,2609.50489236791,2610.86692759296,2612.228962818,2613.59099804305,2614.9530332681,2616.31506849315,2617.6771037182,2619.03913894325,2620.4011741683,2621.76320939335,2623.1252446184,2624.48727984344,2625.84931506849,2627.21135029354,2628.57338551859,2629.93542074364,2631.29745596869,2632.65949119374,2634.02152641879,2635.38356164384,2636.74559686888,2638.10763209393,2639.46966731898,2640.83170254403,2642.19373776908,2643.55577299413,2644.91780821918,2646.27984344423,2647.64187866928,2649.00391389432,2650.36594911937,2651.72798434442,2653.09001956947,2654.45205479452,2655.81409001957,2657.17612524462,2658.53816046967,2659.90019569472,2661.26223091976,2662.62426614481,2663.98630136986,2665.34833659491,2666.71037181996,2668.07240704501,2669.43444227006,2670.79647749511,2672.15851272016,2673.52054794521,2674.88258317025,2676.2446183953,2677.60665362035,2678.9686888454,2680.33072407045,2681.6927592955,2683.05479452055,2684.4168297456,2685.77886497065,2687.14090019569,2688.50293542074,2689.86497064579,2691.22700587084,2692.58904109589,2693.95107632094,2695.31311154599,2696.67514677104,2698.03718199609,2699.39921722114,2700.76125244618,2702.12328767123,2703.48532289628,2704.84735812133,2706.20939334638,2707.57142857143,2708.93346379648,2710.29549902153,2711.65753424658,2713.01956947162,2714.38160469667,2715.74363992172,2717.10567514677,2718.46771037182,2719.82974559687,2721.19178082192,2722.55381604697,2723.91585127202,2725.27788649706,2726.63992172211,2728.00195694716,2729.36399217221,2730.72602739726,2732.08806262231,2733.45009784736,2734.81213307241,2736.17416829746,2737.5362035225,2738.89823874755,2740.2602739726,2741.62230919765,2742.9843444227,2744.34637964775,2745.7084148728,2747.07045009785,2748.4324853229,2749.79452054795,2751.15655577299,2752.51859099804,2753.88062622309,2755.24266144814,2756.60469667319,2757.96673189824,2759.32876712329,2760.69080234834,2762.05283757339,2763.41487279843,2764.77690802348,2766.13894324853,2767.50097847358,2768.86301369863,2770.22504892368,2771.58708414873,2772.94911937378,2774.31115459883,2775.67318982387,2777.03522504892,2778.39726027397,2779.75929549902,2781.12133072407,2782.48336594912,2783.84540117417,2785.20743639922,2786.56947162427,2787.93150684932,2789.29354207436,2790.65557729941,2792.01761252446,2793.37964774951,2794.74168297456,2796.10371819961,2797.46575342466,2798.82778864971,2800.18982387476,2801.5518590998,2802.91389432485,2804.2759295499,2805.63796477495,2807,2807,2805.63796477495,2804.2759295499,2802.91389432485,2801.5518590998,2800.18982387476,2798.82778864971,2797.46575342466,2796.10371819961,2794.74168297456,2793.37964774951,2792.01761252446,2790.65557729941,2789.29354207436,2787.93150684932,2786.56947162427,2785.20743639922,2783.84540117417,2782.48336594912,2781.12133072407,2779.75929549902,2778.39726027397,2777.03522504892,2775.67318982387,2774.31115459883,2772.94911937378,2771.58708414873,2770.22504892368,2768.86301369863,2767.50097847358,2766.13894324853,2764.77690802348,2763.41487279843,2762.05283757339,2760.69080234834,2759.32876712329,2757.96673189824,2756.60469667319,2755.24266144814,2753.88062622309,2752.51859099804,2751.15655577299,2749.79452054795,2748.4324853229,2747.07045009785,2745.7084148728,2744.34637964775,2742.9843444227,2741.62230919765,2740.2602739726,2738.89823874755,2737.5362035225,2736.17416829746,2734.81213307241,2733.45009784736,2732.08806262231,2730.72602739726,2729.36399217221,2728.00195694716,2726.63992172211,2725.27788649706,2723.91585127202,2722.55381604697,2721.19178082192,2719.82974559687,2718.46771037182,2717.10567514677,2715.74363992172,2714.38160469667,2713.01956947162,2711.65753424658,2710.29549902153,2708.93346379648,2707.57142857143,2706.20939334638,2704.84735812133,2703.48532289628,2702.12328767123,2700.76125244618,2699.39921722114,2698.03718199609,2696.67514677104,2695.31311154599,2693.95107632094,2692.58904109589,2691.22700587084,2689.86497064579,2688.50293542074,2687.14090019569,2685.77886497065,2684.4168297456,2683.05479452055,2681.6927592955,2680.33072407045,2678.9686888454,2677.60665362035,2676.2446183953,2674.88258317025,2673.52054794521,2672.15851272016,2670.79647749511,2669.43444227006,2668.07240704501,2666.71037181996,2665.34833659491,2663.98630136986,2662.62426614481,2661.26223091976,2659.90019569472,2658.53816046967,2657.17612524462,2655.81409001957,2654.45205479452,2653.09001956947,2651.72798434442,2650.36594911937,2649.00391389432,2647.64187866928,2646.27984344423,2644.91780821918,2643.55577299413,2642.19373776908,2640.83170254403,2639.46966731898,2638.10763209393,2636.74559686888,2635.38356164384,2634.02152641879,2632.65949119374,2631.29745596869,2629.93542074364,2628.57338551859,2627.21135029354,2625.84931506849,2624.48727984344,2623.1252446184,2621.76320939335,2620.4011741683,2619.03913894325,2617.6771037182,2616.31506849315,2614.9530332681,2613.59099804305,2612.228962818,2610.86692759296,2609.50489236791,2608.14285714286,2606.78082191781,2605.41878669276,2604.05675146771,2602.69471624266,2601.33268101761,2599.97064579256,2598.60861056751,2597.24657534247,2595.88454011742,2594.52250489237,2593.16046966732,2591.79843444227,2590.43639921722,2589.07436399217,2587.71232876712,2586.35029354207,2584.98825831703,2583.62622309198,2582.26418786693,2580.90215264188,2579.54011741683,2578.17808219178,2576.81604696673,2575.45401174168,2574.09197651663,2572.72994129158,2571.36790606654,2570.00587084149,2568.64383561644,2567.28180039139,2565.91976516634,2564.55772994129,2563.19569471624,2561.83365949119,2560.47162426614,2559.1095890411,2557.74755381605,2556.385518591,2555.02348336595,2553.6614481409,2552.29941291585,2550.9373776908,2549.57534246575,2548.2133072407,2546.85127201566,2545.48923679061,2544.12720156556,2542.76516634051,2541.40313111546,2540.04109589041,2538.67906066536,2537.31702544031,2535.95499021526,2534.59295499022,2533.23091976517,2531.86888454012,2530.50684931507,2529.14481409002,2527.78277886497,2526.42074363992,2525.05870841487,2523.69667318982,2522.33463796478,2520.97260273973,2519.61056751468,2518.24853228963,2516.88649706458,2515.52446183953,2514.16242661448,2512.80039138943,2511.43835616438,2510.07632093933,2508.71428571429,2507.35225048924,2505.99021526419,2504.62818003914,2503.26614481409,2501.90410958904,2500.54207436399,2499.18003913894,2497.81800391389,2496.45596868885,2495.0939334638,2493.73189823875,2492.3698630137,2491.00782778865,2489.6457925636,2488.28375733855,2486.9217221135,2485.55968688845,2484.1976516634,2482.83561643836,2481.47358121331,2480.11154598826,2478.74951076321,2477.38747553816,2476.02544031311,2474.66340508806,2473.30136986301,2471.93933463796,2470.57729941292,2469.21526418787,2467.85322896282,2466.49119373777,2465.12915851272,2463.76712328767,2462.40508806262,2461.04305283757,2459.68101761252,2458.31898238748,2456.95694716243,2455.59491193738,2454.23287671233,2452.87084148728,2451.50880626223,2450.14677103718,2448.78473581213,2447.42270058708,2446.06066536204,2444.69863013699,2443.33659491194,2441.97455968689,2440.61252446184,2439.25048923679,2437.88845401174,2436.52641878669,2435.16438356164,2433.8023483366,2432.44031311155,2431.0782778865,2429.71624266145,2428.3542074364,2426.99217221135,2425.6301369863,2424.26810176125,2422.9060665362,2421.54403131115,2420.18199608611,2418.81996086106,2417.45792563601,2416.09589041096,2414.73385518591,2413.37181996086,2412.00978473581,2410.64774951076,2409.28571428571,2407.92367906067,2406.56164383562,2405.19960861057,2403.83757338552,2402.47553816047,2401.11350293542,2399.75146771037,2398.38943248532,2397.02739726027,2395.66536203522,2394.30332681018,2392.94129158513,2391.57925636008,2390.21722113503,2388.85518590998,2387.49315068493,2386.13111545988,2384.76908023483,2383.40704500978,2382.04500978474,2380.68297455969,2379.32093933464,2377.95890410959,2376.59686888454,2375.23483365949,2373.87279843444,2372.51076320939,2371.14872798434,2369.7866927593,2368.42465753425,2367.0626223092,2365.70058708415,2364.3385518591,2362.97651663405,2361.614481409,2360.25244618395,2358.8904109589,2357.52837573386,2356.16634050881,2354.80430528376,2353.44227005871,2352.08023483366,2350.71819960861,2349.35616438356,2347.99412915851,2346.63209393346,2345.27005870842,2343.90802348337,2342.54598825832,2341.18395303327,2339.82191780822,2338.45988258317,2337.09784735812,2335.73581213307,2334.37377690802,2333.01174168297,2331.64970645793,2330.28767123288,2328.92563600783,2327.56360078278,2326.20156555773,2324.83953033268,2323.47749510763,2322.11545988258,2320.75342465753,2319.39138943249,2318.02935420744,2316.66731898239,2315.30528375734,2313.94324853229,2312.58121330724,2311.21917808219,2309.85714285714,2308.49510763209,2307.13307240704,2305.771037182,2304.40900195695,2303.0469667319,2301.68493150685,2300.3228962818,2298.96086105675,2297.5988258317,2296.23679060665,2294.8747553816,2293.51272015656,2292.15068493151,2290.78864970646,2289.42661448141,2288.06457925636,2286.70254403131,2285.34050880626,2283.97847358121,2282.61643835616,2281.25440313112,2279.89236790607,2278.53033268102,2277.16829745597,2275.80626223092,2274.44422700587,2273.08219178082,2271.72015655577,2270.35812133072,2268.99608610568,2267.63405088063,2266.27201565558,2264.90998043053,2263.54794520548,2262.18590998043,2260.82387475538,2259.46183953033,2258.09980430528,2256.73776908024,2255.37573385519,2254.01369863014,2252.65166340509,2251.28962818004,2249.92759295499,2248.56555772994,2247.20352250489,2245.84148727984,2244.47945205479,2243.11741682975,2241.7553816047,2240.39334637965,2239.0313111546,2237.66927592955,2236.3072407045,2234.94520547945,2233.5831702544,2232.22113502935,2230.85909980431,2229.49706457926,2228.13502935421,2226.77299412916,2225.41095890411,2224.04892367906,2222.68688845401,2221.32485322896,2219.96281800391,2218.60078277886,2217.23874755382,2215.87671232877,2214.51467710372,2213.15264187867,2211.79060665362,2210.42857142857,2209.06653620352,2207.70450097847,2206.34246575342,2204.98043052838,2203.61839530333,2202.25636007828,2200.89432485323,2199.53228962818,2198.17025440313,2196.80821917808,2195.44618395303,2194.08414872798,2192.72211350294,2191.36007827789,2189.99804305284,2188.63600782779,2187.27397260274,2185.91193737769,2184.54990215264,2183.18786692759,2181.82583170254,2180.4637964775,2179.10176125245,2177.7397260274,2176.37769080235,2175.0156555773,2173.65362035225,2172.2915851272,2170.92954990215,2169.5675146771,2168.20547945205,2166.84344422701,2165.48140900196,2164.11937377691,2162.75733855186,2161.39530332681,2160.03326810176,2158.67123287671,2157.30919765166,2155.94716242661,2154.58512720157,2153.22309197652,2151.86105675147,2150.49902152642,2149.13698630137,2147.77495107632,2146.41291585127,2145.05088062622,2143.68884540117,2142.32681017613,2140.96477495108,2139.60273972603,2138.24070450098,2136.87866927593,2135.51663405088,2134.15459882583,2132.79256360078,2131.43052837573,2130.06849315068,2128.70645792564,2127.34442270059,2125.98238747554,2124.62035225049,2123.25831702544,2121.89628180039,2120.53424657534,2119.17221135029,2117.81017612524,2116.4481409002,2115.08610567515,2113.7240704501,2112.36203522505,2111,2111],"y":[0.946638950166562,0.945385494651154,0.944118406104153,0.942835038861452,0.941528629915625,0.940212697207686,0.938870650564099,0.93751639772944,0.93614576169233,0.934754132268329,0.933353502935714,0.931927652437341,0.930491277477077,0.929038991643781,0.927568279198837,0.926089348698047,0.924587011181514,0.923076021207694,0.921550253949778,0.920009070173248,0.918460706252899,0.916891717737888,0.915316047341504,0.913727433163095,0.912126729886876,0.91051991446535,0.908896591297123,0.907268341993032,0.905629657696475,0.903982358511966,0.902330115225303,0.900666440330483,0.89899937867496,0.897324965096476,0.895645355785654,0.893962375972451,0.892272998365521,0.890581820970798,0.88888676594416,0.887189665238601,0.885491069192718,0.883790741386286,0.882090144897145,0.880389275426237,0.878689037806112,0.876989319495161,0.875291848266462,0.873595471917619,0.871902234524286,0.870211664844956,0.868523557132322,0.86684070960492,0.865160043169732,0.863485376550247,0.861814658161459,0.860148029023313,0.858488502695005,0.856831869552394,0.855183188889446,0.853538938956595,0.851899840319963,0.850268412330044,0.848640142870836,0.84702055728835,0.845405122628395,0.843795110805516,0.842192075227553,0.840591978050444,0.838999850221532,0.837410943017778,0.835826772347168,0.834247754293701,0.832670971437533,0.83109990164255,0.829530647561277,0.827964407840262,0.826400611160878,0.824837910628703,0.823277188983633,0.821716622921942,0.820156349526187,0.818595254054573,0.817033755171404,0.815469295680648,0.813903296588601,0.812334034417518,0.810760513576354,0.809184617840714,0.807600516747527,0.806013127661379,0.804418381808544,0.802816167132664,0.801209240427398,0.79958923885441,0.7979642767606,0.796327739876643,0.794681120882281,0.793027329970041,0.791356529951416,0.789679357278175,0.787986771142074,0.78628239144016,0.784568575010032,0.782835231030336,0.781094540254467,0.779335530918629,0.777564127682034,0.775781586184972,0.773978770529838,0.772168227810185,0.770337951790874,0.768495887026219,0.76664193179038,0.764768927527136,0.762888530796414,0.760988984022286,0.75907943207563,0.757158553437422,0.755221850855022,0.753278880956236,0.751319750485143,0.749353434623916,0.747377981048568,0.74539178637806,0.74340126364524,0.741400240894472,0.739395649156081,0.737385950553638,0.735372155854888,0.733356755040901,0.731339273918552,0.729322326487872,0.727306240480828,0.725293846389851,0.723283265701948,0.72128167484761,0.719284857734407,0.717296762858804,0.715320787316829,0.713350608450235,0.711402829523516,0.709463848467547,0.707543149196166,0.705643091911194,0.703754217459398,0.701900964316678,0.700061005771004,0.698250247906645,0.696468209739952,0.694703789992884,0.692987654473864,0.691289365421309,0.689632085117702,0.688010662558106,0.686414059531392,0.684877172272463,0.683362486791256,0.68190093165219,0.680481018733407,0.679093542788002,0.6777753503171,0.67648329834223,0.675256165012089,0.674074798832407,0.672933483647815,0.671868655878327,0.670833289129545,0.669873619284053,0.668962001447293,0.668097582806966,0.667314153176549,0.666562715548153,0.665896082107731,0.665277897718471,0.664713123021089,0.664230976065534,0.663782431638059,0.663425530125714,0.663115669108394,0.662864045484517,0.662693847142134,0.662557858958452,0.662517595796531,0.662521358781107,0.662586422604226,0.662729063600311,0.662905490922712,0.663178631629371,0.66349147494357,0.663866634927588,0.664313227739073,0.664792179235253,0.6653655856428,0.665973427766623,0.666642398563413,0.667374834583266,0.668137280690453,0.668988728631219,0.669868804956648,0.67080660958672,0.671798646627559,0.672819218822661,0.673917086954214,0.675039302650952,0.676213782334185,0.677432595648701,0.678677849448027,0.679986244884958,0.681314939587405,0.68268867145307,0.684096766769823,0.685528002698903,0.687008002256461,0.688504008189147,0.690036498343507,0.691593856203014,0.693170069351483,0.694781222619498,0.69640407292204,0.698054067993038,0.699720368132426,0.701400561771229,0.703103100959963,0.704813230385288,0.706540978125274,0.708277743557211,0.710023134946383,0.711780032498449,0.713540810644218,0.715310101703986,0.717082606287812,0.718858560621301,0.720637284679557,0.722416733613636,0.72419657306667,0.725975374277018,0.727752924062032,0.729526765802507,0.731298839042572,0.733064626837032,0.7348266160736,0.736583458077439,0.73833234060571,0.740077677050183,0.7418118188088,0.743540722432631,0.745261629638268,0.746972352460755,0.748678463786684,0.750370383319189,0.752056694863949,0.753733332323052,0.755399254120597,0.757060153069935,0.758705730673784,0.760346103767495,0.761976289690744,0.763596500448383,0.765211615006765,0.766812336283183,0.76840851387026,0.769995015448462,0.771573092152017,0.773146285025156,0.774707495586138,0.776264889532874,0.77781388202435,0.779356355923725,0.780894559753277,0.782423593732608,0.783949656161869,0.785468999954037,0.786983684679674,0.788494931104603,0.789999649979952,0.791502191303273,0.792999692669436,0.794494029524823,0.795985740949773,0.797472934568202,0.79895854224392,0.800440358754262,0.801919928073642,0.803397404081062,0.804871419151465,0.806344116296932,0.807813448354034,0.809280775167616,0.810746005672596,0.81220771701532,0.8136679731188,0.815124151378714,0.816577902284619,0.818028804507703,0.819475009212467,0.820919179391513,0.822357217505298,0.823791847041792,0.825221981102495,0.826645255094803,0.828065483394809,0.829476120807951,0.830881983684228,0.832280756447168,0.833669770819724,0.835054350962095,0.836424565838963,0.83778847011363,0.839141793193843,0.840482047911674,0.841816195544797,0.843130127330051,0.844436266676349,0.845727596123728,0.847002494741947,0.84826924505059,0.849509640021379,0.850740813564325,0.851952468788369,0.853144632215887,0.854325815297483,0.855475822029962,0.856614829953725,0.857729469969844,0.85882217168357,0.859900896273477,0.860944533192605,0.861975626448026,0.862977753438689,0.863956353481731,0.864918056515411,0.865842042162375,0.866752305191195,0.867629668486385,0.868482928675053,0.869316719893778,0.870111700817561,0.870892256383291,0.871637043121418,0.872358219917453,0.873057979640068,0.873719495554064,0.874366438945197,0.874976158990769,0.875563791633648,0.876128937790586,0.876658052864609,0.877173046850201,0.877651046668703,0.878109384209236,0.878545253233515,0.878948809920697,0.879339299595578,0.879694870182096,0.880033909690188,0.880351726786398,0.880642207658,0.880921243414871,0.881169318558232,0.881404455756653,0.88162090100306,0.881815912536767,0.882001597721127,0.882162068617186,0.8823133895211,0.882449795068607,0.8825712133528,0.882685818869129,0.882782517489636,0.882873783644302,0.882955022207187,0.883027862589017,0.883096661455584,0.883156097571353,0.883213496886868,0.883266641437893,0.883317731137627,0.883367696202997,0.883417574933925,0.883468323997655,0.883521172156603,0.883577716039335,0.883636549593385,0.883703790602108,0.883774682138751,0.883854245633594,0.883942380256431,0.884036504905518,0.884146330361992,0.884262320968203,0.884393380565374,0.884536810208403,0.884689966967455,0.884864602337879,0.885047530819287,0.885251350426263,0.885470151289539,0.885702185501075,0.88595976357416,0.886227279552014,0.886520560308431,0.886830225958039,0.887156136324135,0.887509870067161,0.88787463672229,0.888268773696904,0.888679557044669,0.889108863347377,0.889566533617051,0.890035748552813,0.890536430396241,0.891053016197286,0.891589477994178,0.892153259698049,0.892728515290903,0.893335682428362,0.893957200959803,0.89459889433723,0.895265520938028,0.895943001809835,0.896651153308325,0.897371522235394,0.898111256451735,0.898872499468567,0.899643491604627,0.900442306643333,0.901250865849113,0.902076898333483,0.902920317470072,0.903771982764926,0.904647201548361,0.905529586587096,0.90642657508825,0.90733647740709,0.908253244807048,0.909187323235852,0.910126508512653,0.911076624730114,0.912035159176631,0.912998764381981,0.913973114028617,0.914950547864976,0.915934668690639,0.916922976090476,0.917914130168612,0.918909797380369,0.919906548350668,0.92090543938522,0.921904778097942,0.922904459486902,0.923903086944422,0.924900924270174,0.925896335425828,0.926889108897226,0.927879613645078,0.92886440313199,0.929846742971424,0.930822347025515,0.931792970790538,0.932758786014365,0.933715277139978,0.934667940326336,0.935610061066033,0.936545622160078,0.937474075416891,0.938390701168949,0.939302445008785,0.940200540586542,0.941091220394713,0.94197287733164,0.942841276120699,0.943704081745393,0.944550969355375,0.945390220109419,0.946219023372043,0.9470341064082,0.947843222308654,0.948635050589404,0.949419534463213,0.95019269670947,0.950952487624349,0.951706247900387,0.95244224198559,0.953171558626092,0.953889240102896,0.954594519370289,0.955293970587742,0.9559759901156,0.95665223228437,0.957317047522729,0.957970846373819,0.958618958309542,0.959251190319186,0.959878377210781,0.960494785064386,0.961101781486928,0.961703267288931,0.962291139555667,0.962874582738551,0.963448218693017,0.964014091349184,0.964574828866827,0.965124267100383,0.965669924696706,0.966206933981491,0.966737728447971,0.967263892607285,0.967780921297129,0.968294792153464,0.968801216978112,0.969302772947719,0.969800251363705,1.03019974863629,1.03069722705228,1.03119878302189,1.03170520784654,1.03221907870287,1.03273610739272,1.03326227155203,1.03379306601851,1.03433007530329,1.03487573289962,1.03542517113317,1.03598590865082,1.03655178130698,1.03712541726145,1.03770886044433,1.03829673271107,1.03889821851307,1.03950521493561,1.04012162278922,1.04074880968081,1.04138104169046,1.04202915362618,1.04268295247727,1.04334776771563,1.0440240098844,1.04470602941226,1.04540548062971,1.0461107598971,1.04682844137391,1.04755775801441,1.04829375209961,1.04904751237565,1.04980730329053,1.05058046553679,1.0513649494106,1.05215677769135,1.0529658935918,1.05378097662796,1.05460977989058,1.05544903064462,1.05629591825461,1.0571587238793,1.05802712266836,1.05890877960529,1.05979945941346,1.06069755499122,1.06160929883105,1.06252592458311,1.06345437783992,1.06438993893397,1.06533205967366,1.06628472286002,1.06724121398564,1.06820702920946,1.06917765297449,1.07015325702858,1.07113559686801,1.07212038635492,1.07311089110277,1.07410366457417,1.07509907572983,1.07609691305558,1.0770955405131,1.07809522190206,1.07909456061478,1.08009345164933,1.08109020261963,1.08208586983139,1.08307702390952,1.08406533130936,1.08504945213502,1.08602688597138,1.08700123561802,1.08796484082337,1.08892337526989,1.08987349148735,1.09081267676415,1.09174675519295,1.09266352259291,1.09357342491175,1.0944704134129,1.09535279845164,1.09622801723507,1.09707968252993,1.09792310166652,1.09874913415089,1.09955769335667,1.10035650839537,1.10112750053143,1.10188874354827,1.10262847776461,1.10334884669167,1.10405699819016,1.10473447906197,1.10540110566277,1.1060427990402,1.10666431757164,1.1072714847091,1.10784674030195,1.10841052200582,1.10894698380271,1.10946356960376,1.10996425144719,1.11043346638295,1.11089113665262,1.11132044295533,1.1117312263031,1.11212536327771,1.11249012993284,1.11284386367586,1.11316977404196,1.11347943969157,1.11377272044799,1.11404023642584,1.11429781449893,1.11452984871046,1.11474864957374,1.11495246918071,1.11513539766212,1.11531003303255,1.1154631897916,1.11560661943463,1.1157376790318,1.11585366963801,1.11596349509448,1.11605761974357,1.11614575436641,1.11622531786125,1.11629620939789,1.11636345040661,1.11642228396066,1.1164788278434,1.11653167600234,1.11658242506608,1.116632303797,1.11668226886237,1.11673335856211,1.11678650311313,1.11684390242865,1.11690333854442,1.11697213741098,1.11704497779281,1.1171262163557,1.11721748251036,1.11731418113087,1.1174287866472,1.11755020493139,1.1176866104789,1.11783793138281,1.11799840227887,1.11818408746323,1.11837909899694,1.11859554424335,1.11883068144177,1.11907875658513,1.119357792342,1.1196482732136,1.11996609030981,1.1203051298179,1.12066070040442,1.1210511900793,1.12145474676648,1.12189061579076,1.1223489533313,1.1228269531498,1.12334194713539,1.12387106220941,1.12443620836635,1.12502384100923,1.1256335610548,1.12628050444594,1.12694202035993,1.12764178008255,1.12836295687858,1.12910774361671,1.12988829918244,1.13068328010622,1.13151707132495,1.13237033151361,1.1332476948088,1.13415795783762,1.13508194348459,1.13604364651827,1.13702224656131,1.13802437355197,1.1390554668074,1.14009910372652,1.14117782831643,1.14227053003016,1.14338517004628,1.14452417797004,1.14567418470252,1.14685536778411,1.14804753121163,1.14925918643567,1.15049035997862,1.15173075494941,1.15299750525805,1.15427240387627,1.15556373332365,1.15686987266995,1.1581838044552,1.15951795208833,1.16085820680616,1.16221152988637,1.16357543416104,1.1649456490379,1.16633022918028,1.16771924355283,1.16911801631577,1.17052387919205,1.17193451660519,1.1733547449052,1.1747780188975,1.17620815295821,1.1776427824947,1.17908082060849,1.18052499078753,1.1819711954923,1.18342209771538,1.18487584862129,1.1863320268812,1.18779228298468,1.1892539943274,1.19071922483238,1.19218655164597,1.19365588370307,1.19512858084854,1.19660259591894,1.19808007192636,1.19955964124574,1.20104145775608,1.2025270654318,1.20401425905023,1.20550597047518,1.20700030733056,1.20849780869673,1.21000035002005,1.2115050688954,1.21301631532033,1.21453100004596,1.21605034383813,1.21757640626739,1.21910544024672,1.22064364407628,1.22218611797565,1.22373511046713,1.22529250441386,1.22685371497484,1.22842690784798,1.23000498455154,1.23159148612974,1.23318766371682,1.23478838499324,1.23640349955162,1.23802371030926,1.23965389623251,1.24129426932622,1.24293984693006,1.2446007458794,1.24626666767695,1.24794330513605,1.24962961668081,1.25132153621332,1.25302764753925,1.25473837036173,1.25645927756737,1.2581881811912,1.25992232294982,1.26166765939429,1.26341654192256,1.2651733839264,1.26693537316297,1.26870116095743,1.27047323419749,1.27224707593797,1.27402462572298,1.27580342693333,1.27758326638636,1.27936271532044,1.2811414393787,1.28291739371219,1.28468989829601,1.28645918935578,1.28821996750155,1.28997686505362,1.29172225644279,1.29345902187473,1.29518676961471,1.29689689904004,1.29859943822877,1.30027963186757,1.30194593200696,1.30359592707796,1.3052187773805,1.30682993064852,1.30840614379699,1.30996350165649,1.31149599181085,1.31299199774354,1.3144719973011,1.31590323323018,1.31731132854693,1.3186850604126,1.32001375511504,1.32132215055197,1.3225674043513,1.32378621766582,1.32496069734905,1.32608291304579,1.32718078117734,1.32820135337244,1.32919339041328,1.33013119504335,1.33101127136878,1.33186271930955,1.33262516541673,1.33335760143659,1.33402657223338,1.3346344143572,1.33520782076475,1.33568677226093,1.33613336507241,1.33650852505643,1.33682136837063,1.33709450907729,1.33727093639969,1.33741357739577,1.33747864121889,1.33748240420347,1.33744214104155,1.33730615285787,1.33713595451548,1.33688433089161,1.33657446987429,1.33621756836194,1.33576902393447,1.33528687697891,1.33472210228153,1.33410391789227,1.33343728445185,1.33268584682345,1.33190241719303,1.33103799855271,1.33012638071595,1.32916671087046,1.32813134412167,1.32706651635219,1.32592520116759,1.32474383498791,1.32351670165777,1.3222246496829,1.320906457212,1.31951898126659,1.31809906834781,1.31663751320874,1.31512282772754,1.31358594046861,1.31198933744189,1.3103679148823,1.30871063457869,1.30701234552614,1.30529621000712,1.30353179026005,1.30174975209336,1.299938994229,1.29809903568332,1.2962457825406,1.29435690808881,1.29245685080383,1.29053615153245,1.28859717047648,1.28664939154976,1.28467921268317,1.2827032371412,1.28071514226559,1.27871832515239,1.27671673429805,1.27470615361015,1.27269375951917,1.27067767351213,1.26866072608145,1.2666432449591,1.26462784414511,1.26261404944636,1.26060435084392,1.25859975910553,1.25659873635476,1.25460821362194,1.25262201895143,1.25064656537608,1.24868024951486,1.24672111904376,1.24477814914498,1.24284144656258,1.24092056792437,1.23901101597771,1.23711146920359,1.23523107247286,1.23335806820962,1.23150411297378,1.22966204820913,1.22783177218981,1.22602122947016,1.22421841381503,1.22243587231797,1.22066446908137,1.21890545974553,1.21716476896966,1.21543142498997,1.21371760855984,1.21201322885793,1.21032064272182,1.20864347004858,1.20697267002996,1.20531887911772,1.20367226012336,1.2020357232394,1.20041076114559,1.1987907595726,1.19718383286734,1.19558161819146,1.19398687233862,1.19239948325247,1.19081538215929,1.18923948642365,1.18766596558248,1.1860967034114,1.18453070431935,1.1829662448286,1.18140474594543,1.17984365047381,1.17828337707806,1.17672281101637,1.1751620893713,1.17359938883912,1.17203559215974,1.17046935243872,1.16890009835745,1.16732902856247,1.1657522457063,1.16417322765283,1.16258905698222,1.16100014977847,1.15940802194956,1.15780792477245,1.15620488919448,1.1545948773716,1.15297944271165,1.15135985712916,1.14973158766996,1.14810015968004,1.14646106104341,1.14481681111055,1.14316813044761,1.14151149730499,1.13985197097669,1.13818534183854,1.13651462344975,1.13483995683027,1.13315929039508,1.13147644286768,1.12978833515504,1.12809776547571,1.12640452808238,1.12470815173354,1.12301068050484,1.12131096219389,1.11961072457376,1.11790985510286,1.11620925861371,1.11450893080728,1.1128103347614,1.11111323405584,1.1094181790292,1.10772700163448,1.10603762402755,1.10435464421435,1.10267503490352,1.10100062132504,1.09933355966952,1.0976698847747,1.09601764148803,1.09437034230352,1.09273165800697,1.09110340870288,1.08948008553465,1.08787327011312,1.0862725668369,1.0846839526585,1.08310828226211,1.0815392937471,1.07999092982675,1.07844974605022,1.07692397879231,1.07541298881849,1.07391065130195,1.07243172080116,1.07096100835622,1.06950872252292,1.06807234756266,1.06664649706429,1.06524586773167,1.06385423830767,1.06248360227056,1.0611293494359,1.05978730279231,1.05847137008437,1.05716496113855,1.05588159389585,1.05461450534885,1.05336104983344,0.946638950166562],"text":["Condition: Complex<br />Condition: Complex<br />RT: 2111.000<br />density: 0.0004288382","Condition: Complex<br />Condition: Complex<br />RT: 2112.362<br />density: 0.0004389116","Condition: Complex<br />Condition: Complex<br />RT: 2113.724<br />density: 0.0004490946","Condition: Complex<br />Condition: Complex<br />RT: 2115.086<br />density: 0.0004594085","Condition: Complex<br />Condition: Complex<br />RT: 2116.448<br />density: 0.0004699075","Condition: Complex<br />Condition: Complex<br />RT: 2117.810<br />density: 0.0004804830","Condition: Complex<br />Condition: Complex<br />RT: 2119.172<br />density: 0.0004912684","Condition: Complex<br />Condition: Complex<br />RT: 2120.534<br />density: 0.0005021519","Condition: Complex<br />Condition: Complex<br />RT: 2121.896<br />density: 0.0005131671","Condition: Complex<br />Condition: Complex<br />RT: 2123.258<br />density: 0.0005243510","Condition: Complex<br />Condition: Complex<br />RT: 2124.620<br />density: 0.0005356072","Condition: Complex<br />Condition: Complex<br />RT: 2125.982<br />density: 0.0005470661","Condition: Complex<br />Condition: Complex<br />RT: 2127.344<br />density: 0.0005586096","Condition: Complex<br />Condition: Complex<br />RT: 2128.706<br />density: 0.0005702809","Condition: Complex<br />Condition: Complex<br />RT: 2130.068<br />density: 0.0005821004","Condition: Complex<br />Condition: Complex<br />RT: 2131.431<br />density: 0.0005939859","Condition: Complex<br />Condition: Complex<br />RT: 2132.793<br />density: 0.0006060595","Condition: Complex<br />Condition: Complex<br />RT: 2134.155<br />density: 0.0006182026","Condition: Complex<br />Condition: Complex<br />RT: 2135.517<br />density: 0.0006304645","Condition: Complex<br />Condition: Complex<br />RT: 2136.879<br />density: 0.0006428503","Condition: Complex<br />Condition: Complex<br />RT: 2138.241<br />density: 0.0006552938","Condition: Complex<br />Condition: Complex<br />RT: 2139.603<br />density: 0.0006679030","Condition: Complex<br />Condition: Complex<br />RT: 2140.965<br />density: 0.0006805659","Condition: Complex<br />Condition: Complex<br />RT: 2142.327<br />density: 0.0006933329","Condition: Complex<br />Condition: Complex<br />RT: 2143.689<br />density: 0.0007061970","Condition: Complex<br />Condition: Complex<br />RT: 2145.051<br />density: 0.0007191102","Condition: Complex<br />Condition: Complex<br />RT: 2146.413<br />density: 0.0007321561","Condition: Complex<br />Condition: Complex<br />RT: 2147.775<br />density: 0.0007452416","Condition: Complex<br />Condition: Complex<br />RT: 2149.137<br />density: 0.0007584110","Condition: Complex<br />Condition: Complex<br />RT: 2150.499<br />density: 0.0007716496","Condition: Complex<br />Condition: Complex<br />RT: 2151.861<br />density: 0.0007849279","Condition: Complex<br />Condition: Complex<br />RT: 2153.223<br />density: 0.0007982981","Condition: Complex<br />Condition: Complex<br />RT: 2154.585<br />density: 0.0008116955","Condition: Complex<br />Condition: Complex<br />RT: 2155.947<br />density: 0.0008251520","Condition: Complex<br />Condition: Complex<br />RT: 2157.309<br />density: 0.0008386502","Condition: Complex<br />Condition: Complex<br />RT: 2158.671<br />density: 0.0008521756","Condition: Complex<br />Condition: Complex<br />RT: 2160.033<br />density: 0.0008657523","Condition: Complex<br />Condition: Complex<br />RT: 2161.395<br />density: 0.0008793435","Condition: Complex<br />Condition: Complex<br />RT: 2162.757<br />density: 0.0008929659","Condition: Complex<br />Condition: Complex<br />RT: 2164.119<br />density: 0.0009066047","Condition: Complex<br />Condition: Complex<br />RT: 2165.481<br />density: 0.0009202555","Condition: Complex<br />Condition: Complex<br />RT: 2166.843<br />density: 0.0009339203","Condition: Complex<br />Condition: Complex<br />RT: 2168.205<br />density: 0.0009475872","Condition: Complex<br />Condition: Complex<br />RT: 2169.568<br />density: 0.0009612563","Condition: Complex<br />Condition: Complex<br />RT: 2170.930<br />density: 0.0009749203","Condition: Complex<br />Condition: Complex<br />RT: 2172.292<br />density: 0.0009885802","Condition: Complex<br />Condition: Complex<br />RT: 2173.654<br />density: 0.0010022220","Condition: Complex<br />Condition: Complex<br />RT: 2175.016<br />density: 0.0010158550","Condition: Complex<br />Condition: Complex<br />RT: 2176.378<br />density: 0.0010294628","Condition: Complex<br />Condition: Complex<br />RT: 2177.740<br />density: 0.0010430491","Condition: Complex<br />Condition: Complex<br />RT: 2179.102<br />density: 0.0010566156","Condition: Complex<br />Condition: Complex<br />RT: 2180.464<br />density: 0.0010701399","Condition: Complex<br />Condition: Complex<br />RT: 2181.826<br />density: 0.0010836466","Condition: Complex<br />Condition: Complex<br />RT: 2183.188<br />density: 0.0010971052","Condition: Complex<br />Condition: Complex<br />RT: 2184.550<br />density: 0.0011105320","Condition: Complex<br />Condition: Complex<br />RT: 2185.912<br />density: 0.0011239259","Condition: Complex<br />Condition: Complex<br />RT: 2187.274<br />density: 0.0011372627","Condition: Complex<br />Condition: Complex<br />RT: 2188.636<br />density: 0.0011505763","Condition: Complex<br />Condition: Complex<br />RT: 2189.998<br />density: 0.0011638260","Condition: Complex<br />Condition: Complex<br />RT: 2191.360<br />density: 0.0011770401","Condition: Complex<br />Condition: Complex<br />RT: 2192.722<br />density: 0.0011902128","Condition: Complex<br />Condition: Complex<br />RT: 2194.084<br />density: 0.0012033238","Condition: Complex<br />Condition: Complex<br />RT: 2195.446<br />density: 0.0012164095","Condition: Complex<br />Condition: Complex<br />RT: 2196.808<br />density: 0.0012294253","Condition: Complex<br />Condition: Complex<br />RT: 2198.170<br />density: 0.0012424078","Condition: Complex<br />Condition: Complex<br />RT: 2199.532<br />density: 0.0012553468","Condition: Complex<br />Condition: Complex<br />RT: 2200.894<br />density: 0.0012682296","Condition: Complex<br />Condition: Complex<br />RT: 2202.256<br />density: 0.0012810889","Condition: Complex<br />Condition: Complex<br />RT: 2203.618<br />density: 0.0012938841","Condition: Complex<br />Condition: Complex<br />RT: 2204.980<br />density: 0.0013066534","Condition: Complex<br />Condition: Complex<br />RT: 2206.342<br />density: 0.0013193846","Condition: Complex<br />Condition: Complex<br />RT: 2207.705<br />density: 0.0013320745","Condition: Complex<br />Condition: Complex<br />RT: 2209.067<br />density: 0.0013447463","Condition: Complex<br />Condition: Complex<br />RT: 2210.429<br />density: 0.0013573723","Condition: Complex<br />Condition: Complex<br />RT: 2211.791<br />density: 0.0013699837","Condition: Complex<br />Condition: Complex<br />RT: 2213.153<br />density: 0.0013825708","Condition: Complex<br />Condition: Complex<br />RT: 2214.515<br />density: 0.0013951383","Condition: Complex<br />Condition: Complex<br />RT: 2215.877<br />density: 0.0014076970","Condition: Complex<br />Condition: Complex<br />RT: 2217.239<br />density: 0.0014202399","Condition: Complex<br />Condition: Complex<br />RT: 2218.601<br />density: 0.0014327814","Condition: Complex<br />Condition: Complex<br />RT: 2219.963<br />density: 0.0014453206","Condition: Complex<br />Condition: Complex<br />RT: 2221.325<br />density: 0.0014578664","Condition: Complex<br />Condition: Complex<br />RT: 2222.687<br />density: 0.0014704155","Condition: Complex<br />Condition: Complex<br />RT: 2224.049<br />density: 0.0014829883","Condition: Complex<br />Condition: Complex<br />RT: 2225.411<br />density: 0.0014955735","Condition: Complex<br />Condition: Complex<br />RT: 2226.773<br />density: 0.0015081849","Condition: Complex<br />Condition: Complex<br />RT: 2228.135<br />density: 0.0015208306","Condition: Complex<br />Condition: Complex<br />RT: 2229.497<br />density: 0.0015334954","Condition: Complex<br />Condition: Complex<br />RT: 2230.859<br />density: 0.0015462260","Condition: Complex<br />Condition: Complex<br />RT: 2232.221<br />density: 0.0015589832","Condition: Complex<br />Condition: Complex<br />RT: 2233.583<br />density: 0.0015717994","Condition: Complex<br />Condition: Complex<br />RT: 2234.945<br />density: 0.0015846757","Condition: Complex<br />Condition: Complex<br />RT: 2236.307<br />density: 0.0015975898","Condition: Complex<br />Condition: Complex<br />RT: 2237.669<br />density: 0.0016106090","Condition: Complex<br />Condition: Complex<br />RT: 2239.031<br />density: 0.0016236681","Condition: Complex<br />Condition: Complex<br />RT: 2240.393<br />density: 0.0016368202","Condition: Complex<br />Condition: Complex<br />RT: 2241.755<br />density: 0.0016500533","Condition: Complex<br />Condition: Complex<br />RT: 2243.117<br />density: 0.0016633440","Condition: Complex<br />Condition: Complex<br />RT: 2244.479<br />density: 0.0016767715","Condition: Complex<br />Condition: Complex<br />RT: 2245.841<br />density: 0.0016902502","Condition: Complex<br />Condition: Complex<br />RT: 2247.204<br />density: 0.0017038527","Condition: Complex<br />Condition: Complex<br />RT: 2248.566<br />density: 0.0017175500","Condition: Complex<br />Condition: Complex<br />RT: 2249.928<br />density: 0.0017313232","Condition: Complex<br />Condition: Complex<br />RT: 2251.290<br />density: 0.0017452532","Condition: Complex<br />Condition: Complex<br />RT: 2252.652<br />density: 0.0017592424","Condition: Complex<br />Condition: Complex<br />RT: 2254.014<br />density: 0.0017733787","Condition: Complex<br />Condition: Complex<br />RT: 2255.376<br />density: 0.0017876147","Condition: Complex<br />Condition: Complex<br />RT: 2256.738<br />density: 0.0018019401","Condition: Complex<br />Condition: Complex<br />RT: 2258.100<br />density: 0.0018164285","Condition: Complex<br />Condition: Complex<br />RT: 2259.462<br />density: 0.0018309790","Condition: Complex<br />Condition: Complex<br />RT: 2260.824<br />density: 0.0018456881","Condition: Complex<br />Condition: Complex<br />RT: 2262.186<br />density: 0.0018604919","Condition: Complex<br />Condition: Complex<br />RT: 2263.548<br />density: 0.0018753913","Condition: Complex<br />Condition: Complex<br />RT: 2264.910<br />density: 0.0018904438","Condition: Complex<br />Condition: Complex<br />RT: 2266.272<br />density: 0.0019055557","Condition: Complex<br />Condition: Complex<br />RT: 2267.634<br />density: 0.0019208215","Condition: Complex<br />Condition: Complex<br />RT: 2268.996<br />density: 0.0019361677","Condition: Complex<br />Condition: Complex<br />RT: 2270.358<br />density: 0.0019516049","Condition: Complex<br />Condition: Complex<br />RT: 2271.720<br />density: 0.0019671693","Condition: Complex<br />Condition: Complex<br />RT: 2273.082<br />density: 0.0019827840","Condition: Complex<br />Condition: Complex<br />RT: 2274.444<br />density: 0.0019985286","Condition: Complex<br />Condition: Complex<br />RT: 2275.806<br />density: 0.0020143310","Condition: Complex<br />Condition: Complex<br />RT: 2277.168<br />density: 0.0020302068","Condition: Complex<br />Condition: Complex<br />RT: 2278.530<br />density: 0.0020461690","Condition: Complex<br />Condition: Complex<br />RT: 2279.892<br />density: 0.0020621659","Condition: Complex<br />Condition: Complex<br />RT: 2281.254<br />density: 0.0020782472","Condition: Complex<br />Condition: Complex<br />RT: 2282.616<br />density: 0.0020943572","Condition: Complex<br />Condition: Complex<br />RT: 2283.978<br />density: 0.0021105082","Condition: Complex<br />Condition: Complex<br />RT: 2285.341<br />density: 0.0021266921","Condition: Complex<br />Condition: Complex<br />RT: 2286.703<br />density: 0.0021428890","Condition: Complex<br />Condition: Complex<br />RT: 2288.065<br />density: 0.0021591025","Condition: Complex<br />Condition: Complex<br />RT: 2289.427<br />density: 0.0021753118","Condition: Complex<br />Condition: Complex<br />RT: 2290.789<br />density: 0.0021915142","Condition: Complex<br />Condition: Complex<br />RT: 2292.151<br />density: 0.0022076869","Condition: Complex<br />Condition: Complex<br />RT: 2293.513<br />density: 0.0022238450","Condition: Complex<br />Condition: Complex<br />RT: 2294.875<br />density: 0.0022399308","Condition: Complex<br />Condition: Complex<br />RT: 2296.237<br />density: 0.0022559783","Condition: Complex<br />Condition: Complex<br />RT: 2297.599<br />density: 0.0022719557","Condition: Complex<br />Condition: Complex<br />RT: 2298.961<br />density: 0.0022878357","Condition: Complex<br />Condition: Complex<br />RT: 2300.323<br />density: 0.0023036692","Condition: Complex<br />Condition: Complex<br />RT: 2301.685<br />density: 0.0023193226","Condition: Complex<br />Condition: Complex<br />RT: 2303.047<br />density: 0.0023349053","Condition: Complex<br />Condition: Complex<br />RT: 2304.409<br />density: 0.0023503410","Condition: Complex<br />Condition: Complex<br />RT: 2305.771<br />density: 0.0023656109","Condition: Complex<br />Condition: Complex<br />RT: 2307.133<br />density: 0.0023807909","Condition: Complex<br />Condition: Complex<br />RT: 2308.495<br />density: 0.0023956847","Condition: Complex<br />Condition: Complex<br />RT: 2309.857<br />density: 0.0024104716","Condition: Complex<br />Condition: Complex<br />RT: 2311.219<br />density: 0.0024250238","Condition: Complex<br />Condition: Complex<br />RT: 2312.581<br />density: 0.0024393452","Condition: Complex<br />Condition: Complex<br />RT: 2313.943<br />density: 0.0024535250","Condition: Complex<br />Condition: Complex<br />RT: 2315.305<br />density: 0.0024673168","Condition: Complex<br />Condition: Complex<br />RT: 2316.667<br />density: 0.0024809652","Condition: Complex<br />Condition: Complex<br />RT: 2318.029<br />density: 0.0024942840","Condition: Complex<br />Condition: Complex<br />RT: 2319.391<br />density: 0.0025073146","Condition: Complex<br />Condition: Complex<br />RT: 2320.753<br />density: 0.0025201458","Condition: Complex<br />Condition: Complex<br />RT: 2322.115<br />density: 0.0025324971","Condition: Complex<br />Condition: Complex<br />RT: 2323.477<br />density: 0.0025446699","Condition: Complex<br />Condition: Complex<br />RT: 2324.840<br />density: 0.0025564157","Condition: Complex<br />Condition: Complex<br />RT: 2326.202<br />density: 0.0025678269","Condition: Complex<br />Condition: Complex<br />RT: 2327.564<br />density: 0.0025789774","Condition: Complex<br />Condition: Complex<br />RT: 2328.926<br />density: 0.0025895711","Condition: Complex<br />Condition: Complex<br />RT: 2330.288<br />density: 0.0025999548","Condition: Complex<br />Condition: Complex<br />RT: 2331.650<br />density: 0.0026098167","Condition: Complex<br />Condition: Complex<br />RT: 2333.012<br />density: 0.0026193108","Condition: Complex<br />Condition: Complex<br />RT: 2334.374<br />density: 0.0026284830","Condition: Complex<br />Condition: Complex<br />RT: 2335.736<br />density: 0.0026370405","Condition: Complex<br />Condition: Complex<br />RT: 2337.098<br />density: 0.0026453613","Condition: Complex<br />Condition: Complex<br />RT: 2338.460<br />density: 0.0026530737","Condition: Complex<br />Condition: Complex<br />RT: 2339.822<br />density: 0.0026603999","Condition: Complex<br />Condition: Complex<br />RT: 2341.184<br />density: 0.0026673469","Condition: Complex<br />Condition: Complex<br />RT: 2342.546<br />density: 0.0026736429","Condition: Complex<br />Condition: Complex<br />RT: 2343.908<br />density: 0.0026796819","Condition: Complex<br />Condition: Complex<br />RT: 2345.270<br />density: 0.0026850393","Condition: Complex<br />Condition: Complex<br />RT: 2346.632<br />density: 0.0026900074","Condition: Complex<br />Condition: Complex<br />RT: 2347.994<br />density: 0.0026945462","Condition: Complex<br />Condition: Complex<br />RT: 2349.356<br />density: 0.0026984210","Condition: Complex<br />Condition: Complex<br />RT: 2350.718<br />density: 0.0027020258","Condition: Complex<br />Condition: Complex<br />RT: 2352.080<br />density: 0.0027048940","Condition: Complex<br />Condition: Complex<br />RT: 2353.442<br />density: 0.0027073842","Condition: Complex<br />Condition: Complex<br />RT: 2354.804<br />density: 0.0027094064","Condition: Complex<br />Condition: Complex<br />RT: 2356.166<br />density: 0.0027107742","Condition: Complex<br />Condition: Complex<br />RT: 2357.528<br />density: 0.0027118671","Condition: Complex<br />Condition: Complex<br />RT: 2358.890<br />density: 0.0027121907","Condition: Complex<br />Condition: Complex<br />RT: 2360.252<br />density: 0.0027121604","Condition: Complex<br />Condition: Complex<br />RT: 2361.614<br />density: 0.0027116375","Condition: Complex<br />Condition: Complex<br />RT: 2362.977<br />density: 0.0027104912","Condition: Complex<br />Condition: Complex<br />RT: 2364.339<br />density: 0.0027090733","Condition: Complex<br />Condition: Complex<br />RT: 2365.701<br />density: 0.0027068782","Condition: Complex<br />Condition: Complex<br />RT: 2367.063<br />density: 0.0027043641","Condition: Complex<br />Condition: Complex<br />RT: 2368.425<br />density: 0.0027013491","Condition: Complex<br />Condition: Complex<br />RT: 2369.787<br />density: 0.0026977600","Condition: Complex<br />Condition: Complex<br />RT: 2371.149<br />density: 0.0026939109","Condition: Complex<br />Condition: Complex<br />RT: 2372.511<br />density: 0.0026893027","Condition: Complex<br />Condition: Complex<br />RT: 2373.873<br />density: 0.0026844177","Condition: Complex<br />Condition: Complex<br />RT: 2375.235<br />density: 0.0026790415","Condition: Complex<br />Condition: Complex<br />RT: 2376.597<br />density: 0.0026731553","Condition: Complex<br />Condition: Complex<br />RT: 2377.959<br />density: 0.0026670279","Condition: Complex<br />Condition: Complex<br />RT: 2379.321<br />density: 0.0026601852","Condition: Complex<br />Condition: Complex<br />RT: 2380.683<br />density: 0.0026531124","Condition: Complex<br />Condition: Complex<br />RT: 2382.045<br />density: 0.0026455757","Condition: Complex<br />Condition: Complex<br />RT: 2383.407<br />density: 0.0026376031","Condition: Complex<br />Condition: Complex<br />RT: 2384.769<br />density: 0.0026294013","Condition: Complex<br />Condition: Complex<br />RT: 2386.131<br />density: 0.0026205782","Condition: Complex<br />Condition: Complex<br />RT: 2387.493<br />density: 0.0026115595","Condition: Complex<br />Condition: Complex<br />RT: 2388.855<br />density: 0.0026021207","Condition: Complex<br />Condition: Complex<br />RT: 2390.217<br />density: 0.0025923257","Condition: Complex<br />Condition: Complex<br />RT: 2391.579<br />density: 0.0025823182","Condition: Complex<br />Condition: Complex<br />RT: 2392.941<br />density: 0.0025718032","Condition: Complex<br />Condition: Complex<br />RT: 2394.303<br />density: 0.0025611251","Condition: Complex<br />Condition: Complex<br />RT: 2395.665<br />density: 0.0025500850","Condition: Complex<br />Condition: Complex<br />RT: 2397.027<br />density: 0.0025387688","Condition: Complex<br />Condition: Complex<br />RT: 2398.389<br />density: 0.0025272666","Condition: Complex<br />Condition: Complex<br />RT: 2399.751<br />density: 0.0025153726","Condition: Complex<br />Condition: Complex<br />RT: 2401.114<br />density: 0.0025033498","Condition: Complex<br />Condition: Complex<br />RT: 2402.476<br />density: 0.0024910339","Condition: Complex<br />Condition: Complex<br />RT: 2403.838<br />density: 0.0024785182","Condition: Complex<br />Condition: Complex<br />RT: 2405.200<br />density: 0.0024658509","Condition: Complex<br />Condition: Complex<br />RT: 2406.562<br />density: 0.0024529028","Condition: Complex<br />Condition: Complex<br />RT: 2407.924<br />density: 0.0024398607","Condition: Complex<br />Condition: Complex<br />RT: 2409.286<br />density: 0.0024266004","Condition: Complex<br />Condition: Complex<br />RT: 2410.648<br />density: 0.0024132091","Condition: Complex<br />Condition: Complex<br />RT: 2412.010<br />density: 0.0023997062","Condition: Complex<br />Condition: Complex<br />RT: 2413.372<br />density: 0.0023860237","Condition: Complex<br />Condition: Complex<br />RT: 2414.734<br />density: 0.0023722801","Condition: Complex<br />Condition: Complex<br />RT: 2416.096<br />density: 0.0023583950","Condition: Complex<br />Condition: Complex<br />RT: 2417.458<br />density: 0.0023444374","Condition: Complex<br />Condition: Complex<br />RT: 2418.820<br />density: 0.0023304105","Condition: Complex<br />Condition: Complex<br />RT: 2420.182<br />density: 0.0023162912","Condition: Complex<br />Condition: Complex<br />RT: 2421.544<br />density: 0.0023021406","Condition: Complex<br />Condition: Complex<br />RT: 2422.906<br />density: 0.0022879216","Condition: Complex<br />Condition: Complex<br />RT: 2424.268<br />density: 0.0022736768","Condition: Complex<br />Condition: Complex<br />RT: 2425.630<br />density: 0.0022594043","Condition: Complex<br />Condition: Complex<br />RT: 2426.992<br />density: 0.0022451095","Condition: Complex<br />Condition: Complex<br />RT: 2428.354<br />density: 0.0022308089","Condition: Complex<br />Condition: Complex<br />RT: 2429.716<br />density: 0.0022165051","Condition: Complex<br />Condition: Complex<br />RT: 2431.078<br />density: 0.0022022097","Condition: Complex<br />Condition: Complex<br />RT: 2432.440<br />density: 0.0021879244","Condition: Complex<br />Condition: Complex<br />RT: 2433.802<br />density: 0.0021736688","Condition: Complex<br />Condition: Complex<br />RT: 2435.164<br />density: 0.0021594275","Condition: Complex<br />Condition: Complex<br />RT: 2436.526<br />density: 0.0021452367","Condition: Complex<br />Condition: Complex<br />RT: 2437.888<br />density: 0.0021310764","Condition: Complex<br />Condition: Complex<br />RT: 2439.250<br />density: 0.0021169574","Condition: Complex<br />Condition: Complex<br />RT: 2440.613<br />density: 0.0021029025","Condition: Complex<br />Condition: Complex<br />RT: 2441.975<br />density: 0.0020888760","Condition: Complex<br />Condition: Complex<br />RT: 2443.337<br />density: 0.0020749395","Condition: Complex<br />Condition: Complex<br />RT: 2444.699<br />density: 0.0020610451","Condition: Complex<br />Condition: Complex<br />RT: 2446.061<br />density: 0.0020472150","Condition: Complex<br />Condition: Complex<br />RT: 2447.423<br />density: 0.0020334667","Condition: Complex<br />Condition: Complex<br />RT: 2448.785<br />density: 0.0020197555","Condition: Complex<br />Condition: Complex<br />RT: 2450.147<br />density: 0.0020061583","Condition: Complex<br />Condition: Complex<br />RT: 2451.509<br />density: 0.0019926062","Condition: Complex<br />Condition: Complex<br />RT: 2452.871<br />density: 0.0019791318","Condition: Complex<br />Condition: Complex<br />RT: 2454.233<br />density: 0.0019657436","Condition: Complex<br />Condition: Complex<br />RT: 2455.595<br />density: 0.0019523957","Condition: Complex<br />Condition: Complex<br />RT: 2456.957<br />density: 0.0019391709","Condition: Complex<br />Condition: Complex<br />RT: 2458.319<br />density: 0.0019259880","Condition: Complex<br />Condition: Complex<br />RT: 2459.681<br />density: 0.0019128869","Condition: Complex<br />Condition: Complex<br />RT: 2461.043<br />density: 0.0018998661","Condition: Complex<br />Condition: Complex<br />RT: 2462.405<br />density: 0.0018868861","Condition: Complex<br />Condition: Complex<br />RT: 2463.767<br />density: 0.0018740219","Condition: Complex<br />Condition: Complex<br />RT: 2465.129<br />density: 0.0018611941","Condition: Complex<br />Condition: Complex<br />RT: 2466.491<br />density: 0.0018484441","Condition: Complex<br />Condition: Complex<br />RT: 2467.853<br />density: 0.0018357619","Condition: Complex<br />Condition: Complex<br />RT: 2469.215<br />density: 0.0018231188","Condition: Complex<br />Condition: Complex<br />RT: 2470.577<br />density: 0.0018105721","Condition: Complex<br />Condition: Complex<br />RT: 2471.939<br />density: 0.0017980561","Condition: Complex<br />Condition: Complex<br />RT: 2473.301<br />density: 0.0017856075","Condition: Complex<br />Condition: Complex<br />RT: 2474.663<br />density: 0.0017732114","Condition: Complex<br />Condition: Complex<br />RT: 2476.025<br />density: 0.0017608495","Condition: Complex<br />Condition: Complex<br />RT: 2477.387<br />density: 0.0017485614","Condition: Complex<br />Condition: Complex<br />RT: 2478.750<br />density: 0.0017362971","Condition: Complex<br />Condition: Complex<br />RT: 2480.112<br />density: 0.0017240869","Condition: Complex<br />Condition: Complex<br />RT: 2481.474<br />density: 0.0017119140","Condition: Complex<br />Condition: Complex<br />RT: 2482.836<br />density: 0.0016997688","Condition: Complex<br />Condition: Complex<br />RT: 2484.198<br />density: 0.0016876761","Condition: Complex<br />Condition: Complex<br />RT: 2485.560<br />density: 0.0016756009","Condition: Complex<br />Condition: Complex<br />RT: 2486.922<br />density: 0.0016635661","Condition: Complex<br />Condition: Complex<br />RT: 2488.284<br />density: 0.0016515568","Condition: Complex<br />Condition: Complex<br />RT: 2489.646<br />density: 0.0016395687","Condition: Complex<br />Condition: Complex<br />RT: 2491.008<br />density: 0.0016276168","Condition: Complex<br />Condition: Complex<br />RT: 2492.370<br />density: 0.0016156776","Condition: Complex<br />Condition: Complex<br />RT: 2493.732<br />density: 0.0016037689","Condition: Complex<br />Condition: Complex<br />RT: 2495.094<br />density: 0.0015918783","Condition: Complex<br />Condition: Complex<br />RT: 2496.456<br />density: 0.0015800045","Condition: Complex<br />Condition: Complex<br />RT: 2497.818<br />density: 0.0015681585","Condition: Complex<br />Condition: Complex<br />RT: 2499.180<br />density: 0.0015563232","Condition: Complex<br />Condition: Complex<br />RT: 2500.542<br />density: 0.0015445148","Condition: Complex<br />Condition: Complex<br />RT: 2501.904<br />density: 0.0015327226","Condition: Complex<br />Condition: Complex<br />RT: 2503.266<br />density: 0.0015209472","Condition: Complex<br />Condition: Complex<br />RT: 2504.628<br />density: 0.0015092001","Condition: Complex<br />Condition: Complex<br />RT: 2505.990<br />density: 0.0014974647","Condition: Complex<br />Condition: Complex<br />RT: 2507.352<br />density: 0.0014857621","Condition: Complex<br />Condition: Complex<br />RT: 2508.714<br />density: 0.0014740789","Condition: Complex<br />Condition: Complex<br />RT: 2510.076<br />density: 0.0014624187","Condition: Complex<br />Condition: Complex<br />RT: 2511.438<br />density: 0.0014507962","Condition: Complex<br />Condition: Complex<br />RT: 2512.800<br />density: 0.0014391901","Condition: Complex<br />Condition: Complex<br />RT: 2514.162<br />density: 0.0014276332","Condition: Complex<br />Condition: Complex<br />RT: 2515.524<br />density: 0.0014161038","Condition: Complex<br />Condition: Complex<br />RT: 2516.886<br />density: 0.0014046105","Condition: Complex<br />Condition: Complex<br />RT: 2518.249<br />density: 0.0013931723","Condition: Complex<br />Condition: Complex<br />RT: 2519.611<br />density: 0.0013817585","Condition: Complex<br />Condition: Complex<br />RT: 2520.973<br />density: 0.0013704219","Condition: Complex<br />Condition: Complex<br />RT: 2522.335<br />density: 0.0013591236","Condition: Complex<br />Condition: Complex<br />RT: 2523.697<br />density: 0.0013478823","Condition: Complex<br />Condition: Complex<br />RT: 2525.059<br />density: 0.0013367195","Condition: Complex<br />Condition: Complex<br />RT: 2526.421<br />density: 0.0013255922","Condition: Complex<br />Condition: Complex<br />RT: 2527.783<br />density: 0.0013145804","Condition: Complex<br />Condition: Complex<br />RT: 2529.145<br />density: 0.0013036194","Condition: Complex<br />Condition: Complex<br />RT: 2530.507<br />density: 0.0012927433","Condition: Complex<br />Condition: Complex<br />RT: 2531.869<br />density: 0.0012819723","Condition: Complex<br />Condition: Complex<br />RT: 2533.231<br />density: 0.0012712504","Condition: Complex<br />Condition: Complex<br />RT: 2534.593<br />density: 0.0012606909","Condition: Complex<br />Condition: Complex<br />RT: 2535.955<br />density: 0.0012501941","Condition: Complex<br />Condition: Complex<br />RT: 2537.317<br />density: 0.0012398163","Condition: Complex<br />Condition: Complex<br />RT: 2538.679<br />density: 0.0012295705","Condition: Complex<br />Condition: Complex<br />RT: 2540.041<br />density: 0.0012193902","Condition: Complex<br />Condition: Complex<br />RT: 2541.403<br />density: 0.0012094217","Condition: Complex<br />Condition: Complex<br />RT: 2542.765<br />density: 0.0011995273","Condition: Complex<br />Condition: Complex<br />RT: 2544.127<br />density: 0.0011897898","Condition: Complex<br />Condition: Complex<br />RT: 2545.489<br />density: 0.0011802090","Condition: Complex<br />Condition: Complex<br />RT: 2546.851<br />density: 0.0011707163","Condition: Complex<br />Condition: Complex<br />RT: 2548.213<br />density: 0.0011614743","Condition: Complex<br />Condition: Complex<br />RT: 2549.575<br />density: 0.0011523206","Condition: Complex<br />Condition: Complex<br />RT: 2550.937<br />density: 0.0011433627","Condition: Complex<br />Condition: Complex<br />RT: 2552.299<br />density: 0.0011345812","Condition: Complex<br />Condition: Complex<br />RT: 2553.661<br />density: 0.0011259120","Condition: Complex<br />Condition: Complex<br />RT: 2555.023<br />density: 0.0011175248","Condition: Complex<br />Condition: Complex<br />RT: 2556.386<br />density: 0.0011092383","Condition: Complex<br />Condition: Complex<br />RT: 2557.748<br />density: 0.0011011847","Condition: Complex<br />Condition: Complex<br />RT: 2559.110<br />density: 0.0010933201","Condition: Complex<br />Condition: Complex<br />RT: 2560.472<br />density: 0.0010855914","Condition: Complex<br />Condition: Complex<br />RT: 2561.834<br />density: 0.0010781657","Condition: Complex<br />Condition: Complex<br />RT: 2563.196<br />density: 0.0010708504","Condition: Complex<br />Condition: Complex<br />RT: 2564.558<br />density: 0.0010637994","Condition: Complex<br />Condition: Complex<br />RT: 2565.920<br />density: 0.0010569421","Condition: Complex<br />Condition: Complex<br />RT: 2567.282<br />density: 0.0010502413","Condition: Complex<br />Condition: Complex<br />RT: 2568.644<br />density: 0.0010438524","Condition: Complex<br />Condition: Complex<br />RT: 2570.006<br />density: 0.0010375795","Condition: Complex<br />Condition: Complex<br />RT: 2571.368<br />density: 0.0010315940","Condition: Complex<br />Condition: Complex<br />RT: 2572.730<br />density: 0.0010257982","Condition: Complex<br />Condition: Complex<br />RT: 2574.092<br />density: 0.0010201746","Condition: Complex<br />Condition: Complex<br />RT: 2575.454<br />density: 0.0010148583","Condition: Complex<br />Condition: Complex<br />RT: 2576.816<br />density: 0.0010096591","Condition: Complex<br />Condition: Complex<br />RT: 2578.178<br />density: 0.0010047590","Condition: Complex<br />Condition: Complex<br />RT: 2579.540<br />density: 0.0010000365","Condition: Complex<br />Condition: Complex<br />RT: 2580.902<br />density: 0.0009954947","Condition: Complex<br />Condition: Complex<br />RT: 2582.264<br />density: 0.0009912424","Condition: Complex<br />Condition: Complex<br />RT: 2583.626<br />density: 0.0009871037","Condition: Complex<br />Condition: Complex<br />RT: 2584.988<br />density: 0.0009832622","Condition: Complex<br />Condition: Complex<br />RT: 2586.350<br />density: 0.0009795787","Condition: Complex<br />Condition: Complex<br />RT: 2587.712<br />density: 0.0009760759","Condition: Complex<br />Condition: Complex<br />RT: 2589.074<br />density: 0.0009728327","Condition: Complex<br />Condition: Complex<br />RT: 2590.436<br />density: 0.0009696945","Condition: Complex<br />Condition: Complex<br />RT: 2591.798<br />density: 0.0009668369","Condition: Complex<br />Condition: Complex<br />RT: 2593.160<br />density: 0.0009641122","Condition: Complex<br />Condition: Complex<br />RT: 2594.523<br />density: 0.0009615581","Condition: Complex<br />Condition: Complex<br />RT: 2595.885<br />density: 0.0009592236","Condition: Complex<br />Condition: Complex<br />RT: 2597.247<br />density: 0.0009569811","Condition: Complex<br />Condition: Complex<br />RT: 2598.609<br />density: 0.0009549875","Condition: Complex<br />Condition: Complex<br />RT: 2599.971<br />density: 0.0009530978","Condition: Complex<br />Condition: Complex<br />RT: 2601.333<br />density: 0.0009513583","Condition: Complex<br />Condition: Complex<br />RT: 2602.695<br />density: 0.0009497911","Condition: Complex<br />Condition: Complex<br />RT: 2604.057<br />density: 0.0009482988","Condition: Complex<br />Condition: Complex<br />RT: 2605.419<br />density: 0.0009470092","Condition: Complex<br />Condition: Complex<br />RT: 2606.781<br />density: 0.0009457931","Condition: Complex<br />Condition: Complex<br />RT: 2608.143<br />density: 0.0009446969","Condition: Complex<br />Condition: Complex<br />RT: 2609.505<br />density: 0.0009437211","Condition: Complex<br />Condition: Complex<br />RT: 2610.867<br />density: 0.0009428001","Condition: Complex<br />Condition: Complex<br />RT: 2612.229<br />density: 0.0009420229","Condition: Complex<br />Condition: Complex<br />RT: 2613.591<br />density: 0.0009412895","Condition: Complex<br />Condition: Complex<br />RT: 2614.953<br />density: 0.0009406366","Condition: Complex<br />Condition: Complex<br />RT: 2616.315<br />density: 0.0009400512","Condition: Complex<br />Condition: Complex<br />RT: 2617.677<br />density: 0.0009394983","Condition: Complex<br />Condition: Complex<br />RT: 2619.039<br />density: 0.0009390206","Condition: Complex<br />Condition: Complex<br />RT: 2620.401<br />density: 0.0009385593","Condition: Complex<br />Condition: Complex<br />RT: 2621.763<br />density: 0.0009381322","Condition: Complex<br />Condition: Complex<br />RT: 2623.125<br />density: 0.0009377217","Condition: Complex<br />Condition: Complex<br />RT: 2624.487<br />density: 0.0009373201","Condition: Complex<br />Condition: Complex<br />RT: 2625.849<br />density: 0.0009369193","Condition: Complex<br />Condition: Complex<br />RT: 2627.211<br />density: 0.0009365114","Condition: Complex<br />Condition: Complex<br />RT: 2628.573<br />density: 0.0009360867","Condition: Complex<br />Condition: Complex<br />RT: 2629.935<br />density: 0.0009356323","Condition: Complex<br />Condition: Complex<br />RT: 2631.297<br />density: 0.0009351595","Condition: Complex<br />Condition: Complex<br />RT: 2632.659<br />density: 0.0009346191","Condition: Complex<br />Condition: Complex<br />RT: 2634.022<br />density: 0.0009340494","Condition: Complex<br />Condition: Complex<br />RT: 2635.384<br />density: 0.0009334099","Condition: Complex<br />Condition: Complex<br />RT: 2636.746<br />density: 0.0009327016","Condition: Complex<br />Condition: Complex<br />RT: 2638.108<br />density: 0.0009319452","Condition: Complex<br />Condition: Complex<br />RT: 2639.470<br />density: 0.0009310626","Condition: Complex<br />Condition: Complex<br />RT: 2640.832<br />density: 0.0009301304","Condition: Complex<br />Condition: Complex<br />RT: 2642.194<br />density: 0.0009290772","Condition: Complex<br />Condition: Complex<br />RT: 2643.556<br />density: 0.0009279245","Condition: Complex<br />Condition: Complex<br />RT: 2644.918<br />density: 0.0009266936","Condition: Complex<br />Condition: Complex<br />RT: 2646.280<br />density: 0.0009252902","Condition: Complex<br />Condition: Complex<br />RT: 2647.642<br />density: 0.0009238201","Condition: Complex<br />Condition: Complex<br />RT: 2649.004<br />density: 0.0009221821","Condition: Complex<br />Condition: Complex<br />RT: 2650.366<br />density: 0.0009204237","Condition: Complex<br />Condition: Complex<br />RT: 2651.728<br />density: 0.0009185589","Condition: Complex<br />Condition: Complex<br />RT: 2653.090<br />density: 0.0009164889","Condition: Complex<br />Condition: Complex<br />RT: 2654.452<br />density: 0.0009143390","Condition: Complex<br />Condition: Complex<br />RT: 2655.814<br />density: 0.0009119820","Condition: Complex<br />Condition: Complex<br />RT: 2657.176<br />density: 0.0009094934","Condition: Complex<br />Condition: Complex<br />RT: 2658.538<br />density: 0.0009068742","Condition: Complex<br />Condition: Complex<br />RT: 2659.900<br />density: 0.0009040314","Condition: Complex<br />Condition: Complex<br />RT: 2661.262<br />density: 0.0009010999","Condition: Complex<br />Condition: Complex<br />RT: 2662.624<br />density: 0.0008979324","Condition: Complex<br />Condition: Complex<br />RT: 2663.986<br />density: 0.0008946311","Condition: Complex<br />Condition: Complex<br />RT: 2665.348<br />density: 0.0008911810","Condition: Complex<br />Condition: Complex<br />RT: 2666.710<br />density: 0.0008875029","Condition: Complex<br />Condition: Complex<br />RT: 2668.072<br />density: 0.0008837320","Condition: Complex<br />Condition: Complex<br />RT: 2669.434<br />density: 0.0008797083","Condition: Complex<br />Condition: Complex<br />RT: 2670.796<br />density: 0.0008755567","Condition: Complex<br />Condition: Complex<br />RT: 2672.159<br />density: 0.0008712454","Condition: Complex<br />Condition: Complex<br />RT: 2673.521<br />density: 0.0008667146","Condition: Complex<br />Condition: Complex<br />RT: 2674.883<br />density: 0.0008620915","Condition: Complex<br />Condition: Complex<br />RT: 2676.245<br />density: 0.0008572120","Condition: Complex<br />Condition: Complex<br />RT: 2677.607<br />density: 0.0008522171","Condition: Complex<br />Condition: Complex<br />RT: 2678.969<br />density: 0.0008470601","Condition: Complex<br />Condition: Complex<br />RT: 2680.331<br />density: 0.0008417028","Condition: Complex<br />Condition: Complex<br />RT: 2681.693<br />density: 0.0008362582","Condition: Complex<br />Condition: Complex<br />RT: 2683.055<br />density: 0.0008305671","Condition: Complex<br />Condition: Complex<br />RT: 2684.417<br />density: 0.0008247778","Condition: Complex<br />Condition: Complex<br />RT: 2685.779<br />density: 0.0008188329","Condition: Complex<br />Condition: Complex<br />RT: 2687.141<br />density: 0.0008127152","Condition: Complex<br />Condition: Complex<br />RT: 2688.503<br />density: 0.0008065190","Condition: Complex<br />Condition: Complex<br />RT: 2689.865<br />density: 0.0008000993","Condition: Complex<br />Condition: Complex<br />RT: 2691.227<br />density: 0.0007936013","Condition: Complex<br />Condition: Complex<br />RT: 2692.589<br />density: 0.0007869629","Condition: Complex<br />Condition: Complex<br />RT: 2693.951<br />density: 0.0007801847","Condition: Complex<br />Condition: Complex<br />RT: 2695.313<br />density: 0.0007733403","Condition: Complex<br />Condition: Complex<br />RT: 2696.675<br />density: 0.0007663065","Condition: Complex<br />Condition: Complex<br />RT: 2698.037<br />density: 0.0007592152","Condition: Complex<br />Condition: Complex<br />RT: 2699.399<br />density: 0.0007520065","Condition: Complex<br />Condition: Complex<br />RT: 2700.761<br />density: 0.0007446941","Condition: Complex<br />Condition: Complex<br />RT: 2702.123<br />density: 0.0007373264","Condition: Complex<br />Condition: Complex<br />RT: 2703.485<br />density: 0.0007298197","Condition: Complex<br />Condition: Complex<br />RT: 2704.847<br />density: 0.0007222719","Condition: Complex<br />Condition: Complex<br />RT: 2706.209<br />density: 0.0007146362","Condition: Complex<br />Condition: Complex<br />RT: 2707.571<br />density: 0.0007069329","Condition: Complex<br />Condition: Complex<br />RT: 2708.933<br />density: 0.0006991889","Condition: Complex<br />Condition: Complex<br />RT: 2710.295<br />density: 0.0006913585","Condition: Complex<br />Condition: Complex<br />RT: 2711.658<br />density: 0.0006835033","Condition: Complex<br />Condition: Complex<br />RT: 2713.020<br />density: 0.0006755944","Condition: Complex<br />Condition: Complex<br />RT: 2714.382<br />density: 0.0006676518","Condition: Complex<br />Condition: Complex<br />RT: 2715.744<br />density: 0.0006596863","Condition: Complex<br />Condition: Complex<br />RT: 2717.106<br />density: 0.0006516846","Condition: Complex<br />Condition: Complex<br />RT: 2718.468<br />density: 0.0006436742","Condition: Complex<br />Condition: Complex<br />RT: 2719.830<br />density: 0.0006356466","Condition: Complex<br />Condition: Complex<br />RT: 2721.192<br />density: 0.0006276153","Condition: Complex<br />Condition: Complex<br />RT: 2722.554<br />density: 0.0006195814","Condition: Complex<br />Condition: Complex<br />RT: 2723.916<br />density: 0.0006115558","Condition: Complex<br />Condition: Complex<br />RT: 2725.278<br />density: 0.0006035367","Condition: Complex<br />Condition: Complex<br />RT: 2726.640<br />density: 0.0005955370","Condition: Complex<br />Condition: Complex<br />RT: 2728.002<br />density: 0.0005875586","Condition: Complex<br />Condition: Complex<br />RT: 2729.364<br />density: 0.0005795983","Condition: Complex<br />Condition: Complex<br />RT: 2730.726<br />density: 0.0005716840","Condition: Complex<br />Condition: Complex<br />RT: 2732.088<br />density: 0.0005637894","Condition: Complex<br />Condition: Complex<br />RT: 2733.450<br />density: 0.0005559489","Condition: Complex<br />Condition: Complex<br />RT: 2734.812<br />density: 0.0005481485","Condition: Complex<br />Condition: Complex<br />RT: 2736.174<br />density: 0.0005403867","Condition: Complex<br />Condition: Complex<br />RT: 2737.536<br />density: 0.0005326998","Condition: Complex<br />Condition: Complex<br />RT: 2738.898<br />density: 0.0005250437","Condition: Complex<br />Condition: Complex<br />RT: 2740.260<br />density: 0.0005174723","Condition: Complex<br />Condition: Complex<br />RT: 2741.622<br />density: 0.0005099536","Condition: Complex<br />Condition: Complex<br />RT: 2742.984<br />density: 0.0005024921","Condition: Complex<br />Condition: Complex<br />RT: 2744.346<br />density: 0.0004951256","Condition: Complex<br />Condition: Complex<br />RT: 2745.708<br />density: 0.0004877983","Condition: Complex<br />Condition: Complex<br />RT: 2747.070<br />density: 0.0004805807","Condition: Complex<br />Condition: Complex<br />RT: 2748.432<br />density: 0.0004734227","Condition: Complex<br />Condition: Complex<br />RT: 2749.795<br />density: 0.0004663373","Condition: Complex<br />Condition: Complex<br />RT: 2751.157<br />density: 0.0004593583","Condition: Complex<br />Condition: Complex<br />RT: 2752.519<br />density: 0.0004524244","Condition: Complex<br />Condition: Complex<br />RT: 2753.881<br />density: 0.0004456183","Condition: Complex<br />Condition: Complex<br />RT: 2755.243<br />density: 0.0004388737","Condition: Complex<br />Condition: Complex<br />RT: 2756.605<br />density: 0.0004322129","Condition: Complex<br />Condition: Complex<br />RT: 2757.967<br />density: 0.0004256625","Condition: Complex<br />Condition: Complex<br />RT: 2759.329<br />density: 0.0004191600","Condition: Complex<br />Condition: Complex<br />RT: 2760.691<br />density: 0.0004127964","Condition: Complex<br />Condition: Complex<br />RT: 2762.053<br />density: 0.0004064919","Condition: Complex<br />Condition: Complex<br />RT: 2763.415<br />density: 0.0004002784","Condition: Complex<br />Condition: Complex<br />RT: 2764.777<br />density: 0.0003941723","Condition: Complex<br />Condition: Complex<br />RT: 2766.139<br />density: 0.0003881146","Condition: Complex<br />Condition: Complex<br />RT: 2767.501<br />density: 0.0003821998","Condition: Complex<br />Condition: Complex<br />RT: 2768.863<br />density: 0.0003763386","Condition: Complex<br />Condition: Complex<br />RT: 2770.225<br />density: 0.0003705709","Condition: Complex<br />Condition: Complex<br />RT: 2771.587<br />density: 0.0003649029","Condition: Complex<br />Condition: Complex<br />RT: 2772.949<br />density: 0.0003592818","Condition: Complex<br />Condition: Complex<br />RT: 2774.311<br />density: 0.0003538007","Condition: Complex<br />Condition: Complex<br />RT: 2775.673<br />density: 0.0003483660","Condition: Complex<br />Condition: Complex<br />RT: 2777.035<br />density: 0.0003430232","Condition: Complex<br />Condition: Complex<br />RT: 2778.397<br />density: 0.0003377690","Condition: Complex<br />Condition: Complex<br />RT: 2779.759<br />density: 0.0003325604","Condition: Complex<br />Condition: Complex<br />RT: 2781.121<br />density: 0.0003274794","Condition: Complex<br />Condition: Complex<br />RT: 2782.483<br />density: 0.0003224390","Condition: Complex<br />Condition: Complex<br />RT: 2783.845<br />density: 0.0003174852","Condition: Complex<br />Condition: Complex<br />RT: 2785.207<br />density: 0.0003126071","Condition: Complex<br />Condition: Complex<br />RT: 2786.569<br />density: 0.0003077732","Condition: Complex<br />Condition: Complex<br />RT: 2787.932<br />density: 0.0003030487","Condition: Complex<br />Condition: Complex<br />RT: 2789.294<br />density: 0.0002983599","Condition: Complex<br />Condition: Complex<br />RT: 2790.656<br />density: 0.0002937498","Condition: Complex<br />Condition: Complex<br />RT: 2792.018<br />density: 0.0002892022","Condition: Complex<br />Condition: Complex<br />RT: 2793.380<br />density: 0.0002846958","Condition: Complex<br />Condition: Complex<br />RT: 2794.742<br />density: 0.0002802802","Condition: Complex<br />Condition: Complex<br />RT: 2796.104<br />density: 0.0002758950","Condition: Complex<br />Condition: Complex<br />RT: 2797.466<br />density: 0.0002715793","Condition: Complex<br />Condition: Complex<br />RT: 2798.828<br />density: 0.0002673136","Condition: Complex<br />Condition: Complex<br />RT: 2800.190<br />density: 0.0002630850","Condition: Complex<br />Condition: Complex<br />RT: 2801.552<br />density: 0.0002589299","Condition: Complex<br />Condition: Complex<br />RT: 2802.914<br />density: 0.0002548002","Condition: Complex<br />Condition: Complex<br />RT: 2804.276<br />density: 0.0002507303","Condition: Complex<br />Condition: Complex<br />RT: 2805.638<br />density: 0.0002466995","Condition: Complex<br />Condition: Complex<br />RT: 2807.000<br />density: 0.0002427015","Condition: Complex<br />Condition: Complex<br />RT: 2807.000<br />density: 0.0002427015","Condition: Complex<br />Condition: Complex<br />RT: 2805.638<br />density: 0.0002466995","Condition: Complex<br />Condition: Complex<br />RT: 2804.276<br />density: 0.0002507303","Condition: Complex<br />Condition: Complex<br />RT: 2802.914<br />density: 0.0002548002","Condition: Complex<br />Condition: Complex<br />RT: 2801.552<br />density: 0.0002589299","Condition: Complex<br />Condition: Complex<br />RT: 2800.190<br />density: 0.0002630850","Condition: Complex<br />Condition: Complex<br />RT: 2798.828<br />density: 0.0002673136","Condition: Complex<br />Condition: Complex<br />RT: 2797.466<br />density: 0.0002715793","Condition: Complex<br />Condition: Complex<br />RT: 2796.104<br />density: 0.0002758950","Condition: Complex<br />Condition: Complex<br />RT: 2794.742<br />density: 0.0002802802","Condition: Complex<br />Condition: Complex<br />RT: 2793.380<br />density: 0.0002846958","Condition: Complex<br />Condition: Complex<br />RT: 2792.018<br />density: 0.0002892022","Condition: Complex<br />Condition: Complex<br />RT: 2790.656<br />density: 0.0002937498","Condition: Complex<br />Condition: Complex<br />RT: 2789.294<br />density: 0.0002983599","Condition: Complex<br />Condition: Complex<br />RT: 2787.932<br />density: 0.0003030487","Condition: Complex<br />Condition: Complex<br />RT: 2786.569<br />density: 0.0003077732","Condition: Complex<br />Condition: Complex<br />RT: 2785.207<br />density: 0.0003126071","Condition: Complex<br />Condition: Complex<br />RT: 2783.845<br />density: 0.0003174852","Condition: Complex<br />Condition: Complex<br />RT: 2782.483<br />density: 0.0003224390","Condition: Complex<br />Condition: Complex<br />RT: 2781.121<br />density: 0.0003274794","Condition: Complex<br />Condition: Complex<br />RT: 2779.759<br />density: 0.0003325604","Condition: Complex<br />Condition: Complex<br />RT: 2778.397<br />density: 0.0003377690","Condition: Complex<br />Condition: Complex<br />RT: 2777.035<br />density: 0.0003430232","Condition: Complex<br />Condition: Complex<br />RT: 2775.673<br />density: 0.0003483660","Condition: Complex<br />Condition: Complex<br />RT: 2774.311<br />density: 0.0003538007","Condition: Complex<br />Condition: Complex<br />RT: 2772.949<br />density: 0.0003592818","Condition: Complex<br />Condition: Complex<br />RT: 2771.587<br />density: 0.0003649029","Condition: Complex<br />Condition: Complex<br />RT: 2770.225<br />density: 0.0003705709","Condition: Complex<br />Condition: Complex<br />RT: 2768.863<br />density: 0.0003763386","Condition: Complex<br />Condition: Complex<br />RT: 2767.501<br />density: 0.0003821998","Condition: Complex<br />Condition: Complex<br />RT: 2766.139<br />density: 0.0003881146","Condition: Complex<br />Condition: Complex<br />RT: 2764.777<br />density: 0.0003941723","Condition: Complex<br />Condition: Complex<br />RT: 2763.415<br />density: 0.0004002784","Condition: Complex<br />Condition: Complex<br />RT: 2762.053<br />density: 0.0004064919","Condition: Complex<br />Condition: Complex<br />RT: 2760.691<br />density: 0.0004127964","Condition: Complex<br />Condition: Complex<br />RT: 2759.329<br />density: 0.0004191600","Condition: Complex<br />Condition: Complex<br />RT: 2757.967<br />density: 0.0004256625","Condition: Complex<br />Condition: Complex<br />RT: 2756.605<br />density: 0.0004322129","Condition: Complex<br />Condition: Complex<br />RT: 2755.243<br />density: 0.0004388737","Condition: Complex<br />Condition: Complex<br />RT: 2753.881<br />density: 0.0004456183","Condition: Complex<br />Condition: Complex<br />RT: 2752.519<br />density: 0.0004524244","Condition: Complex<br />Condition: Complex<br />RT: 2751.157<br />density: 0.0004593583","Condition: Complex<br />Condition: Complex<br />RT: 2749.795<br />density: 0.0004663373","Condition: Complex<br />Condition: Complex<br />RT: 2748.432<br />density: 0.0004734227","Condition: Complex<br />Condition: Complex<br />RT: 2747.070<br />density: 0.0004805807","Condition: Complex<br />Condition: Complex<br />RT: 2745.708<br />density: 0.0004877983","Condition: Complex<br />Condition: Complex<br />RT: 2744.346<br />density: 0.0004951256","Condition: Complex<br />Condition: Complex<br />RT: 2742.984<br />density: 0.0005024921","Condition: Complex<br />Condition: Complex<br />RT: 2741.622<br />density: 0.0005099536","Condition: Complex<br />Condition: Complex<br />RT: 2740.260<br />density: 0.0005174723","Condition: Complex<br />Condition: Complex<br />RT: 2738.898<br />density: 0.0005250437","Condition: Complex<br />Condition: Complex<br />RT: 2737.536<br />density: 0.0005326998","Condition: Complex<br />Condition: Complex<br />RT: 2736.174<br />density: 0.0005403867","Condition: Complex<br />Condition: Complex<br />RT: 2734.812<br />density: 0.0005481485","Condition: Complex<br />Condition: Complex<br />RT: 2733.450<br />density: 0.0005559489","Condition: Complex<br />Condition: Complex<br />RT: 2732.088<br />density: 0.0005637894","Condition: Complex<br />Condition: Complex<br />RT: 2730.726<br />density: 0.0005716840","Condition: Complex<br />Condition: Complex<br />RT: 2729.364<br />density: 0.0005795983","Condition: Complex<br />Condition: Complex<br />RT: 2728.002<br />density: 0.0005875586","Condition: Complex<br />Condition: Complex<br />RT: 2726.640<br />density: 0.0005955370","Condition: Complex<br />Condition: Complex<br />RT: 2725.278<br />density: 0.0006035367","Condition: Complex<br />Condition: Complex<br />RT: 2723.916<br />density: 0.0006115558","Condition: Complex<br />Condition: Complex<br />RT: 2722.554<br />density: 0.0006195814","Condition: Complex<br />Condition: Complex<br />RT: 2721.192<br />density: 0.0006276153","Condition: Complex<br />Condition: Complex<br />RT: 2719.830<br />density: 0.0006356466","Condition: Complex<br />Condition: Complex<br />RT: 2718.468<br />density: 0.0006436742","Condition: Complex<br />Condition: Complex<br />RT: 2717.106<br />density: 0.0006516846","Condition: Complex<br />Condition: Complex<br />RT: 2715.744<br />density: 0.0006596863","Condition: Complex<br />Condition: Complex<br />RT: 2714.382<br />density: 0.0006676518","Condition: Complex<br />Condition: Complex<br />RT: 2713.020<br />density: 0.0006755944","Condition: Complex<br />Condition: Complex<br />RT: 2711.658<br />density: 0.0006835033","Condition: Complex<br />Condition: Complex<br />RT: 2710.295<br />density: 0.0006913585","Condition: Complex<br />Condition: Complex<br />RT: 2708.933<br />density: 0.0006991889","Condition: Complex<br />Condition: Complex<br />RT: 2707.571<br />density: 0.0007069329","Condition: Complex<br />Condition: Complex<br />RT: 2706.209<br />density: 0.0007146362","Condition: Complex<br />Condition: Complex<br />RT: 2704.847<br />density: 0.0007222719","Condition: Complex<br />Condition: Complex<br />RT: 2703.485<br />density: 0.0007298197","Condition: Complex<br />Condition: Complex<br />RT: 2702.123<br />density: 0.0007373264","Condition: Complex<br />Condition: Complex<br />RT: 2700.761<br />density: 0.0007446941","Condition: Complex<br />Condition: Complex<br />RT: 2699.399<br />density: 0.0007520065","Condition: Complex<br />Condition: Complex<br />RT: 2698.037<br />density: 0.0007592152","Condition: Complex<br />Condition: Complex<br />RT: 2696.675<br />density: 0.0007663065","Condition: Complex<br />Condition: Complex<br />RT: 2695.313<br />density: 0.0007733403","Condition: Complex<br />Condition: Complex<br />RT: 2693.951<br />density: 0.0007801847","Condition: Complex<br />Condition: Complex<br />RT: 2692.589<br />density: 0.0007869629","Condition: Complex<br />Condition: Complex<br />RT: 2691.227<br />density: 0.0007936013","Condition: Complex<br />Condition: Complex<br />RT: 2689.865<br />density: 0.0008000993","Condition: Complex<br />Condition: Complex<br />RT: 2688.503<br />density: 0.0008065190","Condition: Complex<br />Condition: Complex<br />RT: 2687.141<br />density: 0.0008127152","Condition: Complex<br />Condition: Complex<br />RT: 2685.779<br />density: 0.0008188329","Condition: Complex<br />Condition: Complex<br />RT: 2684.417<br />density: 0.0008247778","Condition: Complex<br />Condition: Complex<br />RT: 2683.055<br />density: 0.0008305671","Condition: Complex<br />Condition: Complex<br />RT: 2681.693<br />density: 0.0008362582","Condition: Complex<br />Condition: Complex<br />RT: 2680.331<br />density: 0.0008417028","Condition: Complex<br />Condition: Complex<br />RT: 2678.969<br />density: 0.0008470601","Condition: Complex<br />Condition: Complex<br />RT: 2677.607<br />density: 0.0008522171","Condition: Complex<br />Condition: Complex<br />RT: 2676.245<br />density: 0.0008572120","Condition: Complex<br />Condition: Complex<br />RT: 2674.883<br />density: 0.0008620915","Condition: Complex<br />Condition: Complex<br />RT: 2673.521<br />density: 0.0008667146","Condition: Complex<br />Condition: Complex<br />RT: 2672.159<br />density: 0.0008712454","Condition: Complex<br />Condition: Complex<br />RT: 2670.796<br />density: 0.0008755567","Condition: Complex<br />Condition: Complex<br />RT: 2669.434<br />density: 0.0008797083","Condition: Complex<br />Condition: Complex<br />RT: 2668.072<br />density: 0.0008837320","Condition: Complex<br />Condition: Complex<br />RT: 2666.710<br />density: 0.0008875029","Condition: Complex<br />Condition: Complex<br />RT: 2665.348<br />density: 0.0008911810","Condition: Complex<br />Condition: Complex<br />RT: 2663.986<br />density: 0.0008946311","Condition: Complex<br />Condition: Complex<br />RT: 2662.624<br />density: 0.0008979324","Condition: Complex<br />Condition: Complex<br />RT: 2661.262<br />density: 0.0009010999","Condition: Complex<br />Condition: Complex<br />RT: 2659.900<br />density: 0.0009040314","Condition: Complex<br />Condition: Complex<br />RT: 2658.538<br />density: 0.0009068742","Condition: Complex<br />Condition: Complex<br />RT: 2657.176<br />density: 0.0009094934","Condition: Complex<br />Condition: Complex<br />RT: 2655.814<br />density: 0.0009119820","Condition: Complex<br />Condition: Complex<br />RT: 2654.452<br />density: 0.0009143390","Condition: Complex<br />Condition: Complex<br />RT: 2653.090<br />density: 0.0009164889","Condition: Complex<br />Condition: Complex<br />RT: 2651.728<br />density: 0.0009185589","Condition: Complex<br />Condition: Complex<br />RT: 2650.366<br />density: 0.0009204237","Condition: Complex<br />Condition: Complex<br />RT: 2649.004<br />density: 0.0009221821","Condition: Complex<br />Condition: Complex<br />RT: 2647.642<br />density: 0.0009238201","Condition: Complex<br />Condition: Complex<br />RT: 2646.280<br />density: 0.0009252902","Condition: Complex<br />Condition: Complex<br />RT: 2644.918<br />density: 0.0009266936","Condition: Complex<br />Condition: Complex<br />RT: 2643.556<br />density: 0.0009279245","Condition: Complex<br />Condition: Complex<br />RT: 2642.194<br />density: 0.0009290772","Condition: Complex<br />Condition: Complex<br />RT: 2640.832<br />density: 0.0009301304","Condition: Complex<br />Condition: Complex<br />RT: 2639.470<br />density: 0.0009310626","Condition: Complex<br />Condition: Complex<br />RT: 2638.108<br />density: 0.0009319452","Condition: Complex<br />Condition: Complex<br />RT: 2636.746<br />density: 0.0009327016","Condition: Complex<br />Condition: Complex<br />RT: 2635.384<br />density: 0.0009334099","Condition: Complex<br />Condition: Complex<br />RT: 2634.022<br />density: 0.0009340494","Condition: Complex<br />Condition: Complex<br />RT: 2632.659<br />density: 0.0009346191","Condition: Complex<br />Condition: Complex<br />RT: 2631.297<br />density: 0.0009351595","Condition: Complex<br />Condition: Complex<br />RT: 2629.935<br />density: 0.0009356323","Condition: Complex<br />Condition: Complex<br />RT: 2628.573<br />density: 0.0009360867","Condition: Complex<br />Condition: Complex<br />RT: 2627.211<br />density: 0.0009365114","Condition: Complex<br />Condition: Complex<br />RT: 2625.849<br />density: 0.0009369193","Condition: Complex<br />Condition: Complex<br />RT: 2624.487<br />density: 0.0009373201","Condition: Complex<br />Condition: Complex<br />RT: 2623.125<br />density: 0.0009377217","Condition: Complex<br />Condition: Complex<br />RT: 2621.763<br />density: 0.0009381322","Condition: Complex<br />Condition: Complex<br />RT: 2620.401<br />density: 0.0009385593","Condition: Complex<br />Condition: Complex<br />RT: 2619.039<br />density: 0.0009390206","Condition: Complex<br />Condition: Complex<br />RT: 2617.677<br />density: 0.0009394983","Condition: Complex<br />Condition: Complex<br />RT: 2616.315<br />density: 0.0009400512","Condition: Complex<br />Condition: Complex<br />RT: 2614.953<br />density: 0.0009406366","Condition: Complex<br />Condition: Complex<br />RT: 2613.591<br />density: 0.0009412895","Condition: Complex<br />Condition: Complex<br />RT: 2612.229<br />density: 0.0009420229","Condition: Complex<br />Condition: Complex<br />RT: 2610.867<br />density: 0.0009428001","Condition: Complex<br />Condition: Complex<br />RT: 2609.505<br />density: 0.0009437211","Condition: Complex<br />Condition: Complex<br />RT: 2608.143<br />density: 0.0009446969","Condition: Complex<br />Condition: Complex<br />RT: 2606.781<br />density: 0.0009457931","Condition: Complex<br />Condition: Complex<br />RT: 2605.419<br />density: 0.0009470092","Condition: Complex<br />Condition: Complex<br />RT: 2604.057<br />density: 0.0009482988","Condition: Complex<br />Condition: Complex<br />RT: 2602.695<br />density: 0.0009497911","Condition: Complex<br />Condition: Complex<br />RT: 2601.333<br />density: 0.0009513583","Condition: Complex<br />Condition: Complex<br />RT: 2599.971<br />density: 0.0009530978","Condition: Complex<br />Condition: Complex<br />RT: 2598.609<br />density: 0.0009549875","Condition: Complex<br />Condition: Complex<br />RT: 2597.247<br />density: 0.0009569811","Condition: Complex<br />Condition: Complex<br />RT: 2595.885<br />density: 0.0009592236","Condition: Complex<br />Condition: Complex<br />RT: 2594.523<br />density: 0.0009615581","Condition: Complex<br />Condition: Complex<br />RT: 2593.160<br />density: 0.0009641122","Condition: Complex<br />Condition: Complex<br />RT: 2591.798<br />density: 0.0009668369","Condition: Complex<br />Condition: Complex<br />RT: 2590.436<br />density: 0.0009696945","Condition: Complex<br />Condition: Complex<br />RT: 2589.074<br />density: 0.0009728327","Condition: Complex<br />Condition: Complex<br />RT: 2587.712<br />density: 0.0009760759","Condition: Complex<br />Condition: Complex<br />RT: 2586.350<br />density: 0.0009795787","Condition: Complex<br />Condition: Complex<br />RT: 2584.988<br />density: 0.0009832622","Condition: Complex<br />Condition: Complex<br />RT: 2583.626<br />density: 0.0009871037","Condition: Complex<br />Condition: Complex<br />RT: 2582.264<br />density: 0.0009912424","Condition: Complex<br />Condition: Complex<br />RT: 2580.902<br />density: 0.0009954947","Condition: Complex<br />Condition: Complex<br />RT: 2579.540<br />density: 0.0010000365","Condition: Complex<br />Condition: Complex<br />RT: 2578.178<br />density: 0.0010047590","Condition: Complex<br />Condition: Complex<br />RT: 2576.816<br />density: 0.0010096591","Condition: Complex<br />Condition: Complex<br />RT: 2575.454<br />density: 0.0010148583","Condition: Complex<br />Condition: Complex<br />RT: 2574.092<br />density: 0.0010201746","Condition: Complex<br />Condition: Complex<br />RT: 2572.730<br />density: 0.0010257982","Condition: Complex<br />Condition: Complex<br />RT: 2571.368<br />density: 0.0010315940","Condition: Complex<br />Condition: Complex<br />RT: 2570.006<br />density: 0.0010375795","Condition: Complex<br />Condition: Complex<br />RT: 2568.644<br />density: 0.0010438524","Condition: Complex<br />Condition: Complex<br />RT: 2567.282<br />density: 0.0010502413","Condition: Complex<br />Condition: Complex<br />RT: 2565.920<br />density: 0.0010569421","Condition: Complex<br />Condition: Complex<br />RT: 2564.558<br />density: 0.0010637994","Condition: Complex<br />Condition: Complex<br />RT: 2563.196<br />density: 0.0010708504","Condition: Complex<br />Condition: Complex<br />RT: 2561.834<br />density: 0.0010781657","Condition: Complex<br />Condition: Complex<br />RT: 2560.472<br />density: 0.0010855914","Condition: Complex<br />Condition: Complex<br />RT: 2559.110<br />density: 0.0010933201","Condition: Complex<br />Condition: Complex<br />RT: 2557.748<br />density: 0.0011011847","Condition: Complex<br />Condition: Complex<br />RT: 2556.386<br />density: 0.0011092383","Condition: Complex<br />Condition: Complex<br />RT: 2555.023<br />density: 0.0011175248","Condition: Complex<br />Condition: Complex<br />RT: 2553.661<br />density: 0.0011259120","Condition: Complex<br />Condition: Complex<br />RT: 2552.299<br />density: 0.0011345812","Condition: Complex<br />Condition: Complex<br />RT: 2550.937<br />density: 0.0011433627","Condition: Complex<br />Condition: Complex<br />RT: 2549.575<br />density: 0.0011523206","Condition: Complex<br />Condition: Complex<br />RT: 2548.213<br />density: 0.0011614743","Condition: Complex<br />Condition: Complex<br />RT: 2546.851<br />density: 0.0011707163","Condition: Complex<br />Condition: Complex<br />RT: 2545.489<br />density: 0.0011802090","Condition: Complex<br />Condition: Complex<br />RT: 2544.127<br />density: 0.0011897898","Condition: Complex<br />Condition: Complex<br />RT: 2542.765<br />density: 0.0011995273","Condition: Complex<br />Condition: Complex<br />RT: 2541.403<br />density: 0.0012094217","Condition: Complex<br />Condition: Complex<br />RT: 2540.041<br />density: 0.0012193902","Condition: Complex<br />Condition: Complex<br />RT: 2538.679<br />density: 0.0012295705","Condition: Complex<br />Condition: Complex<br />RT: 2537.317<br />density: 0.0012398163","Condition: Complex<br />Condition: Complex<br />RT: 2535.955<br />density: 0.0012501941","Condition: Complex<br />Condition: Complex<br />RT: 2534.593<br />density: 0.0012606909","Condition: Complex<br />Condition: Complex<br />RT: 2533.231<br />density: 0.0012712504","Condition: Complex<br />Condition: Complex<br />RT: 2531.869<br />density: 0.0012819723","Condition: Complex<br />Condition: Complex<br />RT: 2530.507<br />density: 0.0012927433","Condition: Complex<br />Condition: Complex<br />RT: 2529.145<br />density: 0.0013036194","Condition: Complex<br />Condition: Complex<br />RT: 2527.783<br />density: 0.0013145804","Condition: Complex<br />Condition: Complex<br />RT: 2526.421<br />density: 0.0013255922","Condition: Complex<br />Condition: Complex<br />RT: 2525.059<br />density: 0.0013367195","Condition: Complex<br />Condition: Complex<br />RT: 2523.697<br />density: 0.0013478823","Condition: Complex<br />Condition: Complex<br />RT: 2522.335<br />density: 0.0013591236","Condition: Complex<br />Condition: Complex<br />RT: 2520.973<br />density: 0.0013704219","Condition: Complex<br />Condition: Complex<br />RT: 2519.611<br />density: 0.0013817585","Condition: Complex<br />Condition: Complex<br />RT: 2518.249<br />density: 0.0013931723","Condition: Complex<br />Condition: Complex<br />RT: 2516.886<br />density: 0.0014046105","Condition: Complex<br />Condition: Complex<br />RT: 2515.524<br />density: 0.0014161038","Condition: Complex<br />Condition: Complex<br />RT: 2514.162<br />density: 0.0014276332","Condition: Complex<br />Condition: Complex<br />RT: 2512.800<br />density: 0.0014391901","Condition: Complex<br />Condition: Complex<br />RT: 2511.438<br />density: 0.0014507962","Condition: Complex<br />Condition: Complex<br />RT: 2510.076<br />density: 0.0014624187","Condition: Complex<br />Condition: Complex<br />RT: 2508.714<br />density: 0.0014740789","Condition: Complex<br />Condition: Complex<br />RT: 2507.352<br />density: 0.0014857621","Condition: Complex<br />Condition: Complex<br />RT: 2505.990<br />density: 0.0014974647","Condition: Complex<br />Condition: Complex<br />RT: 2504.628<br />density: 0.0015092001","Condition: Complex<br />Condition: Complex<br />RT: 2503.266<br />density: 0.0015209472","Condition: Complex<br />Condition: Complex<br />RT: 2501.904<br />density: 0.0015327226","Condition: Complex<br />Condition: Complex<br />RT: 2500.542<br />density: 0.0015445148","Condition: Complex<br />Condition: Complex<br />RT: 2499.180<br />density: 0.0015563232","Condition: Complex<br />Condition: Complex<br />RT: 2497.818<br />density: 0.0015681585","Condition: Complex<br />Condition: Complex<br />RT: 2496.456<br />density: 0.0015800045","Condition: Complex<br />Condition: Complex<br />RT: 2495.094<br />density: 0.0015918783","Condition: Complex<br />Condition: Complex<br />RT: 2493.732<br />density: 0.0016037689","Condition: Complex<br />Condition: Complex<br />RT: 2492.370<br />density: 0.0016156776","Condition: Complex<br />Condition: Complex<br />RT: 2491.008<br />density: 0.0016276168","Condition: Complex<br />Condition: Complex<br />RT: 2489.646<br />density: 0.0016395687","Condition: Complex<br />Condition: Complex<br />RT: 2488.284<br />density: 0.0016515568","Condition: Complex<br />Condition: Complex<br />RT: 2486.922<br />density: 0.0016635661","Condition: Complex<br />Condition: Complex<br />RT: 2485.560<br />density: 0.0016756009","Condition: Complex<br />Condition: Complex<br />RT: 2484.198<br />density: 0.0016876761","Condition: Complex<br />Condition: Complex<br />RT: 2482.836<br />density: 0.0016997688","Condition: Complex<br />Condition: Complex<br />RT: 2481.474<br />density: 0.0017119140","Condition: Complex<br />Condition: Complex<br />RT: 2480.112<br />density: 0.0017240869","Condition: Complex<br />Condition: Complex<br />RT: 2478.750<br />density: 0.0017362971","Condition: Complex<br />Condition: Complex<br />RT: 2477.387<br />density: 0.0017485614","Condition: Complex<br />Condition: Complex<br />RT: 2476.025<br />density: 0.0017608495","Condition: Complex<br />Condition: Complex<br />RT: 2474.663<br />density: 0.0017732114","Condition: Complex<br />Condition: Complex<br />RT: 2473.301<br />density: 0.0017856075","Condition: Complex<br />Condition: Complex<br />RT: 2471.939<br />density: 0.0017980561","Condition: Complex<br />Condition: Complex<br />RT: 2470.577<br />density: 0.0018105721","Condition: Complex<br />Condition: Complex<br />RT: 2469.215<br />density: 0.0018231188","Condition: Complex<br />Condition: Complex<br />RT: 2467.853<br />density: 0.0018357619","Condition: Complex<br />Condition: Complex<br />RT: 2466.491<br />density: 0.0018484441","Condition: Complex<br />Condition: Complex<br />RT: 2465.129<br />density: 0.0018611941","Condition: Complex<br />Condition: Complex<br />RT: 2463.767<br />density: 0.0018740219","Condition: Complex<br />Condition: Complex<br />RT: 2462.405<br />density: 0.0018868861","Condition: Complex<br />Condition: Complex<br />RT: 2461.043<br />density: 0.0018998661","Condition: Complex<br />Condition: Complex<br />RT: 2459.681<br />density: 0.0019128869","Condition: Complex<br />Condition: Complex<br />RT: 2458.319<br />density: 0.0019259880","Condition: Complex<br />Condition: Complex<br />RT: 2456.957<br />density: 0.0019391709","Condition: Complex<br />Condition: Complex<br />RT: 2455.595<br />density: 0.0019523957","Condition: Complex<br />Condition: Complex<br />RT: 2454.233<br />density: 0.0019657436","Condition: Complex<br />Condition: Complex<br />RT: 2452.871<br />density: 0.0019791318","Condition: Complex<br />Condition: Complex<br />RT: 2451.509<br />density: 0.0019926062","Condition: Complex<br />Condition: Complex<br />RT: 2450.147<br />density: 0.0020061583","Condition: Complex<br />Condition: Complex<br />RT: 2448.785<br />density: 0.0020197555","Condition: Complex<br />Condition: Complex<br />RT: 2447.423<br />density: 0.0020334667","Condition: Complex<br />Condition: Complex<br />RT: 2446.061<br />density: 0.0020472150","Condition: Complex<br />Condition: Complex<br />RT: 2444.699<br />density: 0.0020610451","Condition: Complex<br />Condition: Complex<br />RT: 2443.337<br />density: 0.0020749395","Condition: Complex<br />Condition: Complex<br />RT: 2441.975<br />density: 0.0020888760","Condition: Complex<br />Condition: Complex<br />RT: 2440.613<br />density: 0.0021029025","Condition: Complex<br />Condition: Complex<br />RT: 2439.250<br />density: 0.0021169574","Condition: Complex<br />Condition: Complex<br />RT: 2437.888<br />density: 0.0021310764","Condition: Complex<br />Condition: Complex<br />RT: 2436.526<br />density: 0.0021452367","Condition: Complex<br />Condition: Complex<br />RT: 2435.164<br />density: 0.0021594275","Condition: Complex<br />Condition: Complex<br />RT: 2433.802<br />density: 0.0021736688","Condition: Complex<br />Condition: Complex<br />RT: 2432.440<br />density: 0.0021879244","Condition: Complex<br />Condition: Complex<br />RT: 2431.078<br />density: 0.0022022097","Condition: Complex<br />Condition: Complex<br />RT: 2429.716<br />density: 0.0022165051","Condition: Complex<br />Condition: Complex<br />RT: 2428.354<br />density: 0.0022308089","Condition: Complex<br />Condition: Complex<br />RT: 2426.992<br />density: 0.0022451095","Condition: Complex<br />Condition: Complex<br />RT: 2425.630<br />density: 0.0022594043","Condition: Complex<br />Condition: Complex<br />RT: 2424.268<br />density: 0.0022736768","Condition: Complex<br />Condition: Complex<br />RT: 2422.906<br />density: 0.0022879216","Condition: Complex<br />Condition: Complex<br />RT: 2421.544<br />density: 0.0023021406","Condition: Complex<br />Condition: Complex<br />RT: 2420.182<br />density: 0.0023162912","Condition: Complex<br />Condition: Complex<br />RT: 2418.820<br />density: 0.0023304105","Condition: Complex<br />Condition: Complex<br />RT: 2417.458<br />density: 0.0023444374","Condition: Complex<br />Condition: Complex<br />RT: 2416.096<br />density: 0.0023583950","Condition: Complex<br />Condition: Complex<br />RT: 2414.734<br />density: 0.0023722801","Condition: Complex<br />Condition: Complex<br />RT: 2413.372<br />density: 0.0023860237","Condition: Complex<br />Condition: Complex<br />RT: 2412.010<br />density: 0.0023997062","Condition: Complex<br />Condition: Complex<br />RT: 2410.648<br />density: 0.0024132091","Condition: Complex<br />Condition: Complex<br />RT: 2409.286<br />density: 0.0024266004","Condition: Complex<br />Condition: Complex<br />RT: 2407.924<br />density: 0.0024398607","Condition: Complex<br />Condition: Complex<br />RT: 2406.562<br />density: 0.0024529028","Condition: Complex<br />Condition: Complex<br />RT: 2405.200<br />density: 0.0024658509","Condition: Complex<br />Condition: Complex<br />RT: 2403.838<br />density: 0.0024785182","Condition: Complex<br />Condition: Complex<br />RT: 2402.476<br />density: 0.0024910339","Condition: Complex<br />Condition: Complex<br />RT: 2401.114<br />density: 0.0025033498","Condition: Complex<br />Condition: Complex<br />RT: 2399.751<br />density: 0.0025153726","Condition: Complex<br />Condition: Complex<br />RT: 2398.389<br />density: 0.0025272666","Condition: Complex<br />Condition: Complex<br />RT: 2397.027<br />density: 0.0025387688","Condition: Complex<br />Condition: Complex<br />RT: 2395.665<br />density: 0.0025500850","Condition: Complex<br />Condition: Complex<br />RT: 2394.303<br />density: 0.0025611251","Condition: Complex<br />Condition: Complex<br />RT: 2392.941<br />density: 0.0025718032","Condition: Complex<br />Condition: Complex<br />RT: 2391.579<br />density: 0.0025823182","Condition: Complex<br />Condition: Complex<br />RT: 2390.217<br />density: 0.0025923257","Condition: Complex<br />Condition: Complex<br />RT: 2388.855<br />density: 0.0026021207","Condition: Complex<br />Condition: Complex<br />RT: 2387.493<br />density: 0.0026115595","Condition: Complex<br />Condition: Complex<br />RT: 2386.131<br />density: 0.0026205782","Condition: Complex<br />Condition: Complex<br />RT: 2384.769<br />density: 0.0026294013","Condition: Complex<br />Condition: Complex<br />RT: 2383.407<br />density: 0.0026376031","Condition: Complex<br />Condition: Complex<br />RT: 2382.045<br />density: 0.0026455757","Condition: Complex<br />Condition: Complex<br />RT: 2380.683<br />density: 0.0026531124","Condition: Complex<br />Condition: Complex<br />RT: 2379.321<br />density: 0.0026601852","Condition: Complex<br />Condition: Complex<br />RT: 2377.959<br />density: 0.0026670279","Condition: Complex<br />Condition: Complex<br />RT: 2376.597<br />density: 0.0026731553","Condition: Complex<br />Condition: Complex<br />RT: 2375.235<br />density: 0.0026790415","Condition: Complex<br />Condition: Complex<br />RT: 2373.873<br />density: 0.0026844177","Condition: Complex<br />Condition: Complex<br />RT: 2372.511<br />density: 0.0026893027","Condition: Complex<br />Condition: Complex<br />RT: 2371.149<br />density: 0.0026939109","Condition: Complex<br />Condition: Complex<br />RT: 2369.787<br />density: 0.0026977600","Condition: Complex<br />Condition: Complex<br />RT: 2368.425<br />density: 0.0027013491","Condition: Complex<br />Condition: Complex<br />RT: 2367.063<br />density: 0.0027043641","Condition: Complex<br />Condition: Complex<br />RT: 2365.701<br />density: 0.0027068782","Condition: Complex<br />Condition: Complex<br />RT: 2364.339<br />density: 0.0027090733","Condition: Complex<br />Condition: Complex<br />RT: 2362.977<br />density: 0.0027104912","Condition: Complex<br />Condition: Complex<br />RT: 2361.614<br />density: 0.0027116375","Condition: Complex<br />Condition: Complex<br />RT: 2360.252<br />density: 0.0027121604","Condition: Complex<br />Condition: Complex<br />RT: 2358.890<br />density: 0.0027121907","Condition: Complex<br />Condition: Complex<br />RT: 2357.528<br />density: 0.0027118671","Condition: Complex<br />Condition: Complex<br />RT: 2356.166<br />density: 0.0027107742","Condition: Complex<br />Condition: Complex<br />RT: 2354.804<br />density: 0.0027094064","Condition: Complex<br />Condition: Complex<br />RT: 2353.442<br />density: 0.0027073842","Condition: Complex<br />Condition: Complex<br />RT: 2352.080<br />density: 0.0027048940","Condition: Complex<br />Condition: Complex<br />RT: 2350.718<br />density: 0.0027020258","Condition: Complex<br />Condition: Complex<br />RT: 2349.356<br />density: 0.0026984210","Condition: Complex<br />Condition: Complex<br />RT: 2347.994<br />density: 0.0026945462","Condition: Complex<br />Condition: Complex<br />RT: 2346.632<br />density: 0.0026900074","Condition: Complex<br />Condition: Complex<br />RT: 2345.270<br />density: 0.0026850393","Condition: Complex<br />Condition: Complex<br />RT: 2343.908<br />density: 0.0026796819","Condition: Complex<br />Condition: Complex<br />RT: 2342.546<br />density: 0.0026736429","Condition: Complex<br />Condition: Complex<br />RT: 2341.184<br />density: 0.0026673469","Condition: Complex<br />Condition: Complex<br />RT: 2339.822<br />density: 0.0026603999","Condition: Complex<br />Condition: Complex<br />RT: 2338.460<br />density: 0.0026530737","Condition: Complex<br />Condition: Complex<br />RT: 2337.098<br />density: 0.0026453613","Condition: Complex<br />Condition: Complex<br />RT: 2335.736<br />density: 0.0026370405","Condition: Complex<br />Condition: Complex<br />RT: 2334.374<br />density: 0.0026284830","Condition: Complex<br />Condition: Complex<br />RT: 2333.012<br />density: 0.0026193108","Condition: Complex<br />Condition: Complex<br />RT: 2331.650<br />density: 0.0026098167","Condition: Complex<br />Condition: Complex<br />RT: 2330.288<br />density: 0.0025999548","Condition: Complex<br />Condition: Complex<br />RT: 2328.926<br />density: 0.0025895711","Condition: Complex<br />Condition: Complex<br />RT: 2327.564<br />density: 0.0025789774","Condition: Complex<br />Condition: Complex<br />RT: 2326.202<br />density: 0.0025678269","Condition: Complex<br />Condition: Complex<br />RT: 2324.840<br />density: 0.0025564157","Condition: Complex<br />Condition: Complex<br />RT: 2323.477<br />density: 0.0025446699","Condition: Complex<br />Condition: Complex<br />RT: 2322.115<br />density: 0.0025324971","Condition: Complex<br />Condition: Complex<br />RT: 2320.753<br />density: 0.0025201458","Condition: Complex<br />Condition: Complex<br />RT: 2319.391<br />density: 0.0025073146","Condition: Complex<br />Condition: Complex<br />RT: 2318.029<br />density: 0.0024942840","Condition: Complex<br />Condition: Complex<br />RT: 2316.667<br />density: 0.0024809652","Condition: Complex<br />Condition: Complex<br />RT: 2315.305<br />density: 0.0024673168","Condition: Complex<br />Condition: Complex<br />RT: 2313.943<br />density: 0.0024535250","Condition: Complex<br />Condition: Complex<br />RT: 2312.581<br />density: 0.0024393452","Condition: Complex<br />Condition: Complex<br />RT: 2311.219<br />density: 0.0024250238","Condition: Complex<br />Condition: Complex<br />RT: 2309.857<br />density: 0.0024104716","Condition: Complex<br />Condition: Complex<br />RT: 2308.495<br />density: 0.0023956847","Condition: Complex<br />Condition: Complex<br />RT: 2307.133<br />density: 0.0023807909","Condition: Complex<br />Condition: Complex<br />RT: 2305.771<br />density: 0.0023656109","Condition: Complex<br />Condition: Complex<br />RT: 2304.409<br />density: 0.0023503410","Condition: Complex<br />Condition: Complex<br />RT: 2303.047<br />density: 0.0023349053","Condition: Complex<br />Condition: Complex<br />RT: 2301.685<br />density: 0.0023193226","Condition: Complex<br />Condition: Complex<br />RT: 2300.323<br />density: 0.0023036692","Condition: Complex<br />Condition: Complex<br />RT: 2298.961<br />density: 0.0022878357","Condition: Complex<br />Condition: Complex<br />RT: 2297.599<br />density: 0.0022719557","Condition: Complex<br />Condition: Complex<br />RT: 2296.237<br />density: 0.0022559783","Condition: Complex<br />Condition: Complex<br />RT: 2294.875<br />density: 0.0022399308","Condition: Complex<br />Condition: Complex<br />RT: 2293.513<br />density: 0.0022238450","Condition: Complex<br />Condition: Complex<br />RT: 2292.151<br />density: 0.0022076869","Condition: Complex<br />Condition: Complex<br />RT: 2290.789<br />density: 0.0021915142","Condition: Complex<br />Condition: Complex<br />RT: 2289.427<br />density: 0.0021753118","Condition: Complex<br />Condition: Complex<br />RT: 2288.065<br />density: 0.0021591025","Condition: Complex<br />Condition: Complex<br />RT: 2286.703<br />density: 0.0021428890","Condition: Complex<br />Condition: Complex<br />RT: 2285.341<br />density: 0.0021266921","Condition: Complex<br />Condition: Complex<br />RT: 2283.978<br />density: 0.0021105082","Condition: Complex<br />Condition: Complex<br />RT: 2282.616<br />density: 0.0020943572","Condition: Complex<br />Condition: Complex<br />RT: 2281.254<br />density: 0.0020782472","Condition: Complex<br />Condition: Complex<br />RT: 2279.892<br />density: 0.0020621659","Condition: Complex<br />Condition: Complex<br />RT: 2278.530<br />density: 0.0020461690","Condition: Complex<br />Condition: Complex<br />RT: 2277.168<br />density: 0.0020302068","Condition: Complex<br />Condition: Complex<br />RT: 2275.806<br />density: 0.0020143310","Condition: Complex<br />Condition: Complex<br />RT: 2274.444<br />density: 0.0019985286","Condition: Complex<br />Condition: Complex<br />RT: 2273.082<br />density: 0.0019827840","Condition: Complex<br />Condition: Complex<br />RT: 2271.720<br />density: 0.0019671693","Condition: Complex<br />Condition: Complex<br />RT: 2270.358<br />density: 0.0019516049","Condition: Complex<br />Condition: Complex<br />RT: 2268.996<br />density: 0.0019361677","Condition: Complex<br />Condition: Complex<br />RT: 2267.634<br />density: 0.0019208215","Condition: Complex<br />Condition: Complex<br />RT: 2266.272<br />density: 0.0019055557","Condition: Complex<br />Condition: Complex<br />RT: 2264.910<br />density: 0.0018904438","Condition: Complex<br />Condition: Complex<br />RT: 2263.548<br />density: 0.0018753913","Condition: Complex<br />Condition: Complex<br />RT: 2262.186<br />density: 0.0018604919","Condition: Complex<br />Condition: Complex<br />RT: 2260.824<br />density: 0.0018456881","Condition: Complex<br />Condition: Complex<br />RT: 2259.462<br />density: 0.0018309790","Condition: Complex<br />Condition: Complex<br />RT: 2258.100<br />density: 0.0018164285","Condition: Complex<br />Condition: Complex<br />RT: 2256.738<br />density: 0.0018019401","Condition: Complex<br />Condition: Complex<br />RT: 2255.376<br />density: 0.0017876147","Condition: Complex<br />Condition: Complex<br />RT: 2254.014<br />density: 0.0017733787","Condition: Complex<br />Condition: Complex<br />RT: 2252.652<br />density: 0.0017592424","Condition: Complex<br />Condition: Complex<br />RT: 2251.290<br />density: 0.0017452532","Condition: Complex<br />Condition: Complex<br />RT: 2249.928<br />density: 0.0017313232","Condition: Complex<br />Condition: Complex<br />RT: 2248.566<br />density: 0.0017175500","Condition: Complex<br />Condition: Complex<br />RT: 2247.204<br />density: 0.0017038527","Condition: Complex<br />Condition: Complex<br />RT: 2245.841<br />density: 0.0016902502","Condition: Complex<br />Condition: Complex<br />RT: 2244.479<br />density: 0.0016767715","Condition: Complex<br />Condition: Complex<br />RT: 2243.117<br />density: 0.0016633440","Condition: Complex<br />Condition: Complex<br />RT: 2241.755<br />density: 0.0016500533","Condition: Complex<br />Condition: Complex<br />RT: 2240.393<br />density: 0.0016368202","Condition: Complex<br />Condition: Complex<br />RT: 2239.031<br />density: 0.0016236681","Condition: Complex<br />Condition: Complex<br />RT: 2237.669<br />density: 0.0016106090","Condition: Complex<br />Condition: Complex<br />RT: 2236.307<br />density: 0.0015975898","Condition: Complex<br />Condition: Complex<br />RT: 2234.945<br />density: 0.0015846757","Condition: Complex<br />Condition: Complex<br />RT: 2233.583<br />density: 0.0015717994","Condition: Complex<br />Condition: Complex<br />RT: 2232.221<br />density: 0.0015589832","Condition: Complex<br />Condition: Complex<br />RT: 2230.859<br />density: 0.0015462260","Condition: Complex<br />Condition: Complex<br />RT: 2229.497<br />density: 0.0015334954","Condition: Complex<br />Condition: Complex<br />RT: 2228.135<br />density: 0.0015208306","Condition: Complex<br />Condition: Complex<br />RT: 2226.773<br />density: 0.0015081849","Condition: Complex<br />Condition: Complex<br />RT: 2225.411<br />density: 0.0014955735","Condition: Complex<br />Condition: Complex<br />RT: 2224.049<br />density: 0.0014829883","Condition: Complex<br />Condition: Complex<br />RT: 2222.687<br />density: 0.0014704155","Condition: Complex<br />Condition: Complex<br />RT: 2221.325<br />density: 0.0014578664","Condition: Complex<br />Condition: Complex<br />RT: 2219.963<br />density: 0.0014453206","Condition: Complex<br />Condition: Complex<br />RT: 2218.601<br />density: 0.0014327814","Condition: Complex<br />Condition: Complex<br />RT: 2217.239<br />density: 0.0014202399","Condition: Complex<br />Condition: Complex<br />RT: 2215.877<br />density: 0.0014076970","Condition: Complex<br />Condition: Complex<br />RT: 2214.515<br />density: 0.0013951383","Condition: Complex<br />Condition: Complex<br />RT: 2213.153<br />density: 0.0013825708","Condition: Complex<br />Condition: Complex<br />RT: 2211.791<br />density: 0.0013699837","Condition: Complex<br />Condition: Complex<br />RT: 2210.429<br />density: 0.0013573723","Condition: Complex<br />Condition: Complex<br />RT: 2209.067<br />density: 0.0013447463","Condition: Complex<br />Condition: Complex<br />RT: 2207.705<br />density: 0.0013320745","Condition: Complex<br />Condition: Complex<br />RT: 2206.342<br />density: 0.0013193846","Condition: Complex<br />Condition: Complex<br />RT: 2204.980<br />density: 0.0013066534","Condition: Complex<br />Condition: Complex<br />RT: 2203.618<br />density: 0.0012938841","Condition: Complex<br />Condition: Complex<br />RT: 2202.256<br />density: 0.0012810889","Condition: Complex<br />Condition: Complex<br />RT: 2200.894<br />density: 0.0012682296","Condition: Complex<br />Condition: Complex<br />RT: 2199.532<br />density: 0.0012553468","Condition: Complex<br />Condition: Complex<br />RT: 2198.170<br />density: 0.0012424078","Condition: Complex<br />Condition: Complex<br />RT: 2196.808<br />density: 0.0012294253","Condition: Complex<br />Condition: Complex<br />RT: 2195.446<br />density: 0.0012164095","Condition: Complex<br />Condition: Complex<br />RT: 2194.084<br />density: 0.0012033238","Condition: Complex<br />Condition: Complex<br />RT: 2192.722<br />density: 0.0011902128","Condition: Complex<br />Condition: Complex<br />RT: 2191.360<br />density: 0.0011770401","Condition: Complex<br />Condition: Complex<br />RT: 2189.998<br />density: 0.0011638260","Condition: Complex<br />Condition: Complex<br />RT: 2188.636<br />density: 0.0011505763","Condition: Complex<br />Condition: Complex<br />RT: 2187.274<br />density: 0.0011372627","Condition: Complex<br />Condition: Complex<br />RT: 2185.912<br />density: 0.0011239259","Condition: Complex<br />Condition: Complex<br />RT: 2184.550<br />density: 0.0011105320","Condition: Complex<br />Condition: Complex<br />RT: 2183.188<br />density: 0.0010971052","Condition: Complex<br />Condition: Complex<br />RT: 2181.826<br />density: 0.0010836466","Condition: Complex<br />Condition: Complex<br />RT: 2180.464<br />density: 0.0010701399","Condition: Complex<br />Condition: Complex<br />RT: 2179.102<br />density: 0.0010566156","Condition: Complex<br />Condition: Complex<br />RT: 2177.740<br />density: 0.0010430491","Condition: Complex<br />Condition: Complex<br />RT: 2176.378<br />density: 0.0010294628","Condition: Complex<br />Condition: Complex<br />RT: 2175.016<br />density: 0.0010158550","Condition: Complex<br />Condition: Complex<br />RT: 2173.654<br />density: 0.0010022220","Condition: Complex<br />Condition: Complex<br />RT: 2172.292<br />density: 0.0009885802","Condition: Complex<br />Condition: Complex<br />RT: 2170.930<br />density: 0.0009749203","Condition: Complex<br />Condition: Complex<br />RT: 2169.568<br />density: 0.0009612563","Condition: Complex<br />Condition: Complex<br />RT: 2168.205<br />density: 0.0009475872","Condition: Complex<br />Condition: Complex<br />RT: 2166.843<br />density: 0.0009339203","Condition: Complex<br />Condition: Complex<br />RT: 2165.481<br />density: 0.0009202555","Condition: Complex<br />Condition: Complex<br />RT: 2164.119<br />density: 0.0009066047","Condition: Complex<br />Condition: Complex<br />RT: 2162.757<br />density: 0.0008929659","Condition: Complex<br />Condition: Complex<br />RT: 2161.395<br />density: 0.0008793435","Condition: Complex<br />Condition: Complex<br />RT: 2160.033<br />density: 0.0008657523","Condition: Complex<br />Condition: Complex<br />RT: 2158.671<br />density: 0.0008521756","Condition: Complex<br />Condition: Complex<br />RT: 2157.309<br />density: 0.0008386502","Condition: Complex<br />Condition: Complex<br />RT: 2155.947<br />density: 0.0008251520","Condition: Complex<br />Condition: Complex<br />RT: 2154.585<br />density: 0.0008116955","Condition: Complex<br />Condition: Complex<br />RT: 2153.223<br />density: 0.0007982981","Condition: Complex<br />Condition: Complex<br />RT: 2151.861<br />density: 0.0007849279","Condition: Complex<br />Condition: Complex<br />RT: 2150.499<br />density: 0.0007716496","Condition: Complex<br />Condition: Complex<br />RT: 2149.137<br />density: 0.0007584110","Condition: Complex<br />Condition: Complex<br />RT: 2147.775<br />density: 0.0007452416","Condition: Complex<br />Condition: Complex<br />RT: 2146.413<br />density: 0.0007321561","Condition: Complex<br />Condition: Complex<br />RT: 2145.051<br />density: 0.0007191102","Condition: Complex<br />Condition: Complex<br />RT: 2143.689<br />density: 0.0007061970","Condition: Complex<br />Condition: Complex<br />RT: 2142.327<br />density: 0.0006933329","Condition: Complex<br />Condition: Complex<br />RT: 2140.965<br />density: 0.0006805659","Condition: Complex<br />Condition: Complex<br />RT: 2139.603<br />density: 0.0006679030","Condition: Complex<br />Condition: Complex<br />RT: 2138.241<br />density: 0.0006552938","Condition: Complex<br />Condition: Complex<br />RT: 2136.879<br />density: 0.0006428503","Condition: Complex<br />Condition: Complex<br />RT: 2135.517<br />density: 0.0006304645","Condition: Complex<br />Condition: Complex<br />RT: 2134.155<br />density: 0.0006182026","Condition: Complex<br />Condition: Complex<br />RT: 2132.793<br />density: 0.0006060595","Condition: Complex<br />Condition: Complex<br />RT: 2131.431<br />density: 0.0005939859","Condition: Complex<br />Condition: Complex<br />RT: 2130.068<br />density: 0.0005821004","Condition: Complex<br />Condition: Complex<br />RT: 2128.706<br />density: 0.0005702809","Condition: Complex<br />Condition: Complex<br />RT: 2127.344<br />density: 0.0005586096","Condition: Complex<br />Condition: Complex<br />RT: 2125.982<br />density: 0.0005470661","Condition: Complex<br />Condition: Complex<br />RT: 2124.620<br />density: 0.0005356072","Condition: Complex<br />Condition: Complex<br />RT: 2123.258<br />density: 0.0005243510","Condition: Complex<br />Condition: Complex<br />RT: 2121.896<br />density: 0.0005131671","Condition: Complex<br />Condition: Complex<br />RT: 2120.534<br />density: 0.0005021519","Condition: Complex<br />Condition: Complex<br />RT: 2119.172<br />density: 0.0004912684","Condition: Complex<br />Condition: Complex<br />RT: 2117.810<br />density: 0.0004804830","Condition: Complex<br />Condition: Complex<br />RT: 2116.448<br />density: 0.0004699075","Condition: Complex<br />Condition: Complex<br />RT: 2115.086<br />density: 0.0004594085","Condition: Complex<br />Condition: Complex<br />RT: 2113.724<br />density: 0.0004490946","Condition: Complex<br />Condition: Complex<br />RT: 2112.362<br />density: 0.0004389116","Condition: Complex<br />Condition: Complex<br />RT: 2111.000<br />density: 0.0004288382","Condition: Complex<br />Condition: Complex<br />RT: 2111.000<br />density: 0.0004288382"],"type":"scatter","mode":"lines","line":{"width":1.88976377952756,"color":"rgba(51,51,51,1)","dash":"solid"},"fill":"toself","fillcolor":"rgba(127,201,127,1)","hoveron":"points","name":"Complex","legendgroup":"Complex","showlegend":true,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null},{"x":[1671,1672.30528375734,1673.61056751468,1674.91585127202,1676.22113502935,1677.52641878669,1678.83170254403,1680.13698630137,1681.44227005871,1682.74755381605,1684.05283757339,1685.35812133072,1686.66340508806,1687.9686888454,1689.27397260274,1690.57925636008,1691.88454011742,1693.18982387476,1694.49510763209,1695.80039138943,1697.10567514677,1698.41095890411,1699.71624266145,1701.02152641879,1702.32681017613,1703.63209393346,1704.9373776908,1706.24266144814,1707.54794520548,1708.85322896282,1710.15851272016,1711.4637964775,1712.76908023483,1714.07436399217,1715.37964774951,1716.68493150685,1717.99021526419,1719.29549902153,1720.60078277886,1721.9060665362,1723.21135029354,1724.51663405088,1725.82191780822,1727.12720156556,1728.4324853229,1729.73776908023,1731.04305283757,1732.34833659491,1733.65362035225,1734.95890410959,1736.26418786693,1737.56947162427,1738.8747553816,1740.18003913894,1741.48532289628,1742.79060665362,1744.09589041096,1745.4011741683,1746.70645792564,1748.01174168297,1749.31702544031,1750.62230919765,1751.92759295499,1753.23287671233,1754.53816046967,1755.84344422701,1757.14872798434,1758.45401174168,1759.75929549902,1761.06457925636,1762.3698630137,1763.67514677104,1764.98043052838,1766.28571428571,1767.59099804305,1768.89628180039,1770.20156555773,1771.50684931507,1772.81213307241,1774.11741682975,1775.42270058708,1776.72798434442,1778.03326810176,1779.3385518591,1780.64383561644,1781.94911937378,1783.25440313112,1784.55968688845,1785.86497064579,1787.17025440313,1788.47553816047,1789.78082191781,1791.08610567515,1792.39138943249,1793.69667318982,1795.00195694716,1796.3072407045,1797.61252446184,1798.91780821918,1800.22309197652,1801.52837573386,1802.83365949119,1804.13894324853,1805.44422700587,1806.74951076321,1808.05479452055,1809.36007827789,1810.66536203523,1811.97064579256,1813.2759295499,1814.58121330724,1815.88649706458,1817.19178082192,1818.49706457926,1819.80234833659,1821.10763209393,1822.41291585127,1823.71819960861,1825.02348336595,1826.32876712329,1827.63405088063,1828.93933463796,1830.2446183953,1831.54990215264,1832.85518590998,1834.16046966732,1835.46575342466,1836.771037182,1838.07632093933,1839.38160469667,1840.68688845401,1841.99217221135,1843.29745596869,1844.60273972603,1845.90802348337,1847.2133072407,1848.51859099804,1849.82387475538,1851.12915851272,1852.43444227006,1853.7397260274,1855.04500978474,1856.35029354207,1857.65557729941,1858.96086105675,1860.26614481409,1861.57142857143,1862.87671232877,1864.18199608611,1865.48727984344,1866.79256360078,1868.09784735812,1869.40313111546,1870.7084148728,1872.01369863014,1873.31898238748,1874.62426614481,1875.92954990215,1877.23483365949,1878.54011741683,1879.84540117417,1881.15068493151,1882.45596868885,1883.76125244618,1885.06653620352,1886.37181996086,1887.6771037182,1888.98238747554,1890.28767123288,1891.59295499022,1892.89823874755,1894.20352250489,1895.50880626223,1896.81409001957,1898.11937377691,1899.42465753425,1900.72994129159,1902.03522504892,1903.34050880626,1904.6457925636,1905.95107632094,1907.25636007828,1908.56164383562,1909.86692759296,1911.17221135029,1912.47749510763,1913.78277886497,1915.08806262231,1916.39334637965,1917.69863013699,1919.00391389432,1920.30919765166,1921.614481409,1922.91976516634,1924.22504892368,1925.53033268102,1926.83561643836,1928.14090019569,1929.44618395303,1930.75146771037,1932.05675146771,1933.36203522505,1934.66731898239,1935.97260273973,1937.27788649706,1938.5831702544,1939.88845401174,1941.19373776908,1942.49902152642,1943.80430528376,1945.1095890411,1946.41487279843,1947.72015655577,1949.02544031311,1950.33072407045,1951.63600782779,1952.94129158513,1954.24657534247,1955.5518590998,1956.85714285714,1958.16242661448,1959.46771037182,1960.77299412916,1962.0782778865,1963.38356164384,1964.68884540117,1965.99412915851,1967.29941291585,1968.60469667319,1969.90998043053,1971.21526418787,1972.52054794521,1973.82583170254,1975.13111545988,1976.43639921722,1977.74168297456,1979.0469667319,1980.35225048924,1981.65753424658,1982.96281800391,1984.26810176125,1985.57338551859,1986.87866927593,1988.18395303327,1989.48923679061,1990.79452054795,1992.09980430528,1993.40508806262,1994.71037181996,1996.0156555773,1997.32093933464,1998.62622309198,1999.93150684932,2001.23679060665,2002.54207436399,2003.84735812133,2005.15264187867,2006.45792563601,2007.76320939335,2009.06849315068,2010.37377690802,2011.67906066536,2012.9843444227,2014.28962818004,2015.59491193738,2016.90019569472,2018.20547945205,2019.51076320939,2020.81604696673,2022.12133072407,2023.42661448141,2024.73189823875,2026.03718199609,2027.34246575342,2028.64774951076,2029.9530332681,2031.25831702544,2032.56360078278,2033.86888454012,2035.17416829746,2036.47945205479,2037.78473581213,2039.09001956947,2040.39530332681,2041.70058708415,2043.00587084149,2044.31115459883,2045.61643835616,2046.9217221135,2048.22700587084,2049.53228962818,2050.83757338552,2052.14285714286,2053.4481409002,2054.75342465753,2056.05870841487,2057.36399217221,2058.66927592955,2059.97455968689,2061.27984344423,2062.58512720157,2063.8904109589,2065.19569471624,2066.50097847358,2067.80626223092,2069.11154598826,2070.4168297456,2071.72211350294,2073.02739726027,2074.33268101761,2075.63796477495,2076.94324853229,2078.24853228963,2079.55381604697,2080.85909980431,2082.16438356164,2083.46966731898,2084.77495107632,2086.08023483366,2087.385518591,2088.69080234834,2089.99608610568,2091.30136986301,2092.60665362035,2093.91193737769,2095.21722113503,2096.52250489237,2097.82778864971,2099.13307240704,2100.43835616438,2101.74363992172,2103.04892367906,2104.3542074364,2105.65949119374,2106.96477495108,2108.27005870842,2109.57534246575,2110.88062622309,2112.18590998043,2113.49119373777,2114.79647749511,2116.10176125245,2117.40704500978,2118.71232876712,2120.01761252446,2121.3228962818,2122.62818003914,2123.93346379648,2125.23874755382,2126.54403131115,2127.84931506849,2129.15459882583,2130.45988258317,2131.76516634051,2133.07045009785,2134.37573385519,2135.68101761252,2136.98630136986,2138.2915851272,2139.59686888454,2140.90215264188,2142.20743639922,2143.51272015656,2144.81800391389,2146.12328767123,2147.42857142857,2148.73385518591,2150.03913894325,2151.34442270059,2152.64970645793,2153.95499021526,2155.2602739726,2156.56555772994,2157.87084148728,2159.17612524462,2160.48140900196,2161.7866927593,2163.09197651663,2164.39726027397,2165.70254403131,2167.00782778865,2168.31311154599,2169.61839530333,2170.92367906067,2172.228962818,2173.53424657534,2174.83953033268,2176.14481409002,2177.45009784736,2178.7553816047,2180.06066536204,2181.36594911937,2182.67123287671,2183.97651663405,2185.28180039139,2186.58708414873,2187.89236790607,2189.1976516634,2190.50293542074,2191.80821917808,2193.11350293542,2194.41878669276,2195.7240704501,2197.02935420744,2198.33463796478,2199.63992172211,2200.94520547945,2202.25048923679,2203.55577299413,2204.86105675147,2206.16634050881,2207.47162426614,2208.77690802348,2210.08219178082,2211.38747553816,2212.6927592955,2213.99804305284,2215.30332681018,2216.60861056751,2217.91389432485,2219.21917808219,2220.52446183953,2221.82974559687,2223.13502935421,2224.44031311155,2225.74559686888,2227.05088062622,2228.35616438356,2229.6614481409,2230.96673189824,2232.27201565558,2233.57729941292,2234.88258317025,2236.18786692759,2237.49315068493,2238.79843444227,2240.10371819961,2241.40900195695,2242.71428571429,2244.01956947162,2245.32485322896,2246.6301369863,2247.93542074364,2249.24070450098,2250.54598825832,2251.85127201566,2253.15655577299,2254.46183953033,2255.76712328767,2257.07240704501,2258.37769080235,2259.68297455969,2260.98825831703,2262.29354207436,2263.5988258317,2264.90410958904,2266.20939334638,2267.51467710372,2268.81996086106,2270.1252446184,2271.43052837573,2272.73581213307,2274.04109589041,2275.34637964775,2276.65166340509,2277.95694716243,2279.26223091976,2280.5675146771,2281.87279843444,2283.17808219178,2284.48336594912,2285.78864970646,2287.0939334638,2288.39921722114,2289.70450097847,2291.00978473581,2292.31506849315,2293.62035225049,2294.92563600783,2296.23091976517,2297.5362035225,2298.84148727984,2300.14677103718,2301.45205479452,2302.75733855186,2304.0626223092,2305.36790606654,2306.67318982387,2307.97847358121,2309.28375733855,2310.58904109589,2311.89432485323,2313.19960861057,2314.50489236791,2315.81017612524,2317.11545988258,2318.42074363992,2319.72602739726,2321.0313111546,2322.33659491194,2323.64187866928,2324.94716242661,2326.25244618395,2327.55772994129,2328.86301369863,2330.16829745597,2331.47358121331,2332.77886497065,2334.08414872798,2335.38943248532,2336.69471624266,2338,2338,2336.69471624266,2335.38943248532,2334.08414872798,2332.77886497065,2331.47358121331,2330.16829745597,2328.86301369863,2327.55772994129,2326.25244618395,2324.94716242661,2323.64187866928,2322.33659491194,2321.0313111546,2319.72602739726,2318.42074363992,2317.11545988258,2315.81017612524,2314.50489236791,2313.19960861057,2311.89432485323,2310.58904109589,2309.28375733855,2307.97847358121,2306.67318982387,2305.36790606654,2304.0626223092,2302.75733855186,2301.45205479452,2300.14677103718,2298.84148727984,2297.5362035225,2296.23091976517,2294.92563600783,2293.62035225049,2292.31506849315,2291.00978473581,2289.70450097847,2288.39921722114,2287.0939334638,2285.78864970646,2284.48336594912,2283.17808219178,2281.87279843444,2280.5675146771,2279.26223091976,2277.95694716243,2276.65166340509,2275.34637964775,2274.04109589041,2272.73581213307,2271.43052837573,2270.1252446184,2268.81996086106,2267.51467710372,2266.20939334638,2264.90410958904,2263.5988258317,2262.29354207436,2260.98825831703,2259.68297455969,2258.37769080235,2257.07240704501,2255.76712328767,2254.46183953033,2253.15655577299,2251.85127201566,2250.54598825832,2249.24070450098,2247.93542074364,2246.6301369863,2245.32485322896,2244.01956947162,2242.71428571429,2241.40900195695,2240.10371819961,2238.79843444227,2237.49315068493,2236.18786692759,2234.88258317025,2233.57729941292,2232.27201565558,2230.96673189824,2229.6614481409,2228.35616438356,2227.05088062622,2225.74559686888,2224.44031311155,2223.13502935421,2221.82974559687,2220.52446183953,2219.21917808219,2217.91389432485,2216.60861056751,2215.30332681018,2213.99804305284,2212.6927592955,2211.38747553816,2210.08219178082,2208.77690802348,2207.47162426614,2206.16634050881,2204.86105675147,2203.55577299413,2202.25048923679,2200.94520547945,2199.63992172211,2198.33463796478,2197.02935420744,2195.7240704501,2194.41878669276,2193.11350293542,2191.80821917808,2190.50293542074,2189.1976516634,2187.89236790607,2186.58708414873,2185.28180039139,2183.97651663405,2182.67123287671,2181.36594911937,2180.06066536204,2178.7553816047,2177.45009784736,2176.14481409002,2174.83953033268,2173.53424657534,2172.228962818,2170.92367906067,2169.61839530333,2168.31311154599,2167.00782778865,2165.70254403131,2164.39726027397,2163.09197651663,2161.7866927593,2160.48140900196,2159.17612524462,2157.87084148728,2156.56555772994,2155.2602739726,2153.95499021526,2152.64970645793,2151.34442270059,2150.03913894325,2148.73385518591,2147.42857142857,2146.12328767123,2144.81800391389,2143.51272015656,2142.20743639922,2140.90215264188,2139.59686888454,2138.2915851272,2136.98630136986,2135.68101761252,2134.37573385519,2133.07045009785,2131.76516634051,2130.45988258317,2129.15459882583,2127.84931506849,2126.54403131115,2125.23874755382,2123.93346379648,2122.62818003914,2121.3228962818,2120.01761252446,2118.71232876712,2117.40704500978,2116.10176125245,2114.79647749511,2113.49119373777,2112.18590998043,2110.88062622309,2109.57534246575,2108.27005870842,2106.96477495108,2105.65949119374,2104.3542074364,2103.04892367906,2101.74363992172,2100.43835616438,2099.13307240704,2097.82778864971,2096.52250489237,2095.21722113503,2093.91193737769,2092.60665362035,2091.30136986301,2089.99608610568,2088.69080234834,2087.385518591,2086.08023483366,2084.77495107632,2083.46966731898,2082.16438356164,2080.85909980431,2079.55381604697,2078.24853228963,2076.94324853229,2075.63796477495,2074.33268101761,2073.02739726027,2071.72211350294,2070.4168297456,2069.11154598826,2067.80626223092,2066.50097847358,2065.19569471624,2063.8904109589,2062.58512720157,2061.27984344423,2059.97455968689,2058.66927592955,2057.36399217221,2056.05870841487,2054.75342465753,2053.4481409002,2052.14285714286,2050.83757338552,2049.53228962818,2048.22700587084,2046.9217221135,2045.61643835616,2044.31115459883,2043.00587084149,2041.70058708415,2040.39530332681,2039.09001956947,2037.78473581213,2036.47945205479,2035.17416829746,2033.86888454012,2032.56360078278,2031.25831702544,2029.9530332681,2028.64774951076,2027.34246575342,2026.03718199609,2024.73189823875,2023.42661448141,2022.12133072407,2020.81604696673,2019.51076320939,2018.20547945205,2016.90019569472,2015.59491193738,2014.28962818004,2012.9843444227,2011.67906066536,2010.37377690802,2009.06849315068,2007.76320939335,2006.45792563601,2005.15264187867,2003.84735812133,2002.54207436399,2001.23679060665,1999.93150684932,1998.62622309198,1997.32093933464,1996.0156555773,1994.71037181996,1993.40508806262,1992.09980430528,1990.79452054795,1989.48923679061,1988.18395303327,1986.87866927593,1985.57338551859,1984.26810176125,1982.96281800391,1981.65753424658,1980.35225048924,1979.0469667319,1977.74168297456,1976.43639921722,1975.13111545988,1973.82583170254,1972.52054794521,1971.21526418787,1969.90998043053,1968.60469667319,1967.29941291585,1965.99412915851,1964.68884540117,1963.38356164384,1962.0782778865,1960.77299412916,1959.46771037182,1958.16242661448,1956.85714285714,1955.5518590998,1954.24657534247,1952.94129158513,1951.63600782779,1950.33072407045,1949.02544031311,1947.72015655577,1946.41487279843,1945.1095890411,1943.80430528376,1942.49902152642,1941.19373776908,1939.88845401174,1938.5831702544,1937.27788649706,1935.97260273973,1934.66731898239,1933.36203522505,1932.05675146771,1930.75146771037,1929.44618395303,1928.14090019569,1926.83561643836,1925.53033268102,1924.22504892368,1922.91976516634,1921.614481409,1920.30919765166,1919.00391389432,1917.69863013699,1916.39334637965,1915.08806262231,1913.78277886497,1912.47749510763,1911.17221135029,1909.86692759296,1908.56164383562,1907.25636007828,1905.95107632094,1904.6457925636,1903.34050880626,1902.03522504892,1900.72994129159,1899.42465753425,1898.11937377691,1896.81409001957,1895.50880626223,1894.20352250489,1892.89823874755,1891.59295499022,1890.28767123288,1888.98238747554,1887.6771037182,1886.37181996086,1885.06653620352,1883.76125244618,1882.45596868885,1881.15068493151,1879.84540117417,1878.54011741683,1877.23483365949,1875.92954990215,1874.62426614481,1873.31898238748,1872.01369863014,1870.7084148728,1869.40313111546,1868.09784735812,1866.79256360078,1865.48727984344,1864.18199608611,1862.87671232877,1861.57142857143,1860.26614481409,1858.96086105675,1857.65557729941,1856.35029354207,1855.04500978474,1853.7397260274,1852.43444227006,1851.12915851272,1849.82387475538,1848.51859099804,1847.2133072407,1845.90802348337,1844.60273972603,1843.29745596869,1841.99217221135,1840.68688845401,1839.38160469667,1838.07632093933,1836.771037182,1835.46575342466,1834.16046966732,1832.85518590998,1831.54990215264,1830.2446183953,1828.93933463796,1827.63405088063,1826.32876712329,1825.02348336595,1823.71819960861,1822.41291585127,1821.10763209393,1819.80234833659,1818.49706457926,1817.19178082192,1815.88649706458,1814.58121330724,1813.2759295499,1811.97064579256,1810.66536203523,1809.36007827789,1808.05479452055,1806.74951076321,1805.44422700587,1804.13894324853,1802.83365949119,1801.52837573386,1800.22309197652,1798.91780821918,1797.61252446184,1796.3072407045,1795.00195694716,1793.69667318982,1792.39138943249,1791.08610567515,1789.78082191781,1788.47553816047,1787.17025440313,1785.86497064579,1784.55968688845,1783.25440313112,1781.94911937378,1780.64383561644,1779.3385518591,1778.03326810176,1776.72798434442,1775.42270058708,1774.11741682975,1772.81213307241,1771.50684931507,1770.20156555773,1768.89628180039,1767.59099804305,1766.28571428571,1764.98043052838,1763.67514677104,1762.3698630137,1761.06457925636,1759.75929549902,1758.45401174168,1757.14872798434,1755.84344422701,1754.53816046967,1753.23287671233,1751.92759295499,1750.62230919765,1749.31702544031,1748.01174168297,1746.70645792564,1745.4011741683,1744.09589041096,1742.79060665362,1741.48532289628,1740.18003913894,1738.8747553816,1737.56947162427,1736.26418786693,1734.95890410959,1733.65362035225,1732.34833659491,1731.04305283757,1729.73776908023,1728.4324853229,1727.12720156556,1725.82191780822,1724.51663405088,1723.21135029354,1721.9060665362,1720.60078277886,1719.29549902153,1717.99021526419,1716.68493150685,1715.37964774951,1714.07436399217,1712.76908023483,1711.4637964775,1710.15851272016,1708.85322896282,1707.54794520548,1706.24266144814,1704.9373776908,1703.63209393346,1702.32681017613,1701.02152641879,1699.71624266145,1698.41095890411,1697.10567514677,1695.80039138943,1694.49510763209,1693.18982387476,1691.88454011742,1690.57925636008,1689.27397260274,1687.9686888454,1686.66340508806,1685.35812133072,1684.05283757339,1682.74755381605,1681.44227005871,1680.13698630137,1678.83170254403,1677.52641878669,1676.22113502935,1674.91585127202,1673.61056751468,1672.30528375734,1671,1671],"y":[1.95316092343043,1.95266548875258,1.95220284925295,1.95176112264042,1.951336815918,1.95094650343113,1.95057508485373,1.95022057769211,1.94989965694061,1.94959488045311,1.9493065230863,1.94904801051445,1.948803088126,1.94857350621602,1.94836768320649,1.94817271473965,1.94799070456339,1.94782535413293,1.94766744173856,1.94751866356061,1.94737872583487,1.94724218829038,1.94710943049698,1.946977288352,1.94684396531351,1.94670750411307,1.94656334807891,1.94641298015099,1.94625101737107,1.9460732728951,1.94588394002385,1.94567309806934,1.9454388958029,1.94518749431977,1.94490334537223,1.94458901401488,1.94425175180536,1.94386935797128,1.94345091944775,1.94300380923537,1.9424982515977,1.9419518999143,1.94137123247911,1.94071810974767,1.94002065763675,1.93928343976857,1.93845932121608,1.937588602397,1.93667061287521,1.93565577053412,1.93459098978917,1.93346952946407,1.93224586162315,1.93096788954898,1.92962355624395,1.92817336972452,1.92666498359105,1.92508046900139,1.92338813071007,1.92163420696315,1.91979449148572,1.91784658904026,1.91583425627977,1.91372676354253,1.91151223488054,1.90923099835346,1.90684572253154,1.90435596641022,1.90179781598401,1.89912743552738,1.89635641465491,1.89351592779005,1.89055591808316,1.88750026508917,1.88437471452972,1.88112346933281,1.87778260299736,1.87437207588113,1.87083104338254,1.86720729872495,1.86351482982033,1.8596886641052,1.85578743540224,1.85181915254257,1.84771587570485,1.84354576665736,1.83930803973585,1.83494220608721,1.83051517662694,1.82601903828746,1.82140760560192,1.81673910068392,1.81200166492996,1.80716281158042,1.80227185418169,1.79731406151939,1.79226958064367,1.78717880946887,1.78202544608803,1.77680072714268,1.77153635951817,1.7662159868095,1.7608399081391,1.75543161043021,1.74997638588552,1.74448110342588,1.73896175506695,1.73340713070584,1.72782775312687,1.72223309587629,1.71661738744248,1.71099153476635,1.70535970579071,1.69972353462748,1.69409078520247,1.68846174060054,1.68284735972362,1.67724859882972,1.67166344264074,1.66611396830739,1.66059065994666,1.65509090186471,1.64964948102284,1.64424289188258,1.6388714525079,1.63357861559245,1.62832902604161,1.62312854287366,1.61802226761904,1.61296820825539,1.60797819668531,1.60309521270528,1.59827276589427,1.59352993743699,1.58890405208277,1.58434625579732,1.57988390999216,1.57554551370607,1.5712818997112,1.56712947494368,1.56310520068924,1.55916149091685,1.55534429762287,1.55165685001929,1.548054824329,1.54459397085923,1.54126212855559,1.53801966472581,1.53493217131666,1.53197095310597,1.52910222680953,1.52640130788167,1.52382228016621,1.5213380999644,1.51903358073847,1.51684527236895,1.51475351356155,1.51285233513824,1.51106071647301,1.5093668090638,1.50787356791691,1.50648254514496,1.50519440659513,1.50410743040117,1.50311930444713,1.50224271082931,1.50155957040041,1.5009754124428,1.50051117043886,1.50023216926807,1.50005207201694,1.5,1.50012455695926,1.50034773190133,1.50070671146484,1.50123332670177,1.50185803168324,1.50262586842976,1.50355191820841,1.50457521581112,1.50574831609501,1.50706969020966,1.50848705398322,1.51005994344901,1.51177055481137,1.51357535605431,1.51554008316855,1.51763129298317,1.51981421396977,1.52215969560631,1.52461970790267,1.52716813697218,1.52987951208147,1.53269279725793,1.53559026608204,1.53864832661468,1.54179513446692,1.54502085757087,1.54840162275239,1.55185764107055,1.55538920626056,1.55906070324792,1.56279690881965,1.56660583138563,1.57053245669544,1.57451519224056,1.57856511295104,1.58270984972005,1.58690114407165,1.59115125452457,1.59547318006829,1.59983131122113,1.60423704277546,1.60869206963923,1.61317235263656,1.61768630545793,1.62222812205796,1.62678388756948,1.63135695557835,1.63593812142843,1.64052183759095,1.6451044710501,1.64967761127668,1.65424209192652,1.65878563024489,1.6633046681722,1.66780430561012,1.67226230923181,1.67668367453701,1.68107563461718,1.68540514662551,1.68968889975843,1.69393422114313,1.69809689594454,1.70220771662689,1.70627226388103,1.71023531111697,1.71414330892059,1.71799618576023,1.72173544526209,1.72541676245165,1.72903275219133,1.73253128258497,1.73596847245063,1.73933128545566,1.74257666446629,1.74575884116018,1.74885917494739,1.75184551018355,1.7547682776504,1.75760367027308,1.76033136731079,1.76299654453858,1.76557100929389,1.76804635467828,1.77046152174316,1.77278499312773,1.7750195807441,1.7771974748363,1.77928510016856,1.78129513220044,1.78325292512407,1.7851242380001,1.78692973232254,1.78868822121911,1.79036623249159,1.79199016733264,1.79357290909887,1.79508314903686,1.79655057365721,1.79798299129486,1.79935253371177,1.80068967127499,1.80199815779016,1.80325465386856,1.8044880200998,1.80569828649998,1.80686980982954,1.8080253688411,1.80916312572488,1.81027578284743,1.811378159821,1.8124685581425,1.81354547972992,1.81461724897238,1.81568305474727,1.8167448312397,1.81780589728591,1.81886685241665,1.81993099882201,1.82099808742733,1.82207039824638,1.82315094126187,1.82423721592264,1.82533318663053,1.82644038826887,1.82755520594243,1.82868303144681,1.82982326054461,1.83097207719279,1.832135805793,1.83331156472493,1.83449599698573,1.83569566773689,1.83690577630396,1.83812381998858,1.83935577248948,1.84059570443495,1.84184210382915,1.84309944992619,1.84436181019001,1.84562856467712,1.84690180270287,1.84817692585706,1.8494539268101,1.85073165608849,1.85200829902128,1.85328365544254,1.85455376813262,1.85581986364178,1.85708088769875,1.85833119007058,1.85957462324067,1.86080881305911,1.86202765396128,1.86323702059108,1.86443287113532,1.86560985907809,1.86677516538744,1.86792290035604,1.86904953156357,1.87016279712074,1.87125498022343,1.8723251436071,1.87338087481338,1.87441286606357,1.87542319839855,1.87641870763231,1.87738894018515,1.87833901405836,1.87927456917932,1.88018463402455,1.88107697167759,1.88195577130873,1.88281030985462,1.88365022705911,1.88447820807287,1.88528462529652,1.88607992001375,1.88686541409186,1.88763343644893,1.88839394641566,1.88914699261082,1.88988832337324,1.89062538420773,1.89135772156613,1.89208484281628,1.89281068321651,1.89353521010035,1.89426062591029,1.89498773870703,1.89571744263209,1.8964534424218,1.89719396958727,1.89794127000475,1.89869934799149,1.89946451437161,1.90024067060662,1.90103101756223,1.9018306424977,1.90264525750063,1.90347634834208,1.9043184570485,1.90517909863044,1.90605739120284,1.90694793948036,1.90785989082973,1.90878964266025,1.9097323599327,1.91069850133751,1.91168170285925,1.91267805040461,1.91369886505927,1.91473528046131,1.91578451460482,1.91685820384372,1.91794550479898,1.91904482926832,1.92016751702646,1.92130149041391,1.92244664730902,1.92361228130975,1.92478708982704,1.92597213900292,1.92717329297843,1.92838176719645,1.92959890489825,1.93082758619439,1.93206152793588,1.93330194848275,1.934549366873,1.93579984647629,1.93705406059381,1.93831091126969,1.93956854491747,1.9408266719567,1.94208339052939,1.94333858794087,1.94459061251943,1.94583759566203,1.94708077263706,1.94831676104277,1.94954455038428,1.95076630457756,1.95197658058565,1.953176010906,1.9543672625072,1.95554254576722,1.956704861226,1.95785696273641,1.9589884753999,1.9601054193535,1.9612102402927,1.9622897890204,1.96335367393147,1.96440366708553,1.96542370804629,1.96642747213737,1.96741514848265,1.96836942204623,1.96930667882627,1.97022486915183,1.97110823839493,1.97197332415789,1.97281634343095,1.97362372993562,1.9744117529706,1.97517475292992,1.97590189075435,1.97660878448184,1.9772878128717,1.97793130529155,1.97855388599417,1.97914595083257,1.97970333120046,1.98023935955659,1.98074249703443,1.9812122919225,1.98166053625706,1.98207387943698,1.98245567109799,1.98281596918063,1.98313981350158,1.98343429778824,1.98370761316286,1.98394347388213,1.9841525091155,1.9843409773473,1.98449163347815,1.98461827536261,1.98472523524834,1.98479475428735,1.9848432718411,1.9848732765539,1.98486701435287,1.98484288197121,1.98480113286007,1.98472625585864,1.98463611707021,1.98452896069216,1.98439384114055,1.98424544036958,1.9840812446538,1.98389440609617,1.98369648581495,1.98348464313053,1.98325550420407,1.98301766624235,1.98276843103123,1.98250713905695,1.98223967049734,1.98196395807741,1.98168118883924,1.98139485481003,1.98110400470092,1.98081073230828,1.98051653999529,1.98022204947952,1.97992929223769,1.97963823245419,1.97935146839709,1.97907001853198,1.97879279306679,1.97852469209942,1.97826483884538,1.97801158339958,1.97777235223004,1.9775436090381,1.97732362270963,1.97712245139248,1.97693329871519,1.9767547915652,1.97659959288263,1.97645724803566,1.9763275418506,1.97622430577135,1.97613453070185,1.976059799522,1.97601249805758,1.97597945446136,1.97596355921633,1.97597506550453,2.02402493449547,2.02403644078367,2.02402054553864,2.02398750194242,2.023940200478,2.02386546929815,2.02377569422865,2.0236724581494,2.02354275196434,2.02340040711737,2.0232452084348,2.02306670128481,2.02287754860752,2.02267637729037,2.0224563909619,2.02222764776996,2.02198841660042,2.02173516115462,2.02147530790058,2.02120720693321,2.02092998146802,2.02064853160291,2.02036176754581,2.02007070776231,2.01977795052048,2.01948346000471,2.01918926769172,2.01889599529908,2.01860514518997,2.01831881116076,2.01803604192259,2.01776032950266,2.01749286094305,2.01723156896877,2.01698233375765,2.01674449579593,2.01651535686947,2.01630351418505,2.01610559390383,2.0159187553462,2.01575455963042,2.01560615885945,2.01547103930784,2.01536388292979,2.01527374414136,2.01519886713993,2.01515711802879,2.01513298564713,2.0151267234461,2.0151567281589,2.01520524571265,2.01527476475166,2.01538172463739,2.01550836652185,2.0156590226527,2.0158474908845,2.01605652611787,2.01629238683714,2.01656570221176,2.01686018649842,2.01718403081937,2.01754432890201,2.01792612056302,2.01833946374294,2.0187877080775,2.01925750296557,2.01976064044341,2.02029666879954,2.02085404916743,2.02144611400583,2.02206869470845,2.0227121871283,2.02339121551816,2.02409810924565,2.02482524707008,2.0255882470294,2.02637627006438,2.02718365656905,2.02802667584211,2.02889176160507,2.02977513084817,2.03069332117373,2.03163057795377,2.03258485151735,2.03357252786263,2.03457629195371,2.03559633291447,2.03664632606853,2.0377102109796,2.0387897597073,2.0398945806465,2.0410115246001,2.04214303726359,2.043295138774,2.04445745423278,2.0456327374928,2.046823989094,2.04802341941435,2.04923369542244,2.05045544961572,2.05168323895723,2.05291922736294,2.05416240433797,2.05540938748057,2.05666141205913,2.05791660947061,2.0591733280433,2.06043145508253,2.06168908873031,2.06294593940619,2.06420015352371,2.065450633127,2.06669805151725,2.06793847206412,2.06917241380561,2.07040109510175,2.07161823280355,2.07282670702157,2.07402786099708,2.07521291017296,2.07638771869025,2.07755335269098,2.07869850958609,2.07983248297354,2.08095517073168,2.08205449520102,2.08314179615628,2.08421548539518,2.08526471953869,2.08630113494073,2.08732194959539,2.08831829714075,2.08930149866249,2.0902676400673,2.09121035733975,2.09214010917027,2.09305206051964,2.09394260879716,2.09482090136956,2.0956815429515,2.09652365165792,2.09735474249937,2.0981693575023,2.09896898243777,2.09975932939338,2.10053548562839,2.10130065200851,2.10205872999525,2.10280603041273,2.1035465575782,2.10428255736791,2.10501226129297,2.1057393740897,2.10646478989965,2.10718931678349,2.10791515718372,2.10864227843387,2.10937461579227,2.11011167662676,2.11085300738918,2.11160605358434,2.11236656355107,2.11313458590814,2.11392007998625,2.11471537470348,2.11552179192713,2.11634977294089,2.11718969014538,2.11804422869127,2.11892302832241,2.11981536597545,2.12072543082068,2.12166098594164,2.12261105981485,2.12358129236769,2.12457680160145,2.12558713393643,2.12661912518662,2.1276748563929,2.12874501977657,2.12983720287927,2.13095046843643,2.13207709964396,2.13322483461256,2.13439014092191,2.13556712886468,2.13676297940892,2.13797234603872,2.13919118694089,2.14042537675933,2.14166880992942,2.14291911230125,2.14418013635822,2.14544623186738,2.14671634455746,2.14799170097872,2.14926834391151,2.1505460731899,2.15182307414294,2.15309819729713,2.15437143532288,2.15563818980999,2.15690055007381,2.15815789617085,2.15940429556505,2.16064422751052,2.16187618001142,2.16309422369604,2.16430433226311,2.16550400301427,2.16668843527507,2.167864194207,2.16902792280721,2.17017673945539,2.17131696855319,2.17244479405757,2.17355961173113,2.17466681336947,2.17576278407736,2.17684905873813,2.17792960175362,2.17900191257267,2.18006900117799,2.18113314758335,2.18219410271409,2.1832551687603,2.18431694525273,2.18538275102762,2.18645452027008,2.1875314418575,2.188621840179,2.18972421715257,2.19083687427512,2.1919746311589,2.19313019017046,2.19430171350002,2.1955119799002,2.19674534613144,2.19800184220984,2.19931032872501,2.20064746628823,2.20201700870514,2.20344942634279,2.20491685096314,2.20642709090113,2.20800983266736,2.20963376750841,2.21131177878089,2.21307026767746,2.2148757619999,2.21674707487593,2.21870486779956,2.22071489983144,2.2228025251637,2.2249804192559,2.22721500687227,2.22953847825684,2.23195364532172,2.23442899070611,2.23700345546142,2.23966863268921,2.24239632972692,2.2452317223496,2.24815448981645,2.25114082505261,2.25424115883982,2.25742333553371,2.26066871454434,2.26403152754937,2.26746871741503,2.27096724780867,2.27458323754835,2.27826455473791,2.28200381423977,2.28585669107941,2.28976468888303,2.29372773611897,2.29779228337311,2.30190310405546,2.30606577885687,2.31031110024157,2.31459485337449,2.31892436538282,2.32331632546299,2.32773769076819,2.33219569438988,2.3366953318278,2.34121436975511,2.34575790807348,2.35032238872332,2.3548955289499,2.35947816240905,2.36406187857157,2.36864304442165,2.37321611243052,2.37777187794204,2.38231369454207,2.38682764736344,2.39130793036077,2.39576295722454,2.40016868877887,2.40452681993171,2.40884874547543,2.41309885592836,2.41729015027995,2.42143488704896,2.42548480775944,2.42946754330456,2.43339416861437,2.43720309118035,2.44093929675208,2.44461079373944,2.44814235892945,2.45159837724761,2.45497914242913,2.45820486553308,2.46135167338532,2.46440973391796,2.46730720274207,2.47012048791853,2.47283186302782,2.47538029209733,2.47784030439369,2.48018578603023,2.48236870701683,2.48445991683145,2.48642464394569,2.48822944518863,2.48994005655099,2.49151294601678,2.49293030979034,2.49425168390499,2.49542478418888,2.49644808179159,2.49737413157024,2.49814196831676,2.49876667329823,2.49929328853516,2.49965226809867,2.49987544304074,2.5,2.49994792798306,2.49976783073193,2.49948882956114,2.4990245875572,2.49844042959959,2.49775728917069,2.49688069555287,2.49589256959883,2.49480559340487,2.49351745485504,2.49212643208309,2.4906331909362,2.48893928352699,2.48714766486176,2.48524648643845,2.48315472763105,2.48096641926153,2.4786619000356,2.47617771983379,2.47359869211833,2.47089777319047,2.46802904689403,2.46506782868334,2.46198033527419,2.45873787144441,2.45540602914077,2.451945175671,2.44834314998071,2.44465570237713,2.44083850908315,2.43689479931076,2.43287052505632,2.4287181002888,2.42445448629393,2.42011609000784,2.41565374420268,2.41109594791723,2.40647006256301,2.40172723410573,2.39690478729472,2.39202180331469,2.38703179174461,2.38197773238096,2.37687145712634,2.37167097395839,2.36642138440755,2.3611285474921,2.35575710811742,2.35035051897716,2.34490909813529,2.33940934005334,2.33388603169261,2.32833655735926,2.32275140117028,2.31715264027638,2.31153825939946,2.30590921479753,2.30027646537252,2.29464029420929,2.28900846523365,2.28338261255752,2.27776690412371,2.27217224687313,2.26659286929416,2.26103824493305,2.25551889657412,2.25002361411448,2.24456838956979,2.2391600918609,2.2337840131905,2.22846364048183,2.22319927285732,2.21797455391197,2.21282119053113,2.20773041935633,2.20268593848061,2.19772814581831,2.19283718841958,2.18799833507004,2.18326089931608,2.17859239439808,2.17398096171254,2.16948482337306,2.16505779391279,2.16069196026415,2.15645423334264,2.15228412429515,2.14818084745743,2.14421256459776,2.1403113358948,2.13648517017967,2.13279270127505,2.12916895661746,2.12562792411887,2.12221739700264,2.11887653066719,2.11562528547028,2.11249973491083,2.10944408191684,2.10648407220995,2.10364358534509,2.10087256447262,2.09820218401599,2.09564403358978,2.09315427746846,2.09076900164654,2.08848776511946,2.08627323645747,2.08416574372023,2.08215341095974,2.08020550851428,2.07836579303685,2.07661186928993,2.07491953099861,2.07333501640895,2.07182663027548,2.07037644375605,2.06903211045102,2.06775413837685,2.06653047053593,2.06540901021083,2.06434422946588,2.06332938712479,2.062411397603,2.06154067878392,2.06071656023143,2.05997934236325,2.05928189025233,2.05862876752089,2.0580481000857,2.0575017484023,2.05699619076463,2.05654908055225,2.05613064202872,2.05574824819464,2.05541098598512,2.05509665462777,2.05481250568023,2.0545611041971,2.05432690193066,2.05411605997615,2.0539267271049,2.05374898262893,2.05358701984901,2.05343665192109,2.05329249588693,2.05315603468649,2.053022711648,2.05289056950302,2.05275781170962,2.05262127416513,2.05248133643939,2.05233255826144,2.05217464586707,2.05200929543661,2.05182728526035,2.05163231679351,2.05142649378398,2.051196911874,2.05095198948555,2.0506934769137,2.05040511954689,2.05010034305939,2.04977942230789,2.04942491514627,2.04905349656887,2.048663184082,2.04823887735958,2.04779715074705,2.04733451124742,2.04683907656957,1.95316092343043],"text":["Condition: Simple<br />Condition: Simple<br />RT: 1671.000<br />density: 0.0003764241","Condition: Simple<br />Condition: Simple<br />RT: 1672.305<br />density: 0.0003804057","Condition: Simple<br />Condition: Simple<br />RT: 1673.611<br />density: 0.0003841237","Condition: Simple<br />Condition: Simple<br />RT: 1674.916<br />density: 0.0003876736","Condition: Simple<br />Condition: Simple<br />RT: 1676.221<br />density: 0.0003910836","Condition: Simple<br />Condition: Simple<br />RT: 1677.526<br />density: 0.0003942204","Condition: Simple<br />Condition: Simple<br />RT: 1678.832<br />density: 0.0003972053","Condition: Simple<br />Condition: Simple<br />RT: 1680.137<br />density: 0.0004000543","Condition: Simple<br />Condition: Simple<br />RT: 1681.442<br />density: 0.0004026334","Condition: Simple<br />Condition: Simple<br />RT: 1682.748<br />density: 0.0004050827","Condition: Simple<br />Condition: Simple<br />RT: 1684.053<br />density: 0.0004074001","Condition: Simple<br />Condition: Simple<br />RT: 1685.358<br />density: 0.0004094777","Condition: Simple<br />Condition: Simple<br />RT: 1686.663<br />density: 0.0004114460","Condition: Simple<br />Condition: Simple<br />RT: 1687.969<br />density: 0.0004132910","Condition: Simple<br />Condition: Simple<br />RT: 1689.274<br />density: 0.0004149452","Condition: Simple<br />Condition: Simple<br />RT: 1690.579<br />density: 0.0004165120","Condition: Simple<br />Condition: Simple<br />RT: 1691.885<br />density: 0.0004179748","Condition: Simple<br />Condition: Simple<br />RT: 1693.190<br />density: 0.0004193036","Condition: Simple<br />Condition: Simple<br />RT: 1694.495<br />density: 0.0004205727","Condition: Simple<br />Condition: Simple<br />RT: 1695.800<br />density: 0.0004217683","Condition: Simple<br />Condition: Simple<br />RT: 1697.106<br />density: 0.0004228929","Condition: Simple<br />Condition: Simple<br />RT: 1698.411<br />density: 0.0004239902","Condition: Simple<br />Condition: Simple<br />RT: 1699.716<br />density: 0.0004250572","Condition: Simple<br />Condition: Simple<br />RT: 1701.022<br />density: 0.0004261191","Condition: Simple<br />Condition: Simple<br />RT: 1702.327<br />density: 0.0004271906","Condition: Simple<br />Condition: Simple<br />RT: 1703.632<br />density: 0.0004282872","Condition: Simple<br />Condition: Simple<br />RT: 1704.937<br />density: 0.0004294458","Condition: Simple<br />Condition: Simple<br />RT: 1706.243<br />density: 0.0004306542","Condition: Simple<br />Condition: Simple<br />RT: 1707.548<br />density: 0.0004319558","Condition: Simple<br />Condition: Simple<br />RT: 1708.853<br />density: 0.0004333843","Condition: Simple<br />Condition: Simple<br />RT: 1710.159<br />density: 0.0004349059","Condition: Simple<br />Condition: Simple<br />RT: 1711.464<br />density: 0.0004366003","Condition: Simple<br />Condition: Simple<br />RT: 1712.769<br />density: 0.0004384825","Condition: Simple<br />Condition: Simple<br />RT: 1714.074<br />density: 0.0004405029","Condition: Simple<br />Condition: Simple<br />RT: 1715.380<br />density: 0.0004427864","Condition: Simple<br />Condition: Simple<br />RT: 1716.685<br />density: 0.0004453126","Condition: Simple<br />Condition: Simple<br />RT: 1717.990<br />density: 0.0004480230","Condition: Simple<br />Condition: Simple<br />RT: 1719.295<br />density: 0.0004510961","Condition: Simple<br />Condition: Simple<br />RT: 1720.601<br />density: 0.0004544589","Condition: Simple<br />Condition: Simple<br />RT: 1721.906<br />density: 0.0004580521","Condition: Simple<br />Condition: Simple<br />RT: 1723.211<br />density: 0.0004621151","Condition: Simple<br />Condition: Simple<br />RT: 1724.517<br />density: 0.0004665058","Condition: Simple<br />Condition: Simple<br />RT: 1725.822<br />density: 0.0004711724","Condition: Simple<br />Condition: Simple<br />RT: 1727.127<br />density: 0.0004764213","Condition: Simple<br />Condition: Simple<br />RT: 1728.432<br />density: 0.0004820264","Condition: Simple<br />Condition: Simple<br />RT: 1729.738<br />density: 0.0004879510","Condition: Simple<br />Condition: Simple<br />RT: 1731.043<br />density: 0.0004945741","Condition: Simple<br />Condition: Simple<br />RT: 1732.348<br />density: 0.0005015717","Condition: Simple<br />Condition: Simple<br />RT: 1733.654<br />density: 0.0005089491","Condition: Simple<br />Condition: Simple<br />RT: 1734.959<br />density: 0.0005171049","Condition: Simple<br />Condition: Simple<br />RT: 1736.264<br />density: 0.0005256621","Condition: Simple<br />Condition: Simple<br />RT: 1737.569<br />density: 0.0005346748","Condition: Simple<br />Condition: Simple<br />RT: 1738.875<br />density: 0.0005445088","Condition: Simple<br />Condition: Simple<br />RT: 1740.180<br />density: 0.0005547793","Condition: Simple<br />Condition: Simple<br />RT: 1741.485<br />density: 0.0005655831","Condition: Simple<br />Condition: Simple<br />RT: 1742.791<br />density: 0.0005772376","Condition: Simple<br />Condition: Simple<br />RT: 1744.096<br />density: 0.0005893598","Condition: Simple<br />Condition: Simple<br />RT: 1745.401<br />density: 0.0006020938","Condition: Simple<br />Condition: Simple<br />RT: 1746.706<br />density: 0.0006156943","Condition: Simple<br />Condition: Simple<br />RT: 1748.012<br />density: 0.0006297898","Condition: Simple<br />Condition: Simple<br />RT: 1749.317<br />density: 0.0006445747","Condition: Simple<br />Condition: Simple<br />RT: 1750.622<br />density: 0.0006602291","Condition: Simple<br />Condition: Simple<br />RT: 1751.928<br />density: 0.0006764013","Condition: Simple<br />Condition: Simple<br />RT: 1753.233<br />density: 0.0006933383","Condition: Simple<br />Condition: Simple<br />RT: 1754.538<br />density: 0.0007111354","Condition: Simple<br />Condition: Simple<br />RT: 1755.843<br />density: 0.0007294687","Condition: Simple<br />Condition: Simple<br />RT: 1757.149<br />density: 0.0007486380","Condition: Simple<br />Condition: Simple<br />RT: 1758.454<br />density: 0.0007686471","Condition: Simple<br />Condition: Simple<br />RT: 1759.759<br />density: 0.0007892057","Condition: Simple<br />Condition: Simple<br />RT: 1761.065<br />density: 0.0008106663","Condition: Simple<br />Condition: Simple<br />RT: 1762.370<br />density: 0.0008329358","Condition: Simple<br />Condition: Simple<br />RT: 1763.675<br />density: 0.0008557635","Condition: Simple<br />Condition: Simple<br />RT: 1764.980<br />density: 0.0008795517","Condition: Simple<br />Condition: Simple<br />RT: 1766.286<br />density: 0.0009041086","Condition: Simple<br />Condition: Simple<br />RT: 1767.591<br />density: 0.0009292272","Condition: Simple<br />Condition: Simple<br />RT: 1768.896<br />density: 0.0009553559","Condition: Simple<br />Condition: Simple<br />RT: 1770.202<br />density: 0.0009822049","Condition: Simple<br />Condition: Simple<br />RT: 1771.507<br />density: 0.0010096138","Condition: Simple<br />Condition: Simple<br />RT: 1772.812<br />density: 0.0010380714","Condition: Simple<br />Condition: Simple<br />RT: 1774.117<br />density: 0.0010671938","Condition: Simple<br />Condition: Simple<br />RT: 1775.423<br />density: 0.0010968685","Condition: Simple<br />Condition: Simple<br />RT: 1776.728<br />density: 0.0011276176","Condition: Simple<br />Condition: Simple<br />RT: 1778.033<br />density: 0.0011589700","Condition: Simple<br />Condition: Simple<br />RT: 1779.339<br />density: 0.0011908612","Condition: Simple<br />Condition: Simple<br />RT: 1780.644<br />density: 0.0012238374","Condition: Simple<br />Condition: Simple<br />RT: 1781.949<br />density: 0.0012573506","Condition: Simple<br />Condition: Simple<br />RT: 1783.254<br />density: 0.0012914073","Condition: Simple<br />Condition: Simple<br />RT: 1784.560<br />density: 0.0013264935","Condition: Simple<br />Condition: Simple<br />RT: 1785.865<br />density: 0.0013620715","Condition: Simple<br />Condition: Simple<br />RT: 1787.170<br />density: 0.0013982049","Condition: Simple<br />Condition: Simple<br />RT: 1788.476<br />density: 0.0014352648","Condition: Simple<br />Condition: Simple<br />RT: 1789.781<br />density: 0.0014727835","Condition: Simple<br />Condition: Simple<br />RT: 1791.086<br />density: 0.0015108560","Condition: Simple<br />Condition: Simple<br />RT: 1792.391<br />density: 0.0015497437","Condition: Simple<br />Condition: Simple<br />RT: 1793.697<br />density: 0.0015890501","Condition: Simple<br />Condition: Simple<br />RT: 1795.002<br />density: 0.0016288935","Condition: Simple<br />Condition: Simple<br />RT: 1796.307<br />density: 0.0016694337","Condition: Simple<br />Condition: Simple<br />RT: 1797.613<br />density: 0.0017103459","Condition: Simple<br />Condition: Simple<br />RT: 1798.918<br />density: 0.0017517611","Condition: Simple<br />Condition: Simple<br />RT: 1800.223<br />density: 0.0017937498","Condition: Simple<br />Condition: Simple<br />RT: 1801.528<br />density: 0.0018360571","Condition: Simple<br />Condition: Simple<br />RT: 1802.834<br />density: 0.0018788145","Condition: Simple<br />Condition: Simple<br />RT: 1804.139<br />density: 0.0019220195","Condition: Simple<br />Condition: Simple<br />RT: 1805.444<br />density: 0.0019654835","Condition: Simple<br />Condition: Simple<br />RT: 1806.750<br />density: 0.0020093246","Condition: Simple<br />Condition: Simple<br />RT: 1808.055<br />density: 0.0020534877","Condition: Simple<br />Condition: Simple<br />RT: 1809.360<br />density: 0.0020978442","Condition: Simple<br />Condition: Simple<br />RT: 1810.665<br />density: 0.0021424841","Condition: Simple<br />Condition: Simple<br />RT: 1811.971<br />density: 0.0021873230","Condition: Simple<br />Condition: Simple<br />RT: 1813.276<br />density: 0.0022322847","Condition: Simple<br />Condition: Simple<br />RT: 1814.581<br />density: 0.0022774156","Condition: Simple<br />Condition: Simple<br />RT: 1815.886<br />density: 0.0023226279","Condition: Simple<br />Condition: Simple<br />RT: 1817.192<br />density: 0.0023678884","Condition: Simple<br />Condition: Simple<br />RT: 1818.497<br />density: 0.0024131837","Condition: Simple<br />Condition: Simple<br />RT: 1819.802<br />density: 0.0024584515","Condition: Simple<br />Condition: Simple<br />RT: 1821.108<br />density: 0.0025036895","Condition: Simple<br />Condition: Simple<br />RT: 1822.413<br />density: 0.0025488097","Condition: Simple<br />Condition: Simple<br />RT: 1823.718<br />density: 0.0025938044","Condition: Simple<br />Condition: Simple<br />RT: 1825.023<br />density: 0.0026386897","Condition: Simple<br />Condition: Simple<br />RT: 1826.329<br />density: 0.0026832883","Condition: Simple<br />Condition: Simple<br />RT: 1827.634<br />density: 0.0027276766","Condition: Simple<br />Condition: Simple<br />RT: 1828.939<br />density: 0.0027718756","Condition: Simple<br />Condition: Simple<br />RT: 1830.245<br />density: 0.0028156058","Condition: Simple<br />Condition: Simple<br />RT: 1831.550<br />density: 0.0028590561","Condition: Simple<br />Condition: Simple<br />RT: 1832.855<br />density: 0.0029022238","Condition: Simple<br />Condition: Simple<br />RT: 1834.160<br />density: 0.0029447599","Condition: Simple<br />Condition: Simple<br />RT: 1835.466<br />density: 0.0029869485","Condition: Simple<br />Condition: Simple<br />RT: 1836.771<br />density: 0.0030287423","Condition: Simple<br />Condition: Simple<br />RT: 1838.076<br />density: 0.0030697791","Condition: Simple<br />Condition: Simple<br />RT: 1839.382<br />density: 0.0031103963","Condition: Simple<br />Condition: Simple<br />RT: 1840.687<br />density: 0.0031504987","Condition: Simple<br />Condition: Simple<br />RT: 1841.992<br />density: 0.0031897410","Condition: Simple<br />Condition: Simple<br />RT: 1843.297<br />density: 0.0032284968","Condition: Simple<br />Condition: Simple<br />RT: 1844.603<br />density: 0.0032666127","Condition: Simple<br />Condition: Simple<br />RT: 1845.908<br />density: 0.0033037888","Condition: Simple<br />Condition: Simple<br />RT: 1847.213<br />density: 0.0033404177","Condition: Simple<br />Condition: Simple<br />RT: 1848.519<br />density: 0.0033762795","Condition: Simple<br />Condition: Simple<br />RT: 1849.824<br />density: 0.0034111452","Condition: Simple<br />Condition: Simple<br />RT: 1851.129<br />density: 0.0034454099","Condition: Simple<br />Condition: Simple<br />RT: 1852.434<br />density: 0.0034787811","Condition: Simple<br />Condition: Simple<br />RT: 1853.740<br />density: 0.0035111223","Condition: Simple<br />Condition: Simple<br />RT: 1855.045<br />density: 0.0035428161","Condition: Simple<br />Condition: Simple<br />RT: 1856.350<br />density: 0.0035734931","Condition: Simple<br />Condition: Simple<br />RT: 1857.656<br />density: 0.0036031274","Condition: Simple<br />Condition: Simple<br />RT: 1858.961<br />density: 0.0036320753","Condition: Simple<br />Condition: Simple<br />RT: 1860.266<br />density: 0.0036598885","Condition: Simple<br />Condition: Simple<br />RT: 1861.571<br />density: 0.0036866650","Condition: Simple<br />Condition: Simple<br />RT: 1862.877<br />density: 0.0037127232","Condition: Simple<br />Condition: Simple<br />RT: 1864.182<br />density: 0.0037375360","Condition: Simple<br />Condition: Simple<br />RT: 1865.487<br />density: 0.0037613339","Condition: Simple<br />Condition: Simple<br />RT: 1866.793<br />density: 0.0037843886","Condition: Simple<br />Condition: Simple<br />RT: 1868.098<br />density: 0.0038060946","Condition: Simple<br />Condition: Simple<br />RT: 1869.403<br />density: 0.0038268211","Condition: Simple<br />Condition: Simple<br />RT: 1870.708<br />density: 0.0038467853","Condition: Simple<br />Condition: Simple<br />RT: 1872.014<br />density: 0.0038653056","Condition: Simple<br />Condition: Simple<br />RT: 1873.319<br />density: 0.0038828921","Condition: Simple<br />Condition: Simple<br />RT: 1874.624<br />density: 0.0038997026","Condition: Simple<br />Condition: Simple<br />RT: 1875.930<br />density: 0.0039149814","Condition: Simple<br />Condition: Simple<br />RT: 1877.235<br />density: 0.0039293799","Condition: Simple<br />Condition: Simple<br />RT: 1878.540<br />density: 0.0039429930","Condition: Simple<br />Condition: Simple<br />RT: 1879.845<br />density: 0.0039549935","Condition: Simple<br />Condition: Simple<br />RT: 1881.151<br />density: 0.0039661725","Condition: Simple<br />Condition: Simple<br />RT: 1882.456<br />density: 0.0039765247","Condition: Simple<br />Condition: Simple<br />RT: 1883.761<br />density: 0.0039852602","Condition: Simple<br />Condition: Simple<br />RT: 1885.067<br />density: 0.0039932013","Condition: Simple<br />Condition: Simple<br />RT: 1886.372<br />density: 0.0040002461","Condition: Simple<br />Condition: Simple<br />RT: 1887.677<br />density: 0.0040057362","Condition: Simple<br />Condition: Simple<br />RT: 1888.982<br />density: 0.0040104308","Condition: Simple<br />Condition: Simple<br />RT: 1890.288<br />density: 0.0040141617","Condition: Simple<br />Condition: Simple<br />RT: 1891.593<br />density: 0.0040164039","Condition: Simple<br />Condition: Simple<br />RT: 1892.898<br />density: 0.0040178513","Condition: Simple<br />Condition: Simple<br />RT: 1894.204<br />density: 0.0040182697","Condition: Simple<br />Condition: Simple<br />RT: 1895.509<br />density: 0.0040172687","Condition: Simple<br />Condition: Simple<br />RT: 1896.814<br />density: 0.0040154752","Condition: Simple<br />Condition: Simple<br />RT: 1898.119<br />density: 0.0040125902","Condition: Simple<br />Condition: Simple<br />RT: 1899.425<br />density: 0.0040083581","Condition: Simple<br />Condition: Simple<br />RT: 1900.730<br />density: 0.0040033376","Condition: Simple<br />Condition: Simple<br />RT: 1902.035<br />density: 0.0039971669","Condition: Simple<br />Condition: Simple<br />RT: 1903.341<br />density: 0.0039897246","Condition: Simple<br />Condition: Simple<br />RT: 1904.646<br />density: 0.0039815008","Condition: Simple<br />Condition: Simple<br />RT: 1905.951<br />density: 0.0039720732","Condition: Simple<br />Condition: Simple<br />RT: 1907.256<br />density: 0.0039614539","Condition: Simple<br />Condition: Simple<br />RT: 1908.562<br />density: 0.0039500632","Condition: Simple<br />Condition: Simple<br />RT: 1909.867<br />density: 0.0039374226","Condition: Simple<br />Condition: Simple<br />RT: 1911.172<br />density: 0.0039236752","Condition: Simple<br />Condition: Simple<br />RT: 1912.477<br />density: 0.0039091709","Condition: Simple<br />Condition: Simple<br />RT: 1913.783<br />density: 0.0038933813","Condition: Simple<br />Condition: Simple<br />RT: 1915.088<br />density: 0.0038765752","Condition: Simple<br />Condition: Simple<br />RT: 1916.393<br />density: 0.0038590320","Condition: Simple<br />Condition: Simple<br />RT: 1917.699<br />density: 0.0038401825","Condition: Simple<br />Condition: Simple<br />RT: 1919.004<br />density: 0.0038204125","Condition: Simple<br />Condition: Simple<br />RT: 1920.309<br />density: 0.0037999319","Condition: Simple<br />Condition: Simple<br />RT: 1921.614<br />density: 0.0037781419","Condition: Simple<br />Condition: Simple<br />RT: 1922.920<br />density: 0.0037555328","Condition: Simple<br />Condition: Simple<br />RT: 1924.225<br />density: 0.0037322472","Condition: Simple<br />Condition: Simple<br />RT: 1925.530<br />density: 0.0037076709","Condition: Simple<br />Condition: Simple<br />RT: 1926.836<br />density: 0.0036823815","Condition: Simple<br />Condition: Simple<br />RT: 1928.141<br />density: 0.0036564578","Condition: Simple<br />Condition: Simple<br />RT: 1929.446<br />density: 0.0036292882","Condition: Simple<br />Condition: Simple<br />RT: 1930.751<br />density: 0.0036015138","Condition: Simple<br />Condition: Simple<br />RT: 1932.057<br />density: 0.0035731322","Condition: Simple<br />Condition: Simple<br />RT: 1933.362<br />density: 0.0035436261","Condition: Simple<br />Condition: Simple<br />RT: 1934.667<br />density: 0.0035135999","Condition: Simple<br />Condition: Simple<br />RT: 1935.973<br />density: 0.0034829894","Condition: Simple<br />Condition: Simple<br />RT: 1937.278<br />density: 0.0034514329","Condition: Simple<br />Condition: Simple<br />RT: 1938.583<br />density: 0.0034194255","Condition: Simple<br />Condition: Simple<br />RT: 1939.888<br />density: 0.0033868781","Condition: Simple<br />Condition: Simple<br />RT: 1941.194<br />density: 0.0033535688","Condition: Simple<br />Condition: Simple<br />RT: 1942.499<br />density: 0.0033198853","Condition: Simple<br />Condition: Simple<br />RT: 1943.804<br />density: 0.0032857291","Condition: Simple<br />Condition: Simple<br />RT: 1945.110<br />density: 0.0032509958","Condition: Simple<br />Condition: Simple<br />RT: 1946.415<br />density: 0.0032159715","Condition: Simple<br />Condition: Simple<br />RT: 1947.720<br />density: 0.0031805646","Condition: Simple<br />Condition: Simple<br />RT: 1949.025<br />density: 0.0031447616","Condition: Simple<br />Condition: Simple<br />RT: 1950.331<br />density: 0.0031087557","Condition: Simple<br />Condition: Simple<br />RT: 1951.636<br />density: 0.0030724791","Condition: Simple<br />Condition: Simple<br />RT: 1952.941<br />density: 0.0030359786","Condition: Simple<br />Condition: Simple<br />RT: 1954.247<br />density: 0.0029993660","Condition: Simple<br />Condition: Simple<br />RT: 1955.552<br />density: 0.0029626144","Condition: Simple<br />Condition: Simple<br />RT: 1956.857<br />density: 0.0029257977","Condition: Simple<br />Condition: Simple<br />RT: 1958.162<br />density: 0.0028889604","Condition: Simple<br />Condition: Simple<br />RT: 1959.468<br />density: 0.0028521319","Condition: Simple<br />Condition: Simple<br />RT: 1960.773<br />density: 0.0028153797","Condition: Simple<br />Condition: Simple<br />RT: 1962.078<br />density: 0.0027786971","Condition: Simple<br />Condition: Simple<br />RT: 1963.384<br />density: 0.0027421828","Condition: Simple<br />Condition: Simple<br />RT: 1964.689<br />density: 0.0027058653","Condition: Simple<br />Condition: Simple<br />RT: 1965.994<br />density: 0.0026697038","Condition: Simple<br />Condition: Simple<br />RT: 1967.299<br />density: 0.0026338769","Condition: Simple<br />Condition: Simple<br />RT: 1968.605<br />density: 0.0025983444","Condition: Simple<br />Condition: Simple<br />RT: 1969.910<br />density: 0.0025630483","Condition: Simple<br />Condition: Simple<br />RT: 1971.215<br />density: 0.0025282540","Condition: Simple<br />Condition: Simple<br />RT: 1972.521<br />density: 0.0024938274","Condition: Simple<br />Condition: Simple<br />RT: 1973.826<br />density: 0.0024597097","Condition: Simple<br />Condition: Simple<br />RT: 1975.131<br />density: 0.0024262562","Condition: Simple<br />Condition: Simple<br />RT: 1976.436<br />density: 0.0023932194","Condition: Simple<br />Condition: Simple<br />RT: 1977.742<br />density: 0.0023605546","Condition: Simple<br />Condition: Simple<br />RT: 1979.047<br />density: 0.0023287054","Condition: Simple<br />Condition: Simple<br />RT: 1980.352<br />density: 0.0022972986","Condition: Simple<br />Condition: Simple<br />RT: 1981.658<br />density: 0.0022663348","Condition: Simple<br />Condition: Simple<br />RT: 1982.963<br />density: 0.0022362841","Condition: Simple<br />Condition: Simple<br />RT: 1984.268<br />density: 0.0022066990","Condition: Simple<br />Condition: Simple<br />RT: 1985.573<br />density: 0.0021776390","Condition: Simple<br />Condition: Simple<br />RT: 1986.879<br />density: 0.0021495229","Condition: Simple<br />Condition: Simple<br />RT: 1988.184<br />density: 0.0021218998","Condition: Simple<br />Condition: Simple<br />RT: 1989.489<br />density: 0.0020948744","Condition: Simple<br />Condition: Simple<br />RT: 1990.795<br />density: 0.0020687928","Condition: Simple<br />Condition: Simple<br />RT: 1992.100<br />density: 0.0020432191","Condition: Simple<br />Condition: Simple<br />RT: 1993.405<br />density: 0.0020183032","Condition: Simple<br />Condition: Simple<br />RT: 1994.710<br />density: 0.0019943034","Condition: Simple<br />Condition: Simple<br />RT: 1996.016<br />density: 0.0019708144","Condition: Simple<br />Condition: Simple<br />RT: 1997.321<br />density: 0.0019480277","Condition: Simple<br />Condition: Simple<br />RT: 1998.626<br />density: 0.0019261064","Condition: Simple<br />Condition: Simple<br />RT: 1999.932<br />density: 0.0019046876","Condition: Simple<br />Condition: Simple<br />RT: 2001.237<br />density: 0.0018839978","Condition: Simple<br />Condition: Simple<br />RT: 2002.542<br />density: 0.0018641046","Condition: Simple<br />Condition: Simple<br />RT: 2003.847<br />density: 0.0018446950","Condition: Simple<br />Condition: Simple<br />RT: 2005.153<br />density: 0.0018260224","Condition: Simple<br />Condition: Simple<br />RT: 2006.458<br />density: 0.0018080640","Condition: Simple<br />Condition: Simple<br />RT: 2007.763<br />density: 0.0017905613","Condition: Simple<br />Condition: Simple<br />RT: 2009.068<br />density: 0.0017737840","Condition: Simple<br />Condition: Simple<br />RT: 2010.374<br />density: 0.0017576303","Condition: Simple<br />Condition: Simple<br />RT: 2011.679<br />density: 0.0017418964","Condition: Simple<br />Condition: Simple<br />RT: 2012.984<br />density: 0.0017268575","Condition: Simple<br />Condition: Simple<br />RT: 2014.290<br />density: 0.0017123476","Condition: Simple<br />Condition: Simple<br />RT: 2015.595<br />density: 0.0016982155","Condition: Simple<br />Condition: Simple<br />RT: 2016.900<br />density: 0.0016847301","Condition: Simple<br />Condition: Simple<br />RT: 2018.205<br />density: 0.0016716792","Condition: Simple<br />Condition: Simple<br />RT: 2019.511<br />density: 0.0016589595","Condition: Simple<br />Condition: Simple<br />RT: 2020.816<br />density: 0.0016468224","Condition: Simple<br />Condition: Simple<br />RT: 2022.121<br />density: 0.0016350294","Condition: Simple<br />Condition: Simple<br />RT: 2023.427<br />density: 0.0016235177","Condition: Simple<br />Condition: Simple<br />RT: 2024.732<br />density: 0.0016125113","Condition: Simple<br />Condition: Simple<br />RT: 2026.037<br />density: 0.0016017653","Condition: Simple<br />Condition: Simple<br />RT: 2027.342<br />density: 0.0015912496","Condition: Simple<br />Condition: Simple<br />RT: 2028.648<br />density: 0.0015811517","Condition: Simple<br />Condition: Simple<br />RT: 2029.953<br />density: 0.0015712397","Condition: Simple<br />Condition: Simple<br />RT: 2031.258<br />density: 0.0015615134","Condition: Simple<br />Condition: Simple<br />RT: 2032.564<br />density: 0.0015520984","Condition: Simple<br />Condition: Simple<br />RT: 2033.869<br />density: 0.0015428117","Condition: Simple<br />Condition: Simple<br />RT: 2035.174<br />density: 0.0015336681","Condition: Simple<br />Condition: Simple<br />RT: 2036.479<br />density: 0.0015247262","Condition: Simple<br />Condition: Simple<br />RT: 2037.785<br />density: 0.0015158669","Condition: Simple<br />Condition: Simple<br />RT: 2039.090<br />density: 0.0015071038","Condition: Simple<br />Condition: Simple<br />RT: 2040.395<br />density: 0.0014984491","Condition: Simple<br />Condition: Simple<br />RT: 2041.701<br />density: 0.0014898358","Condition: Simple<br />Condition: Simple<br />RT: 2043.006<br />density: 0.0014812704","Condition: Simple<br />Condition: Simple<br />RT: 2044.311<br />density: 0.0014727374","Condition: Simple<br />Condition: Simple<br />RT: 2045.616<br />density: 0.0014642101","Condition: Simple<br />Condition: Simple<br />RT: 2046.922<br />density: 0.0014556837","Condition: Simple<br />Condition: Simple<br />RT: 2048.227<br />density: 0.0014471316","Condition: Simple<br />Condition: Simple<br />RT: 2049.532<br />density: 0.0014385559","Condition: Simple<br />Condition: Simple<br />RT: 2050.838<br />density: 0.0014299383","Condition: Simple<br />Condition: Simple<br />RT: 2052.143<br />density: 0.0014212544","Condition: Simple<br />Condition: Simple<br />RT: 2053.448<br />density: 0.0014125246","Condition: Simple<br />Condition: Simple<br />RT: 2054.753<br />density: 0.0014037167","Condition: Simple<br />Condition: Simple<br />RT: 2056.059<br />density: 0.0013948187","Condition: Simple<br />Condition: Simple<br />RT: 2057.364<br />density: 0.0013858594","Condition: Simple<br />Condition: Simple<br />RT: 2058.669<br />density: 0.0013767956","Condition: Simple<br />Condition: Simple<br />RT: 2059.975<br />density: 0.0013676321","Condition: Simple<br />Condition: Simple<br />RT: 2061.280<br />density: 0.0013583996","Condition: Simple<br />Condition: Simple<br />RT: 2062.585<br />density: 0.0013490472","Condition: Simple<br />Condition: Simple<br />RT: 2063.890<br />density: 0.0013395982","Condition: Simple<br />Condition: Simple<br />RT: 2065.196<br />density: 0.0013300795","Condition: Simple<br />Condition: Simple<br />RT: 2066.501<br />density: 0.0013204383","Condition: Simple<br />Condition: Simple<br />RT: 2067.806<br />density: 0.0013107132","Condition: Simple<br />Condition: Simple<br />RT: 2069.112<br />density: 0.0013009243","Condition: Simple<br />Condition: Simple<br />RT: 2070.417<br />density: 0.0012910237","Condition: Simple<br />Condition: Simple<br />RT: 2071.722<br />density: 0.0012810589","Condition: Simple<br />Condition: Simple<br />RT: 2073.027<br />density: 0.0012710422","Condition: Simple<br />Condition: Simple<br />RT: 2074.333<br />density: 0.0012609375","Condition: Simple<br />Condition: Simple<br />RT: 2075.638<br />density: 0.0012507925","Condition: Simple<br />Condition: Simple<br />RT: 2076.943<br />density: 0.0012406121","Condition: Simple<br />Condition: Simple<br />RT: 2078.249<br />density: 0.0012303797","Condition: Simple<br />Condition: Simple<br />RT: 2079.554<br />density: 0.0012201321","Condition: Simple<br />Condition: Simple<br />RT: 2080.859<br />density: 0.0012098695","Condition: Simple<br />Condition: Simple<br />RT: 2082.164<br />density: 0.0011996009","Condition: Simple<br />Condition: Simple<br />RT: 2083.470<br />density: 0.0011893411","Condition: Simple<br />Condition: Simple<br />RT: 2084.775<br />density: 0.0011790917","Condition: Simple<br />Condition: Simple<br />RT: 2086.080<br />density: 0.0011688844","Condition: Simple<br />Condition: Simple<br />RT: 2087.386<br />density: 0.0011587094","Condition: Simple<br />Condition: Simple<br />RT: 2088.691<br />density: 0.0011485751","Condition: Simple<br />Condition: Simple<br />RT: 2089.996<br />density: 0.0011385270","Condition: Simple<br />Condition: Simple<br />RT: 2091.301<br />density: 0.0011285341","Condition: Simple<br />Condition: Simple<br />RT: 2092.607<br />density: 0.0011186155","Condition: Simple<br />Condition: Simple<br />RT: 2093.912<br />density: 0.0011088202","Condition: Simple<br />Condition: Simple<br />RT: 2095.217<br />density: 0.0010991011","Condition: Simple<br />Condition: Simple<br />RT: 2096.523<br />density: 0.0010894906","Condition: Simple<br />Condition: Simple<br />RT: 2097.828<br />density: 0.0010800317","Condition: Simple<br />Condition: Simple<br />RT: 2099.133<br />density: 0.0010706666","Condition: Simple<br />Condition: Simple<br />RT: 2100.438<br />density: 0.0010614428","Condition: Simple<br />Condition: Simple<br />RT: 2101.744<br />density: 0.0010523886","Condition: Simple<br />Condition: Simple<br />RT: 2103.049<br />density: 0.0010434418","Condition: Simple<br />Condition: Simple<br />RT: 2104.354<br />density: 0.0010346644","Condition: Simple<br />Condition: Simple<br />RT: 2105.659<br />density: 0.0010260640","Condition: Simple<br />Condition: Simple<br />RT: 2106.965<br />density: 0.0010175796","Condition: Simple<br />Condition: Simple<br />RT: 2108.270<br />density: 0.0010092860","Condition: Simple<br />Condition: Simple<br />RT: 2109.575<br />density: 0.0010011664","Condition: Simple<br />Condition: Simple<br />RT: 2110.881<br />density: 0.0009931659","Condition: Simple<br />Condition: Simple<br />RT: 2112.186<br />density: 0.0009853686","Condition: Simple<br />Condition: Simple<br />RT: 2113.491<br />density: 0.0009777333","Condition: Simple<br />Condition: Simple<br />RT: 2114.796<br />density: 0.0009702147","Condition: Simple<br />Condition: Simple<br />RT: 2116.102<br />density: 0.0009629009","Condition: Simple<br />Condition: Simple<br />RT: 2117.407<br />density: 0.0009557296","Condition: Simple<br />Condition: Simple<br />RT: 2118.712<br />density: 0.0009486671","Condition: Simple<br />Condition: Simple<br />RT: 2120.018<br />density: 0.0009417996","Condition: Simple<br />Condition: Simple<br />RT: 2121.323<br />density: 0.0009350495","Condition: Simple<br />Condition: Simple<br />RT: 2122.628<br />density: 0.0009283954","Condition: Simple<br />Condition: Simple<br />RT: 2123.933<br />density: 0.0009219146","Condition: Simple<br />Condition: Simple<br />RT: 2125.239<br />density: 0.0009155232","Condition: Simple<br />Condition: Simple<br />RT: 2126.544<br />density: 0.0009092106","Condition: Simple<br />Condition: Simple<br />RT: 2127.849<br />density: 0.0009030383","Condition: Simple<br />Condition: Simple<br />RT: 2129.155<br />density: 0.0008969265","Condition: Simple<br />Condition: Simple<br />RT: 2130.460<br />density: 0.0008908746","Condition: Simple<br />Condition: Simple<br />RT: 2131.765<br />density: 0.0008849168","Condition: Simple<br />Condition: Simple<br />RT: 2133.070<br />density: 0.0008789934","Condition: Simple<br />Condition: Simple<br />RT: 2134.376<br />density: 0.0008731080","Condition: Simple<br />Condition: Simple<br />RT: 2135.681<br />density: 0.0008672644","Condition: Simple<br />Condition: Simple<br />RT: 2136.986<br />density: 0.0008614312","Condition: Simple<br />Condition: Simple<br />RT: 2138.292<br />density: 0.0008556085","Condition: Simple<br />Condition: Simple<br />RT: 2139.597<br />density: 0.0008497787","Condition: Simple<br />Condition: Simple<br />RT: 2140.902<br />density: 0.0008439352","Condition: Simple<br />Condition: Simple<br />RT: 2142.207<br />density: 0.0008380709","Condition: Simple<br />Condition: Simple<br />RT: 2143.513<br />density: 0.0008321560","Condition: Simple<br />Condition: Simple<br />RT: 2144.818<br />density: 0.0008262047","Condition: Simple<br />Condition: Simple<br />RT: 2146.123<br />density: 0.0008201990","Condition: Simple<br />Condition: Simple<br />RT: 2147.429<br />density: 0.0008141067","Condition: Simple<br />Condition: Simple<br />RT: 2148.734<br />density: 0.0008079574","Condition: Simple<br />Condition: Simple<br />RT: 2150.039<br />density: 0.0008017198","Condition: Simple<br />Condition: Simple<br />RT: 2151.344<br />density: 0.0007953681","Condition: Simple<br />Condition: Simple<br />RT: 2152.650<br />density: 0.0007889419","Condition: Simple<br />Condition: Simple<br />RT: 2153.955<br />density: 0.0007823952","Condition: Simple<br />Condition: Simple<br />RT: 2155.260<br />density: 0.0007757161","Condition: Simple<br />Condition: Simple<br />RT: 2156.566<br />density: 0.0007689485","Condition: Simple<br />Condition: Simple<br />RT: 2157.871<br />density: 0.0007620319","Condition: Simple<br />Condition: Simple<br />RT: 2159.176<br />density: 0.0007549735","Condition: Simple<br />Condition: Simple<br />RT: 2160.481<br />density: 0.0007478166","Condition: Simple<br />Condition: Simple<br />RT: 2161.787<br />density: 0.0007404876","Condition: Simple<br />Condition: Simple<br />RT: 2163.092<br />density: 0.0007330156","Condition: Simple<br />Condition: Simple<br />RT: 2164.397<br />density: 0.0007254395","Condition: Simple<br />Condition: Simple<br />RT: 2165.703<br />density: 0.0007176750","Condition: Simple<br />Condition: Simple<br />RT: 2167.008<br />density: 0.0007097735","Condition: Simple<br />Condition: Simple<br />RT: 2168.313<br />density: 0.0007017663","Condition: Simple<br />Condition: Simple<br />RT: 2169.618<br />density: 0.0006935625","Condition: Simple<br />Condition: Simple<br />RT: 2170.924<br />density: 0.0006852333","Condition: Simple<br />Condition: Simple<br />RT: 2172.229<br />density: 0.0006768011","Condition: Simple<br />Condition: Simple<br />RT: 2173.534<br />density: 0.0006681723","Condition: Simple<br />Condition: Simple<br />RT: 2174.840<br />density: 0.0006594342","Condition: Simple<br />Condition: Simple<br />RT: 2176.145<br />density: 0.0006505994","Condition: Simple<br />Condition: Simple<br />RT: 2177.450<br />density: 0.0006415769","Condition: Simple<br />Condition: Simple<br />RT: 2178.755<br />density: 0.0006324637","Condition: Simple<br />Condition: Simple<br />RT: 2180.061<br />density: 0.0006232606","Condition: Simple<br />Condition: Simple<br />RT: 2181.366<br />density: 0.0006138929","Condition: Simple<br />Condition: Simple<br />RT: 2182.671<br />density: 0.0006044515","Condition: Simple<br />Condition: Simple<br />RT: 2183.977<br />density: 0.0005949278","Condition: Simple<br />Condition: Simple<br />RT: 2185.282<br />density: 0.0005852747","Condition: Simple<br />Condition: Simple<br />RT: 2186.587<br />density: 0.0005755628","Condition: Simple<br />Condition: Simple<br />RT: 2187.892<br />density: 0.0005657812","Condition: Simple<br />Condition: Simple<br />RT: 2189.198<br />density: 0.0005559068","Condition: Simple<br />Condition: Simple<br />RT: 2190.503<br />density: 0.0005459902","Condition: Simple<br />Condition: Simple<br />RT: 2191.808<br />density: 0.0005360215","Condition: Simple<br />Condition: Simple<br />RT: 2193.114<br />density: 0.0005259966","Condition: Simple<br />Condition: Simple<br />RT: 2194.419<br />density: 0.0005159471","Condition: Simple<br />Condition: Simple<br />RT: 2195.724<br />density: 0.0005058675","Condition: Simple<br />Condition: Simple<br />RT: 2197.029<br />density: 0.0004957668","Condition: Simple<br />Condition: Simple<br />RT: 2198.335<br />density: 0.0004856598","Condition: Simple<br />Condition: Simple<br />RT: 2199.640<br />density: 0.0004755488","Condition: Simple<br />Condition: Simple<br />RT: 2200.945<br />density: 0.0004654491","Condition: Simple<br />Condition: Simple<br />RT: 2202.250<br />density: 0.0004553617","Condition: Simple<br />Condition: Simple<br />RT: 2203.556<br />density: 0.0004452997","Condition: Simple<br />Condition: Simple<br />RT: 2204.861<br />density: 0.0004352783","Condition: Simple<br />Condition: Simple<br />RT: 2206.166<br />density: 0.0004252875","Condition: Simple<br />Condition: Simple<br />RT: 2207.472<br />density: 0.0004153544","Condition: Simple<br />Condition: Simple<br />RT: 2208.777<br />density: 0.0004054872","Condition: Simple<br />Condition: Simple<br />RT: 2210.082<br />density: 0.0003956685","Condition: Simple<br />Condition: Simple<br />RT: 2211.387<br />density: 0.0003859421","Condition: Simple<br />Condition: Simple<br />RT: 2212.693<br />density: 0.0003763028","Condition: Simple<br />Condition: Simple<br />RT: 2213.998<br />density: 0.0003667293","Condition: Simple<br />Condition: Simple<br />RT: 2215.303<br />density: 0.0003572841","Condition: Simple<br />Condition: Simple<br />RT: 2216.609<br />density: 0.0003479431","Condition: Simple<br />Condition: Simple<br />RT: 2217.914<br />density: 0.0003386842","Condition: Simple<br />Condition: Simple<br />RT: 2219.219<br />density: 0.0003295907","Condition: Simple<br />Condition: Simple<br />RT: 2220.524<br />density: 0.0003206144","Condition: Simple<br />Condition: Simple<br />RT: 2221.830<br />density: 0.0003117354","Condition: Simple<br />Condition: Simple<br />RT: 2223.135<br />density: 0.0003030596","Condition: Simple<br />Condition: Simple<br />RT: 2224.440<br />density: 0.0002945096","Condition: Simple<br />Condition: Simple<br />RT: 2225.746<br />density: 0.0002860713","Condition: Simple<br />Condition: Simple<br />RT: 2227.051<br />density: 0.0002778737","Condition: Simple<br />Condition: Simple<br />RT: 2228.356<br />density: 0.0002698069","Condition: Simple<br />Condition: Simple<br />RT: 2229.661<br />density: 0.0002618694","Condition: Simple<br />Condition: Simple<br />RT: 2230.967<br />density: 0.0002542004","Condition: Simple<br />Condition: Simple<br />RT: 2232.272<br />density: 0.0002466681","Condition: Simple<br />Condition: Simple<br />RT: 2233.577<br />density: 0.0002392890","Condition: Simple<br />Condition: Simple<br />RT: 2234.883<br />density: 0.0002321898","Condition: Simple<br />Condition: Simple<br />RT: 2236.188<br />density: 0.0002252375","Condition: Simple<br />Condition: Simple<br />RT: 2237.493<br />density: 0.0002184625","Condition: Simple<br />Condition: Simple<br />RT: 2238.798<br />density: 0.0002119739","Condition: Simple<br />Condition: Simple<br />RT: 2240.104<br />density: 0.0002056410","Condition: Simple<br />Condition: Simple<br />RT: 2241.409<br />density: 0.0001995091","Condition: Simple<br />Condition: Simple<br />RT: 2242.714<br />density: 0.0001936654","Condition: Simple<br />Condition: Simple<br />RT: 2244.020<br />density: 0.0001879844","Condition: Simple<br />Condition: Simple<br />RT: 2245.325<br />density: 0.0001825274","Condition: Simple<br />Condition: Simple<br />RT: 2246.630<br />density: 0.0001773559","Condition: Simple<br />Condition: Simple<br />RT: 2247.935<br />density: 0.0001723525","Condition: Simple<br />Condition: Simple<br />RT: 2249.241<br />density: 0.0001675944","Condition: Simple<br />Condition: Simple<br />RT: 2250.546<br />density: 0.0001631150","Condition: Simple<br />Condition: Simple<br />RT: 2251.851<br />density: 0.0001588072","Condition: Simple<br />Condition: Simple<br />RT: 2253.157<br />density: 0.0001547637","Condition: Simple<br />Condition: Simple<br />RT: 2254.462<br />density: 0.0001509882","Condition: Simple<br />Condition: Simple<br />RT: 2255.767<br />density: 0.0001473858","Condition: Simple<br />Condition: Simple<br />RT: 2257.072<br />density: 0.0001440640","Condition: Simple<br />Condition: Simple<br />RT: 2258.378<br />density: 0.0001409957","Condition: Simple<br />Condition: Simple<br />RT: 2259.683<br />density: 0.0001381001","Condition: Simple<br />Condition: Simple<br />RT: 2260.988<br />density: 0.0001354976","Condition: Simple<br />Condition: Simple<br />RT: 2262.294<br />density: 0.0001331309","Condition: Simple<br />Condition: Simple<br />RT: 2263.599<br />density: 0.0001309344","Condition: Simple<br />Condition: Simple<br />RT: 2264.904<br />density: 0.0001290389","Condition: Simple<br />Condition: Simple<br />RT: 2266.209<br />density: 0.0001273590","Condition: Simple<br />Condition: Simple<br />RT: 2267.515<br />density: 0.0001258444","Condition: Simple<br />Condition: Simple<br />RT: 2268.820<br />density: 0.0001246336","Condition: Simple<br />Condition: Simple<br />RT: 2270.125<br />density: 0.0001236158","Condition: Simple<br />Condition: Simple<br />RT: 2271.431<br />density: 0.0001227563","Condition: Simple<br />Condition: Simple<br />RT: 2272.736<br />density: 0.0001221976","Condition: Simple<br />Condition: Simple<br />RT: 2274.041<br />density: 0.0001218076","Condition: Simple<br />Condition: Simple<br />RT: 2275.346<br />density: 0.0001215665","Condition: Simple<br />Condition: Simple<br />RT: 2276.652<br />density: 0.0001216168","Condition: Simple<br />Condition: Simple<br />RT: 2277.957<br />density: 0.0001218108","Condition: Simple<br />Condition: Simple<br />RT: 2279.262<br />density: 0.0001221463","Condition: Simple<br />Condition: Simple<br />RT: 2280.568<br />density: 0.0001227480","Condition: Simple<br />Condition: Simple<br />RT: 2281.873<br />density: 0.0001234725","Condition: Simple<br />Condition: Simple<br />RT: 2283.178<br />density: 0.0001243336","Condition: Simple<br />Condition: Simple<br />RT: 2284.483<br />density: 0.0001254195","Condition: Simple<br />Condition: Simple<br />RT: 2285.789<br />density: 0.0001266121","Condition: Simple<br />Condition: Simple<br />RT: 2287.094<br />density: 0.0001279317","Condition: Simple<br />Condition: Simple<br />RT: 2288.399<br />density: 0.0001294332","Condition: Simple<br />Condition: Simple<br />RT: 2289.705<br />density: 0.0001310238","Condition: Simple<br />Condition: Simple<br />RT: 2291.010<br />density: 0.0001327263","Condition: Simple<br />Condition: Simple<br />RT: 2292.315<br />density: 0.0001345678","Condition: Simple<br />Condition: Simple<br />RT: 2293.620<br />density: 0.0001364792","Condition: Simple<br />Condition: Simple<br />RT: 2294.926<br />density: 0.0001384822","Condition: Simple<br />Condition: Simple<br />RT: 2296.231<br />density: 0.0001405821","Condition: Simple<br />Condition: Simple<br />RT: 2297.536<br />density: 0.0001427316","Condition: Simple<br />Condition: Simple<br />RT: 2298.841<br />density: 0.0001449474","Condition: Simple<br />Condition: Simple<br />RT: 2300.147<br />density: 0.0001472198","Condition: Simple<br />Condition: Simple<br />RT: 2301.452<br />density: 0.0001495210","Condition: Simple<br />Condition: Simple<br />RT: 2302.757<br />density: 0.0001518584","Condition: Simple<br />Condition: Simple<br />RT: 2304.063<br />density: 0.0001542153","Condition: Simple<br />Condition: Simple<br />RT: 2305.368<br />density: 0.0001565796","Condition: Simple<br />Condition: Simple<br />RT: 2306.673<br />density: 0.0001589463","Condition: Simple<br />Condition: Simple<br />RT: 2307.978<br />density: 0.0001612990","Condition: Simple<br />Condition: Simple<br />RT: 2309.284<br />density: 0.0001636381","Condition: Simple<br />Condition: Simple<br />RT: 2310.589<br />density: 0.0001659427","Condition: Simple<br />Condition: Simple<br />RT: 2311.894<br />density: 0.0001682046","Condition: Simple<br />Condition: Simple<br />RT: 2313.200<br />density: 0.0001704326","Condition: Simple<br />Condition: Simple<br />RT: 2314.505<br />density: 0.0001725872","Condition: Simple<br />Condition: Simple<br />RT: 2315.810<br />density: 0.0001746755","Condition: Simple<br />Condition: Simple<br />RT: 2317.115<br />density: 0.0001767108","Condition: Simple<br />Condition: Simple<br />RT: 2318.421<br />density: 0.0001786334","Condition: Simple<br />Condition: Simple<br />RT: 2319.726<br />density: 0.0001804717","Condition: Simple<br />Condition: Simple<br />RT: 2321.031<br />density: 0.0001822396","Condition: Simple<br />Condition: Simple<br />RT: 2322.337<br />density: 0.0001838563","Condition: Simple<br />Condition: Simple<br />RT: 2323.642<br />density: 0.0001853765","Condition: Simple<br />Condition: Simple<br />RT: 2324.947<br />density: 0.0001868110","Condition: Simple<br />Condition: Simple<br />RT: 2326.252<br />density: 0.0001880583","Condition: Simple<br />Condition: Simple<br />RT: 2327.558<br />density: 0.0001892023","Condition: Simple<br />Condition: Simple<br />RT: 2328.863<br />density: 0.0001902446","Condition: Simple<br />Condition: Simple<br />RT: 2330.168<br />density: 0.0001910743","Condition: Simple<br />Condition: Simple<br />RT: 2331.474<br />density: 0.0001917958","Condition: Simple<br />Condition: Simple<br />RT: 2332.779<br />density: 0.0001923964","Condition: Simple<br />Condition: Simple<br />RT: 2334.084<br />density: 0.0001927765","Condition: Simple<br />Condition: Simple<br />RT: 2335.389<br />density: 0.0001930421","Condition: Simple<br />Condition: Simple<br />RT: 2336.695<br />density: 0.0001931698","Condition: Simple<br />Condition: Simple<br />RT: 2338.000<br />density: 0.0001930773","Condition: Simple<br />Condition: Simple<br />RT: 2338.000<br />density: 0.0001930773","Condition: Simple<br />Condition: Simple<br />RT: 2336.695<br />density: 0.0001931698","Condition: Simple<br />Condition: Simple<br />RT: 2335.389<br />density: 0.0001930421","Condition: Simple<br />Condition: Simple<br />RT: 2334.084<br />density: 0.0001927765","Condition: Simple<br />Condition: Simple<br />RT: 2332.779<br />density: 0.0001923964","Condition: Simple<br />Condition: Simple<br />RT: 2331.474<br />density: 0.0001917958","Condition: Simple<br />Condition: Simple<br />RT: 2330.168<br />density: 0.0001910743","Condition: Simple<br />Condition: Simple<br />RT: 2328.863<br />density: 0.0001902446","Condition: Simple<br />Condition: Simple<br />RT: 2327.558<br />density: 0.0001892023","Condition: Simple<br />Condition: Simple<br />RT: 2326.252<br />density: 0.0001880583","Condition: Simple<br />Condition: Simple<br />RT: 2324.947<br />density: 0.0001868110","Condition: Simple<br />Condition: Simple<br />RT: 2323.642<br />density: 0.0001853765","Condition: Simple<br />Condition: Simple<br />RT: 2322.337<br />density: 0.0001838563","Condition: Simple<br />Condition: Simple<br />RT: 2321.031<br />density: 0.0001822396","Condition: Simple<br />Condition: Simple<br />RT: 2319.726<br />density: 0.0001804717","Condition: Simple<br />Condition: Simple<br />RT: 2318.421<br />density: 0.0001786334","Condition: Simple<br />Condition: Simple<br />RT: 2317.115<br />density: 0.0001767108","Condition: Simple<br />Condition: Simple<br />RT: 2315.810<br />density: 0.0001746755","Condition: Simple<br />Condition: Simple<br />RT: 2314.505<br />density: 0.0001725872","Condition: Simple<br />Condition: Simple<br />RT: 2313.200<br />density: 0.0001704326","Condition: Simple<br />Condition: Simple<br />RT: 2311.894<br />density: 0.0001682046","Condition: Simple<br />Condition: Simple<br />RT: 2310.589<br />density: 0.0001659427","Condition: Simple<br />Condition: Simple<br />RT: 2309.284<br />density: 0.0001636381","Condition: Simple<br />Condition: Simple<br />RT: 2307.978<br />density: 0.0001612990","Condition: Simple<br />Condition: Simple<br />RT: 2306.673<br />density: 0.0001589463","Condition: Simple<br />Condition: Simple<br />RT: 2305.368<br />density: 0.0001565796","Condition: Simple<br />Condition: Simple<br />RT: 2304.063<br />density: 0.0001542153","Condition: Simple<br />Condition: Simple<br />RT: 2302.757<br />density: 0.0001518584","Condition: Simple<br />Condition: Simple<br />RT: 2301.452<br />density: 0.0001495210","Condition: Simple<br />Condition: Simple<br />RT: 2300.147<br />density: 0.0001472198","Condition: Simple<br />Condition: Simple<br />RT: 2298.841<br />density: 0.0001449474","Condition: Simple<br />Condition: Simple<br />RT: 2297.536<br />density: 0.0001427316","Condition: Simple<br />Condition: Simple<br />RT: 2296.231<br />density: 0.0001405821","Condition: Simple<br />Condition: Simple<br />RT: 2294.926<br />density: 0.0001384822","Condition: Simple<br />Condition: Simple<br />RT: 2293.620<br />density: 0.0001364792","Condition: Simple<br />Condition: Simple<br />RT: 2292.315<br />density: 0.0001345678","Condition: Simple<br />Condition: Simple<br />RT: 2291.010<br />density: 0.0001327263","Condition: Simple<br />Condition: Simple<br />RT: 2289.705<br />density: 0.0001310238","Condition: Simple<br />Condition: Simple<br />RT: 2288.399<br />density: 0.0001294332","Condition: Simple<br />Condition: Simple<br />RT: 2287.094<br />density: 0.0001279317","Condition: Simple<br />Condition: Simple<br />RT: 2285.789<br />density: 0.0001266121","Condition: Simple<br />Condition: Simple<br />RT: 2284.483<br />density: 0.0001254195","Condition: Simple<br />Condition: Simple<br />RT: 2283.178<br />density: 0.0001243336","Condition: Simple<br />Condition: Simple<br />RT: 2281.873<br />density: 0.0001234725","Condition: Simple<br />Condition: Simple<br />RT: 2280.568<br />density: 0.0001227480","Condition: Simple<br />Condition: Simple<br />RT: 2279.262<br />density: 0.0001221463","Condition: Simple<br />Condition: Simple<br />RT: 2277.957<br />density: 0.0001218108","Condition: Simple<br />Condition: Simple<br />RT: 2276.652<br />density: 0.0001216168","Condition: Simple<br />Condition: Simple<br />RT: 2275.346<br />density: 0.0001215665","Condition: Simple<br />Condition: Simple<br />RT: 2274.041<br />density: 0.0001218076","Condition: Simple<br />Condition: Simple<br />RT: 2272.736<br />density: 0.0001221976","Condition: Simple<br />Condition: Simple<br />RT: 2271.431<br />density: 0.0001227563","Condition: Simple<br />Condition: Simple<br />RT: 2270.125<br />density: 0.0001236158","Condition: Simple<br />Condition: Simple<br />RT: 2268.820<br />density: 0.0001246336","Condition: Simple<br />Condition: Simple<br />RT: 2267.515<br />density: 0.0001258444","Condition: Simple<br />Condition: Simple<br />RT: 2266.209<br />density: 0.0001273590","Condition: Simple<br />Condition: Simple<br />RT: 2264.904<br />density: 0.0001290389","Condition: Simple<br />Condition: Simple<br />RT: 2263.599<br />density: 0.0001309344","Condition: Simple<br />Condition: Simple<br />RT: 2262.294<br />density: 0.0001331309","Condition: Simple<br />Condition: Simple<br />RT: 2260.988<br />density: 0.0001354976","Condition: Simple<br />Condition: Simple<br />RT: 2259.683<br />density: 0.0001381001","Condition: Simple<br />Condition: Simple<br />RT: 2258.378<br />density: 0.0001409957","Condition: Simple<br />Condition: Simple<br />RT: 2257.072<br />density: 0.0001440640","Condition: Simple<br />Condition: Simple<br />RT: 2255.767<br />density: 0.0001473858","Condition: Simple<br />Condition: Simple<br />RT: 2254.462<br />density: 0.0001509882","Condition: Simple<br />Condition: Simple<br />RT: 2253.157<br />density: 0.0001547637","Condition: Simple<br />Condition: Simple<br />RT: 2251.851<br />density: 0.0001588072","Condition: Simple<br />Condition: Simple<br />RT: 2250.546<br />density: 0.0001631150","Condition: Simple<br />Condition: Simple<br />RT: 2249.241<br />density: 0.0001675944","Condition: Simple<br />Condition: Simple<br />RT: 2247.935<br />density: 0.0001723525","Condition: Simple<br />Condition: Simple<br />RT: 2246.630<br />density: 0.0001773559","Condition: Simple<br />Condition: Simple<br />RT: 2245.325<br />density: 0.0001825274","Condition: Simple<br />Condition: Simple<br />RT: 2244.020<br />density: 0.0001879844","Condition: Simple<br />Condition: Simple<br />RT: 2242.714<br />density: 0.0001936654","Condition: Simple<br />Condition: Simple<br />RT: 2241.409<br />density: 0.0001995091","Condition: Simple<br />Condition: Simple<br />RT: 2240.104<br />density: 0.0002056410","Condition: Simple<br />Condition: Simple<br />RT: 2238.798<br />density: 0.0002119739","Condition: Simple<br />Condition: Simple<br />RT: 2237.493<br />density: 0.0002184625","Condition: Simple<br />Condition: Simple<br />RT: 2236.188<br />density: 0.0002252375","Condition: Simple<br />Condition: Simple<br />RT: 2234.883<br />density: 0.0002321898","Condition: Simple<br />Condition: Simple<br />RT: 2233.577<br />density: 0.0002392890","Condition: Simple<br />Condition: Simple<br />RT: 2232.272<br />density: 0.0002466681","Condition: Simple<br />Condition: Simple<br />RT: 2230.967<br />density: 0.0002542004","Condition: Simple<br />Condition: Simple<br />RT: 2229.661<br />density: 0.0002618694","Condition: Simple<br />Condition: Simple<br />RT: 2228.356<br />density: 0.0002698069","Condition: Simple<br />Condition: Simple<br />RT: 2227.051<br />density: 0.0002778737","Condition: Simple<br />Condition: Simple<br />RT: 2225.746<br />density: 0.0002860713","Condition: Simple<br />Condition: Simple<br />RT: 2224.440<br />density: 0.0002945096","Condition: Simple<br />Condition: Simple<br />RT: 2223.135<br />density: 0.0003030596","Condition: Simple<br />Condition: Simple<br />RT: 2221.830<br />density: 0.0003117354","Condition: Simple<br />Condition: Simple<br />RT: 2220.524<br />density: 0.0003206144","Condition: Simple<br />Condition: Simple<br />RT: 2219.219<br />density: 0.0003295907","Condition: Simple<br />Condition: Simple<br />RT: 2217.914<br />density: 0.0003386842","Condition: Simple<br />Condition: Simple<br />RT: 2216.609<br />density: 0.0003479431","Condition: Simple<br />Condition: Simple<br />RT: 2215.303<br />density: 0.0003572841","Condition: Simple<br />Condition: Simple<br />RT: 2213.998<br />density: 0.0003667293","Condition: Simple<br />Condition: Simple<br />RT: 2212.693<br />density: 0.0003763028","Condition: Simple<br />Condition: Simple<br />RT: 2211.387<br />density: 0.0003859421","Condition: Simple<br />Condition: Simple<br />RT: 2210.082<br />density: 0.0003956685","Condition: Simple<br />Condition: Simple<br />RT: 2208.777<br />density: 0.0004054872","Condition: Simple<br />Condition: Simple<br />RT: 2207.472<br />density: 0.0004153544","Condition: Simple<br />Condition: Simple<br />RT: 2206.166<br />density: 0.0004252875","Condition: Simple<br />Condition: Simple<br />RT: 2204.861<br />density: 0.0004352783","Condition: Simple<br />Condition: Simple<br />RT: 2203.556<br />density: 0.0004452997","Condition: Simple<br />Condition: Simple<br />RT: 2202.250<br />density: 0.0004553617","Condition: Simple<br />Condition: Simple<br />RT: 2200.945<br />density: 0.0004654491","Condition: Simple<br />Condition: Simple<br />RT: 2199.640<br />density: 0.0004755488","Condition: Simple<br />Condition: Simple<br />RT: 2198.335<br />density: 0.0004856598","Condition: Simple<br />Condition: Simple<br />RT: 2197.029<br />density: 0.0004957668","Condition: Simple<br />Condition: Simple<br />RT: 2195.724<br />density: 0.0005058675","Condition: Simple<br />Condition: Simple<br />RT: 2194.419<br />density: 0.0005159471","Condition: Simple<br />Condition: Simple<br />RT: 2193.114<br />density: 0.0005259966","Condition: Simple<br />Condition: Simple<br />RT: 2191.808<br />density: 0.0005360215","Condition: Simple<br />Condition: Simple<br />RT: 2190.503<br />density: 0.0005459902","Condition: Simple<br />Condition: Simple<br />RT: 2189.198<br />density: 0.0005559068","Condition: Simple<br />Condition: Simple<br />RT: 2187.892<br />density: 0.0005657812","Condition: Simple<br />Condition: Simple<br />RT: 2186.587<br />density: 0.0005755628","Condition: Simple<br />Condition: Simple<br />RT: 2185.282<br />density: 0.0005852747","Condition: Simple<br />Condition: Simple<br />RT: 2183.977<br />density: 0.0005949278","Condition: Simple<br />Condition: Simple<br />RT: 2182.671<br />density: 0.0006044515","Condition: Simple<br />Condition: Simple<br />RT: 2181.366<br />density: 0.0006138929","Condition: Simple<br />Condition: Simple<br />RT: 2180.061<br />density: 0.0006232606","Condition: Simple<br />Condition: Simple<br />RT: 2178.755<br />density: 0.0006324637","Condition: Simple<br />Condition: Simple<br />RT: 2177.450<br />density: 0.0006415769","Condition: Simple<br />Condition: Simple<br />RT: 2176.145<br />density: 0.0006505994","Condition: Simple<br />Condition: Simple<br />RT: 2174.840<br />density: 0.0006594342","Condition: Simple<br />Condition: Simple<br />RT: 2173.534<br />density: 0.0006681723","Condition: Simple<br />Condition: Simple<br />RT: 2172.229<br />density: 0.0006768011","Condition: Simple<br />Condition: Simple<br />RT: 2170.924<br />density: 0.0006852333","Condition: Simple<br />Condition: Simple<br />RT: 2169.618<br />density: 0.0006935625","Condition: Simple<br />Condition: Simple<br />RT: 2168.313<br />density: 0.0007017663","Condition: Simple<br />Condition: Simple<br />RT: 2167.008<br />density: 0.0007097735","Condition: Simple<br />Condition: Simple<br />RT: 2165.703<br />density: 0.0007176750","Condition: Simple<br />Condition: Simple<br />RT: 2164.397<br />density: 0.0007254395","Condition: Simple<br />Condition: Simple<br />RT: 2163.092<br />density: 0.0007330156","Condition: Simple<br />Condition: Simple<br />RT: 2161.787<br />density: 0.0007404876","Condition: Simple<br />Condition: Simple<br />RT: 2160.481<br />density: 0.0007478166","Condition: Simple<br />Condition: Simple<br />RT: 2159.176<br />density: 0.0007549735","Condition: Simple<br />Condition: Simple<br />RT: 2157.871<br />density: 0.0007620319","Condition: Simple<br />Condition: Simple<br />RT: 2156.566<br />density: 0.0007689485","Condition: Simple<br />Condition: Simple<br />RT: 2155.260<br />density: 0.0007757161","Condition: Simple<br />Condition: Simple<br />RT: 2153.955<br />density: 0.0007823952","Condition: Simple<br />Condition: Simple<br />RT: 2152.650<br />density: 0.0007889419","Condition: Simple<br />Condition: Simple<br />RT: 2151.344<br />density: 0.0007953681","Condition: Simple<br />Condition: Simple<br />RT: 2150.039<br />density: 0.0008017198","Condition: Simple<br />Condition: Simple<br />RT: 2148.734<br />density: 0.0008079574","Condition: Simple<br />Condition: Simple<br />RT: 2147.429<br />density: 0.0008141067","Condition: Simple<br />Condition: Simple<br />RT: 2146.123<br />density: 0.0008201990","Condition: Simple<br />Condition: Simple<br />RT: 2144.818<br />density: 0.0008262047","Condition: Simple<br />Condition: Simple<br />RT: 2143.513<br />density: 0.0008321560","Condition: Simple<br />Condition: Simple<br />RT: 2142.207<br />density: 0.0008380709","Condition: Simple<br />Condition: Simple<br />RT: 2140.902<br />density: 0.0008439352","Condition: Simple<br />Condition: Simple<br />RT: 2139.597<br />density: 0.0008497787","Condition: Simple<br />Condition: Simple<br />RT: 2138.292<br />density: 0.0008556085","Condition: Simple<br />Condition: Simple<br />RT: 2136.986<br />density: 0.0008614312","Condition: Simple<br />Condition: Simple<br />RT: 2135.681<br />density: 0.0008672644","Condition: Simple<br />Condition: Simple<br />RT: 2134.376<br />density: 0.0008731080","Condition: Simple<br />Condition: Simple<br />RT: 2133.070<br />density: 0.0008789934","Condition: Simple<br />Condition: Simple<br />RT: 2131.765<br />density: 0.0008849168","Condition: Simple<br />Condition: Simple<br />RT: 2130.460<br />density: 0.0008908746","Condition: Simple<br />Condition: Simple<br />RT: 2129.155<br />density: 0.0008969265","Condition: Simple<br />Condition: Simple<br />RT: 2127.849<br />density: 0.0009030383","Condition: Simple<br />Condition: Simple<br />RT: 2126.544<br />density: 0.0009092106","Condition: Simple<br />Condition: Simple<br />RT: 2125.239<br />density: 0.0009155232","Condition: Simple<br />Condition: Simple<br />RT: 2123.933<br />density: 0.0009219146","Condition: Simple<br />Condition: Simple<br />RT: 2122.628<br />density: 0.0009283954","Condition: Simple<br />Condition: Simple<br />RT: 2121.323<br />density: 0.0009350495","Condition: Simple<br />Condition: Simple<br />RT: 2120.018<br />density: 0.0009417996","Condition: Simple<br />Condition: Simple<br />RT: 2118.712<br />density: 0.0009486671","Condition: Simple<br />Condition: Simple<br />RT: 2117.407<br />density: 0.0009557296","Condition: Simple<br />Condition: Simple<br />RT: 2116.102<br />density: 0.0009629009","Condition: Simple<br />Condition: Simple<br />RT: 2114.796<br />density: 0.0009702147","Condition: Simple<br />Condition: Simple<br />RT: 2113.491<br />density: 0.0009777333","Condition: Simple<br />Condition: Simple<br />RT: 2112.186<br />density: 0.0009853686","Condition: Simple<br />Condition: Simple<br />RT: 2110.881<br />density: 0.0009931659","Condition: Simple<br />Condition: Simple<br />RT: 2109.575<br />density: 0.0010011664","Condition: Simple<br />Condition: Simple<br />RT: 2108.270<br />density: 0.0010092860","Condition: Simple<br />Condition: Simple<br />RT: 2106.965<br />density: 0.0010175796","Condition: Simple<br />Condition: Simple<br />RT: 2105.659<br />density: 0.0010260640","Condition: Simple<br />Condition: Simple<br />RT: 2104.354<br />density: 0.0010346644","Condition: Simple<br />Condition: Simple<br />RT: 2103.049<br />density: 0.0010434418","Condition: Simple<br />Condition: Simple<br />RT: 2101.744<br />density: 0.0010523886","Condition: Simple<br />Condition: Simple<br />RT: 2100.438<br />density: 0.0010614428","Condition: Simple<br />Condition: Simple<br />RT: 2099.133<br />density: 0.0010706666","Condition: Simple<br />Condition: Simple<br />RT: 2097.828<br />density: 0.0010800317","Condition: Simple<br />Condition: Simple<br />RT: 2096.523<br />density: 0.0010894906","Condition: Simple<br />Condition: Simple<br />RT: 2095.217<br />density: 0.0010991011","Condition: Simple<br />Condition: Simple<br />RT: 2093.912<br />density: 0.0011088202","Condition: Simple<br />Condition: Simple<br />RT: 2092.607<br />density: 0.0011186155","Condition: Simple<br />Condition: Simple<br />RT: 2091.301<br />density: 0.0011285341","Condition: Simple<br />Condition: Simple<br />RT: 2089.996<br />density: 0.0011385270","Condition: Simple<br />Condition: Simple<br />RT: 2088.691<br />density: 0.0011485751","Condition: Simple<br />Condition: Simple<br />RT: 2087.386<br />density: 0.0011587094","Condition: Simple<br />Condition: Simple<br />RT: 2086.080<br />density: 0.0011688844","Condition: Simple<br />Condition: Simple<br />RT: 2084.775<br />density: 0.0011790917","Condition: Simple<br />Condition: Simple<br />RT: 2083.470<br />density: 0.0011893411","Condition: Simple<br />Condition: Simple<br />RT: 2082.164<br />density: 0.0011996009","Condition: Simple<br />Condition: Simple<br />RT: 2080.859<br />density: 0.0012098695","Condition: Simple<br />Condition: Simple<br />RT: 2079.554<br />density: 0.0012201321","Condition: Simple<br />Condition: Simple<br />RT: 2078.249<br />density: 0.0012303797","Condition: Simple<br />Condition: Simple<br />RT: 2076.943<br />density: 0.0012406121","Condition: Simple<br />Condition: Simple<br />RT: 2075.638<br />density: 0.0012507925","Condition: Simple<br />Condition: Simple<br />RT: 2074.333<br />density: 0.0012609375","Condition: Simple<br />Condition: Simple<br />RT: 2073.027<br />density: 0.0012710422","Condition: Simple<br />Condition: Simple<br />RT: 2071.722<br />density: 0.0012810589","Condition: Simple<br />Condition: Simple<br />RT: 2070.417<br />density: 0.0012910237","Condition: Simple<br />Condition: Simple<br />RT: 2069.112<br />density: 0.0013009243","Condition: Simple<br />Condition: Simple<br />RT: 2067.806<br />density: 0.0013107132","Condition: Simple<br />Condition: Simple<br />RT: 2066.501<br />density: 0.0013204383","Condition: Simple<br />Condition: Simple<br />RT: 2065.196<br />density: 0.0013300795","Condition: Simple<br />Condition: Simple<br />RT: 2063.890<br />density: 0.0013395982","Condition: Simple<br />Condition: Simple<br />RT: 2062.585<br />density: 0.0013490472","Condition: Simple<br />Condition: Simple<br />RT: 2061.280<br />density: 0.0013583996","Condition: Simple<br />Condition: Simple<br />RT: 2059.975<br />density: 0.0013676321","Condition: Simple<br />Condition: Simple<br />RT: 2058.669<br />density: 0.0013767956","Condition: Simple<br />Condition: Simple<br />RT: 2057.364<br />density: 0.0013858594","Condition: Simple<br />Condition: Simple<br />RT: 2056.059<br />density: 0.0013948187","Condition: Simple<br />Condition: Simple<br />RT: 2054.753<br />density: 0.0014037167","Condition: Simple<br />Condition: Simple<br />RT: 2053.448<br />density: 0.0014125246","Condition: Simple<br />Condition: Simple<br />RT: 2052.143<br />density: 0.0014212544","Condition: Simple<br />Condition: Simple<br />RT: 2050.838<br />density: 0.0014299383","Condition: Simple<br />Condition: Simple<br />RT: 2049.532<br />density: 0.0014385559","Condition: Simple<br />Condition: Simple<br />RT: 2048.227<br />density: 0.0014471316","Condition: Simple<br />Condition: Simple<br />RT: 2046.922<br />density: 0.0014556837","Condition: Simple<br />Condition: Simple<br />RT: 2045.616<br />density: 0.0014642101","Condition: Simple<br />Condition: Simple<br />RT: 2044.311<br />density: 0.0014727374","Condition: Simple<br />Condition: Simple<br />RT: 2043.006<br />density: 0.0014812704","Condition: Simple<br />Condition: Simple<br />RT: 2041.701<br />density: 0.0014898358","Condition: Simple<br />Condition: Simple<br />RT: 2040.395<br />density: 0.0014984491","Condition: Simple<br />Condition: Simple<br />RT: 2039.090<br />density: 0.0015071038","Condition: Simple<br />Condition: Simple<br />RT: 2037.785<br />density: 0.0015158669","Condition: Simple<br />Condition: Simple<br />RT: 2036.479<br />density: 0.0015247262","Condition: Simple<br />Condition: Simple<br />RT: 2035.174<br />density: 0.0015336681","Condition: Simple<br />Condition: Simple<br />RT: 2033.869<br />density: 0.0015428117","Condition: Simple<br />Condition: Simple<br />RT: 2032.564<br />density: 0.0015520984","Condition: Simple<br />Condition: Simple<br />RT: 2031.258<br />density: 0.0015615134","Condition: Simple<br />Condition: Simple<br />RT: 2029.953<br />density: 0.0015712397","Condition: Simple<br />Condition: Simple<br />RT: 2028.648<br />density: 0.0015811517","Condition: Simple<br />Condition: Simple<br />RT: 2027.342<br />density: 0.0015912496","Condition: Simple<br />Condition: Simple<br />RT: 2026.037<br />density: 0.0016017653","Condition: Simple<br />Condition: Simple<br />RT: 2024.732<br />density: 0.0016125113","Condition: Simple<br />Condition: Simple<br />RT: 2023.427<br />density: 0.0016235177","Condition: Simple<br />Condition: Simple<br />RT: 2022.121<br />density: 0.0016350294","Condition: Simple<br />Condition: Simple<br />RT: 2020.816<br />density: 0.0016468224","Condition: Simple<br />Condition: Simple<br />RT: 2019.511<br />density: 0.0016589595","Condition: Simple<br />Condition: Simple<br />RT: 2018.205<br />density: 0.0016716792","Condition: Simple<br />Condition: Simple<br />RT: 2016.900<br />density: 0.0016847301","Condition: Simple<br />Condition: Simple<br />RT: 2015.595<br />density: 0.0016982155","Condition: Simple<br />Condition: Simple<br />RT: 2014.290<br />density: 0.0017123476","Condition: Simple<br />Condition: Simple<br />RT: 2012.984<br />density: 0.0017268575","Condition: Simple<br />Condition: Simple<br />RT: 2011.679<br />density: 0.0017418964","Condition: Simple<br />Condition: Simple<br />RT: 2010.374<br />density: 0.0017576303","Condition: Simple<br />Condition: Simple<br />RT: 2009.068<br />density: 0.0017737840","Condition: Simple<br />Condition: Simple<br />RT: 2007.763<br />density: 0.0017905613","Condition: Simple<br />Condition: Simple<br />RT: 2006.458<br />density: 0.0018080640","Condition: Simple<br />Condition: Simple<br />RT: 2005.153<br />density: 0.0018260224","Condition: Simple<br />Condition: Simple<br />RT: 2003.847<br />density: 0.0018446950","Condition: Simple<br />Condition: Simple<br />RT: 2002.542<br />density: 0.0018641046","Condition: Simple<br />Condition: Simple<br />RT: 2001.237<br />density: 0.0018839978","Condition: Simple<br />Condition: Simple<br />RT: 1999.932<br />density: 0.0019046876","Condition: Simple<br />Condition: Simple<br />RT: 1998.626<br />density: 0.0019261064","Condition: Simple<br />Condition: Simple<br />RT: 1997.321<br />density: 0.0019480277","Condition: Simple<br />Condition: Simple<br />RT: 1996.016<br />density: 0.0019708144","Condition: Simple<br />Condition: Simple<br />RT: 1994.710<br />density: 0.0019943034","Condition: Simple<br />Condition: Simple<br />RT: 1993.405<br />density: 0.0020183032","Condition: Simple<br />Condition: Simple<br />RT: 1992.100<br />density: 0.0020432191","Condition: Simple<br />Condition: Simple<br />RT: 1990.795<br />density: 0.0020687928","Condition: Simple<br />Condition: Simple<br />RT: 1989.489<br />density: 0.0020948744","Condition: Simple<br />Condition: Simple<br />RT: 1988.184<br />density: 0.0021218998","Condition: Simple<br />Condition: Simple<br />RT: 1986.879<br />density: 0.0021495229","Condition: Simple<br />Condition: Simple<br />RT: 1985.573<br />density: 0.0021776390","Condition: Simple<br />Condition: Simple<br />RT: 1984.268<br />density: 0.0022066990","Condition: Simple<br />Condition: Simple<br />RT: 1982.963<br />density: 0.0022362841","Condition: Simple<br />Condition: Simple<br />RT: 1981.658<br />density: 0.0022663348","Condition: Simple<br />Condition: Simple<br />RT: 1980.352<br />density: 0.0022972986","Condition: Simple<br />Condition: Simple<br />RT: 1979.047<br />density: 0.0023287054","Condition: Simple<br />Condition: Simple<br />RT: 1977.742<br />density: 0.0023605546","Condition: Simple<br />Condition: Simple<br />RT: 1976.436<br />density: 0.0023932194","Condition: Simple<br />Condition: Simple<br />RT: 1975.131<br />density: 0.0024262562","Condition: Simple<br />Condition: Simple<br />RT: 1973.826<br />density: 0.0024597097","Condition: Simple<br />Condition: Simple<br />RT: 1972.521<br />density: 0.0024938274","Condition: Simple<br />Condition: Simple<br />RT: 1971.215<br />density: 0.0025282540","Condition: Simple<br />Condition: Simple<br />RT: 1969.910<br />density: 0.0025630483","Condition: Simple<br />Condition: Simple<br />RT: 1968.605<br />density: 0.0025983444","Condition: Simple<br />Condition: Simple<br />RT: 1967.299<br />density: 0.0026338769","Condition: Simple<br />Condition: Simple<br />RT: 1965.994<br />density: 0.0026697038","Condition: Simple<br />Condition: Simple<br />RT: 1964.689<br />density: 0.0027058653","Condition: Simple<br />Condition: Simple<br />RT: 1963.384<br />density: 0.0027421828","Condition: Simple<br />Condition: Simple<br />RT: 1962.078<br />density: 0.0027786971","Condition: Simple<br />Condition: Simple<br />RT: 1960.773<br />density: 0.0028153797","Condition: Simple<br />Condition: Simple<br />RT: 1959.468<br />density: 0.0028521319","Condition: Simple<br />Condition: Simple<br />RT: 1958.162<br />density: 0.0028889604","Condition: Simple<br />Condition: Simple<br />RT: 1956.857<br />density: 0.0029257977","Condition: Simple<br />Condition: Simple<br />RT: 1955.552<br />density: 0.0029626144","Condition: Simple<br />Condition: Simple<br />RT: 1954.247<br />density: 0.0029993660","Condition: Simple<br />Condition: Simple<br />RT: 1952.941<br />density: 0.0030359786","Condition: Simple<br />Condition: Simple<br />RT: 1951.636<br />density: 0.0030724791","Condition: Simple<br />Condition: Simple<br />RT: 1950.331<br />density: 0.0031087557","Condition: Simple<br />Condition: Simple<br />RT: 1949.025<br />density: 0.0031447616","Condition: Simple<br />Condition: Simple<br />RT: 1947.720<br />density: 0.0031805646","Condition: Simple<br />Condition: Simple<br />RT: 1946.415<br />density: 0.0032159715","Condition: Simple<br />Condition: Simple<br />RT: 1945.110<br />density: 0.0032509958","Condition: Simple<br />Condition: Simple<br />RT: 1943.804<br />density: 0.0032857291","Condition: Simple<br />Condition: Simple<br />RT: 1942.499<br />density: 0.0033198853","Condition: Simple<br />Condition: Simple<br />RT: 1941.194<br />density: 0.0033535688","Condition: Simple<br />Condition: Simple<br />RT: 1939.888<br />density: 0.0033868781","Condition: Simple<br />Condition: Simple<br />RT: 1938.583<br />density: 0.0034194255","Condition: Simple<br />Condition: Simple<br />RT: 1937.278<br />density: 0.0034514329","Condition: Simple<br />Condition: Simple<br />RT: 1935.973<br />density: 0.0034829894","Condition: Simple<br />Condition: Simple<br />RT: 1934.667<br />density: 0.0035135999","Condition: Simple<br />Condition: Simple<br />RT: 1933.362<br />density: 0.0035436261","Condition: Simple<br />Condition: Simple<br />RT: 1932.057<br />density: 0.0035731322","Condition: Simple<br />Condition: Simple<br />RT: 1930.751<br />density: 0.0036015138","Condition: Simple<br />Condition: Simple<br />RT: 1929.446<br />density: 0.0036292882","Condition: Simple<br />Condition: Simple<br />RT: 1928.141<br />density: 0.0036564578","Condition: Simple<br />Condition: Simple<br />RT: 1926.836<br />density: 0.0036823815","Condition: Simple<br />Condition: Simple<br />RT: 1925.530<br />density: 0.0037076709","Condition: Simple<br />Condition: Simple<br />RT: 1924.225<br />density: 0.0037322472","Condition: Simple<br />Condition: Simple<br />RT: 1922.920<br />density: 0.0037555328","Condition: Simple<br />Condition: Simple<br />RT: 1921.614<br />density: 0.0037781419","Condition: Simple<br />Condition: Simple<br />RT: 1920.309<br />density: 0.0037999319","Condition: Simple<br />Condition: Simple<br />RT: 1919.004<br />density: 0.0038204125","Condition: Simple<br />Condition: Simple<br />RT: 1917.699<br />density: 0.0038401825","Condition: Simple<br />Condition: Simple<br />RT: 1916.393<br />density: 0.0038590320","Condition: Simple<br />Condition: Simple<br />RT: 1915.088<br />density: 0.0038765752","Condition: Simple<br />Condition: Simple<br />RT: 1913.783<br />density: 0.0038933813","Condition: Simple<br />Condition: Simple<br />RT: 1912.477<br />density: 0.0039091709","Condition: Simple<br />Condition: Simple<br />RT: 1911.172<br />density: 0.0039236752","Condition: Simple<br />Condition: Simple<br />RT: 1909.867<br />density: 0.0039374226","Condition: Simple<br />Condition: Simple<br />RT: 1908.562<br />density: 0.0039500632","Condition: Simple<br />Condition: Simple<br />RT: 1907.256<br />density: 0.0039614539","Condition: Simple<br />Condition: Simple<br />RT: 1905.951<br />density: 0.0039720732","Condition: Simple<br />Condition: Simple<br />RT: 1904.646<br />density: 0.0039815008","Condition: Simple<br />Condition: Simple<br />RT: 1903.341<br />density: 0.0039897246","Condition: Simple<br />Condition: Simple<br />RT: 1902.035<br />density: 0.0039971669","Condition: Simple<br />Condition: Simple<br />RT: 1900.730<br />density: 0.0040033376","Condition: Simple<br />Condition: Simple<br />RT: 1899.425<br />density: 0.0040083581","Condition: Simple<br />Condition: Simple<br />RT: 1898.119<br />density: 0.0040125902","Condition: Simple<br />Condition: Simple<br />RT: 1896.814<br />density: 0.0040154752","Condition: Simple<br />Condition: Simple<br />RT: 1895.509<br />density: 0.0040172687","Condition: Simple<br />Condition: Simple<br />RT: 1894.204<br />density: 0.0040182697","Condition: Simple<br />Condition: Simple<br />RT: 1892.898<br />density: 0.0040178513","Condition: Simple<br />Condition: Simple<br />RT: 1891.593<br />density: 0.0040164039","Condition: Simple<br />Condition: Simple<br />RT: 1890.288<br />density: 0.0040141617","Condition: Simple<br />Condition: Simple<br />RT: 1888.982<br />density: 0.0040104308","Condition: Simple<br />Condition: Simple<br />RT: 1887.677<br />density: 0.0040057362","Condition: Simple<br />Condition: Simple<br />RT: 1886.372<br />density: 0.0040002461","Condition: Simple<br />Condition: Simple<br />RT: 1885.067<br />density: 0.0039932013","Condition: Simple<br />Condition: Simple<br />RT: 1883.761<br />density: 0.0039852602","Condition: Simple<br />Condition: Simple<br />RT: 1882.456<br />density: 0.0039765247","Condition: Simple<br />Condition: Simple<br />RT: 1881.151<br />density: 0.0039661725","Condition: Simple<br />Condition: Simple<br />RT: 1879.845<br />density: 0.0039549935","Condition: Simple<br />Condition: Simple<br />RT: 1878.540<br />density: 0.0039429930","Condition: Simple<br />Condition: Simple<br />RT: 1877.235<br />density: 0.0039293799","Condition: Simple<br />Condition: Simple<br />RT: 1875.930<br />density: 0.0039149814","Condition: Simple<br />Condition: Simple<br />RT: 1874.624<br />density: 0.0038997026","Condition: Simple<br />Condition: Simple<br />RT: 1873.319<br />density: 0.0038828921","Condition: Simple<br />Condition: Simple<br />RT: 1872.014<br />density: 0.0038653056","Condition: Simple<br />Condition: Simple<br />RT: 1870.708<br />density: 0.0038467853","Condition: Simple<br />Condition: Simple<br />RT: 1869.403<br />density: 0.0038268211","Condition: Simple<br />Condition: Simple<br />RT: 1868.098<br />density: 0.0038060946","Condition: Simple<br />Condition: Simple<br />RT: 1866.793<br />density: 0.0037843886","Condition: Simple<br />Condition: Simple<br />RT: 1865.487<br />density: 0.0037613339","Condition: Simple<br />Condition: Simple<br />RT: 1864.182<br />density: 0.0037375360","Condition: Simple<br />Condition: Simple<br />RT: 1862.877<br />density: 0.0037127232","Condition: Simple<br />Condition: Simple<br />RT: 1861.571<br />density: 0.0036866650","Condition: Simple<br />Condition: Simple<br />RT: 1860.266<br />density: 0.0036598885","Condition: Simple<br />Condition: Simple<br />RT: 1858.961<br />density: 0.0036320753","Condition: Simple<br />Condition: Simple<br />RT: 1857.656<br />density: 0.0036031274","Condition: Simple<br />Condition: Simple<br />RT: 1856.350<br />density: 0.0035734931","Condition: Simple<br />Condition: Simple<br />RT: 1855.045<br />density: 0.0035428161","Condition: Simple<br />Condition: Simple<br />RT: 1853.740<br />density: 0.0035111223","Condition: Simple<br />Condition: Simple<br />RT: 1852.434<br />density: 0.0034787811","Condition: Simple<br />Condition: Simple<br />RT: 1851.129<br />density: 0.0034454099","Condition: Simple<br />Condition: Simple<br />RT: 1849.824<br />density: 0.0034111452","Condition: Simple<br />Condition: Simple<br />RT: 1848.519<br />density: 0.0033762795","Condition: Simple<br />Condition: Simple<br />RT: 1847.213<br />density: 0.0033404177","Condition: Simple<br />Condition: Simple<br />RT: 1845.908<br />density: 0.0033037888","Condition: Simple<br />Condition: Simple<br />RT: 1844.603<br />density: 0.0032666127","Condition: Simple<br />Condition: Simple<br />RT: 1843.297<br />density: 0.0032284968","Condition: Simple<br />Condition: Simple<br />RT: 1841.992<br />density: 0.0031897410","Condition: Simple<br />Condition: Simple<br />RT: 1840.687<br />density: 0.0031504987","Condition: Simple<br />Condition: Simple<br />RT: 1839.382<br />density: 0.0031103963","Condition: Simple<br />Condition: Simple<br />RT: 1838.076<br />density: 0.0030697791","Condition: Simple<br />Condition: Simple<br />RT: 1836.771<br />density: 0.0030287423","Condition: Simple<br />Condition: Simple<br />RT: 1835.466<br />density: 0.0029869485","Condition: Simple<br />Condition: Simple<br />RT: 1834.160<br />density: 0.0029447599","Condition: Simple<br />Condition: Simple<br />RT: 1832.855<br />density: 0.0029022238","Condition: Simple<br />Condition: Simple<br />RT: 1831.550<br />density: 0.0028590561","Condition: Simple<br />Condition: Simple<br />RT: 1830.245<br />density: 0.0028156058","Condition: Simple<br />Condition: Simple<br />RT: 1828.939<br />density: 0.0027718756","Condition: Simple<br />Condition: Simple<br />RT: 1827.634<br />density: 0.0027276766","Condition: Simple<br />Condition: Simple<br />RT: 1826.329<br />density: 0.0026832883","Condition: Simple<br />Condition: Simple<br />RT: 1825.023<br />density: 0.0026386897","Condition: Simple<br />Condition: Simple<br />RT: 1823.718<br />density: 0.0025938044","Condition: Simple<br />Condition: Simple<br />RT: 1822.413<br />density: 0.0025488097","Condition: Simple<br />Condition: Simple<br />RT: 1821.108<br />density: 0.0025036895","Condition: Simple<br />Condition: Simple<br />RT: 1819.802<br />density: 0.0024584515","Condition: Simple<br />Condition: Simple<br />RT: 1818.497<br />density: 0.0024131837","Condition: Simple<br />Condition: Simple<br />RT: 1817.192<br />density: 0.0023678884","Condition: Simple<br />Condition: Simple<br />RT: 1815.886<br />density: 0.0023226279","Condition: Simple<br />Condition: Simple<br />RT: 1814.581<br />density: 0.0022774156","Condition: Simple<br />Condition: Simple<br />RT: 1813.276<br />density: 0.0022322847","Condition: Simple<br />Condition: Simple<br />RT: 1811.971<br />density: 0.0021873230","Condition: Simple<br />Condition: Simple<br />RT: 1810.665<br />density: 0.0021424841","Condition: Simple<br />Condition: Simple<br />RT: 1809.360<br />density: 0.0020978442","Condition: Simple<br />Condition: Simple<br />RT: 1808.055<br />density: 0.0020534877","Condition: Simple<br />Condition: Simple<br />RT: 1806.750<br />density: 0.0020093246","Condition: Simple<br />Condition: Simple<br />RT: 1805.444<br />density: 0.0019654835","Condition: Simple<br />Condition: Simple<br />RT: 1804.139<br />density: 0.0019220195","Condition: Simple<br />Condition: Simple<br />RT: 1802.834<br />density: 0.0018788145","Condition: Simple<br />Condition: Simple<br />RT: 1801.528<br />density: 0.0018360571","Condition: Simple<br />Condition: Simple<br />RT: 1800.223<br />density: 0.0017937498","Condition: Simple<br />Condition: Simple<br />RT: 1798.918<br />density: 0.0017517611","Condition: Simple<br />Condition: Simple<br />RT: 1797.613<br />density: 0.0017103459","Condition: Simple<br />Condition: Simple<br />RT: 1796.307<br />density: 0.0016694337","Condition: Simple<br />Condition: Simple<br />RT: 1795.002<br />density: 0.0016288935","Condition: Simple<br />Condition: Simple<br />RT: 1793.697<br />density: 0.0015890501","Condition: Simple<br />Condition: Simple<br />RT: 1792.391<br />density: 0.0015497437","Condition: Simple<br />Condition: Simple<br />RT: 1791.086<br />density: 0.0015108560","Condition: Simple<br />Condition: Simple<br />RT: 1789.781<br />density: 0.0014727835","Condition: Simple<br />Condition: Simple<br />RT: 1788.476<br />density: 0.0014352648","Condition: Simple<br />Condition: Simple<br />RT: 1787.170<br />density: 0.0013982049","Condition: Simple<br />Condition: Simple<br />RT: 1785.865<br />density: 0.0013620715","Condition: Simple<br />Condition: Simple<br />RT: 1784.560<br />density: 0.0013264935","Condition: Simple<br />Condition: Simple<br />RT: 1783.254<br />density: 0.0012914073","Condition: Simple<br />Condition: Simple<br />RT: 1781.949<br />density: 0.0012573506","Condition: Simple<br />Condition: Simple<br />RT: 1780.644<br />density: 0.0012238374","Condition: Simple<br />Condition: Simple<br />RT: 1779.339<br />density: 0.0011908612","Condition: Simple<br />Condition: Simple<br />RT: 1778.033<br />density: 0.0011589700","Condition: Simple<br />Condition: Simple<br />RT: 1776.728<br />density: 0.0011276176","Condition: Simple<br />Condition: Simple<br />RT: 1775.423<br />density: 0.0010968685","Condition: Simple<br />Condition: Simple<br />RT: 1774.117<br />density: 0.0010671938","Condition: Simple<br />Condition: Simple<br />RT: 1772.812<br />density: 0.0010380714","Condition: Simple<br />Condition: Simple<br />RT: 1771.507<br />density: 0.0010096138","Condition: Simple<br />Condition: Simple<br />RT: 1770.202<br />density: 0.0009822049","Condition: Simple<br />Condition: Simple<br />RT: 1768.896<br />density: 0.0009553559","Condition: Simple<br />Condition: Simple<br />RT: 1767.591<br />density: 0.0009292272","Condition: Simple<br />Condition: Simple<br />RT: 1766.286<br />density: 0.0009041086","Condition: Simple<br />Condition: Simple<br />RT: 1764.980<br />density: 0.0008795517","Condition: Simple<br />Condition: Simple<br />RT: 1763.675<br />density: 0.0008557635","Condition: Simple<br />Condition: Simple<br />RT: 1762.370<br />density: 0.0008329358","Condition: Simple<br />Condition: Simple<br />RT: 1761.065<br />density: 0.0008106663","Condition: Simple<br />Condition: Simple<br />RT: 1759.759<br />density: 0.0007892057","Condition: Simple<br />Condition: Simple<br />RT: 1758.454<br />density: 0.0007686471","Condition: Simple<br />Condition: Simple<br />RT: 1757.149<br />density: 0.0007486380","Condition: Simple<br />Condition: Simple<br />RT: 1755.843<br />density: 0.0007294687","Condition: Simple<br />Condition: Simple<br />RT: 1754.538<br />density: 0.0007111354","Condition: Simple<br />Condition: Simple<br />RT: 1753.233<br />density: 0.0006933383","Condition: Simple<br />Condition: Simple<br />RT: 1751.928<br />density: 0.0006764013","Condition: Simple<br />Condition: Simple<br />RT: 1750.622<br />density: 0.0006602291","Condition: Simple<br />Condition: Simple<br />RT: 1749.317<br />density: 0.0006445747","Condition: Simple<br />Condition: Simple<br />RT: 1748.012<br />density: 0.0006297898","Condition: Simple<br />Condition: Simple<br />RT: 1746.706<br />density: 0.0006156943","Condition: Simple<br />Condition: Simple<br />RT: 1745.401<br />density: 0.0006020938","Condition: Simple<br />Condition: Simple<br />RT: 1744.096<br />density: 0.0005893598","Condition: Simple<br />Condition: Simple<br />RT: 1742.791<br />density: 0.0005772376","Condition: Simple<br />Condition: Simple<br />RT: 1741.485<br />density: 0.0005655831","Condition: Simple<br />Condition: Simple<br />RT: 1740.180<br />density: 0.0005547793","Condition: Simple<br />Condition: Simple<br />RT: 1738.875<br />density: 0.0005445088","Condition: Simple<br />Condition: Simple<br />RT: 1737.569<br />density: 0.0005346748","Condition: Simple<br />Condition: Simple<br />RT: 1736.264<br />density: 0.0005256621","Condition: Simple<br />Condition: Simple<br />RT: 1734.959<br />density: 0.0005171049","Condition: Simple<br />Condition: Simple<br />RT: 1733.654<br />density: 0.0005089491","Condition: Simple<br />Condition: Simple<br />RT: 1732.348<br />density: 0.0005015717","Condition: Simple<br />Condition: Simple<br />RT: 1731.043<br />density: 0.0004945741","Condition: Simple<br />Condition: Simple<br />RT: 1729.738<br />density: 0.0004879510","Condition: Simple<br />Condition: Simple<br />RT: 1728.432<br />density: 0.0004820264","Condition: Simple<br />Condition: Simple<br />RT: 1727.127<br />density: 0.0004764213","Condition: Simple<br />Condition: Simple<br />RT: 1725.822<br />density: 0.0004711724","Condition: Simple<br />Condition: Simple<br />RT: 1724.517<br />density: 0.0004665058","Condition: Simple<br />Condition: Simple<br />RT: 1723.211<br />density: 0.0004621151","Condition: Simple<br />Condition: Simple<br />RT: 1721.906<br />density: 0.0004580521","Condition: Simple<br />Condition: Simple<br />RT: 1720.601<br />density: 0.0004544589","Condition: Simple<br />Condition: Simple<br />RT: 1719.295<br />density: 0.0004510961","Condition: Simple<br />Condition: Simple<br />RT: 1717.990<br />density: 0.0004480230","Condition: Simple<br />Condition: Simple<br />RT: 1716.685<br />density: 0.0004453126","Condition: Simple<br />Condition: Simple<br />RT: 1715.380<br />density: 0.0004427864","Condition: Simple<br />Condition: Simple<br />RT: 1714.074<br />density: 0.0004405029","Condition: Simple<br />Condition: Simple<br />RT: 1712.769<br />density: 0.0004384825","Condition: Simple<br />Condition: Simple<br />RT: 1711.464<br />density: 0.0004366003","Condition: Simple<br />Condition: Simple<br />RT: 1710.159<br />density: 0.0004349059","Condition: Simple<br />Condition: Simple<br />RT: 1708.853<br />density: 0.0004333843","Condition: Simple<br />Condition: Simple<br />RT: 1707.548<br />density: 0.0004319558","Condition: Simple<br />Condition: Simple<br />RT: 1706.243<br />density: 0.0004306542","Condition: Simple<br />Condition: Simple<br />RT: 1704.937<br />density: 0.0004294458","Condition: Simple<br />Condition: Simple<br />RT: 1703.632<br />density: 0.0004282872","Condition: Simple<br />Condition: Simple<br />RT: 1702.327<br />density: 0.0004271906","Condition: Simple<br />Condition: Simple<br />RT: 1701.022<br />density: 0.0004261191","Condition: Simple<br />Condition: Simple<br />RT: 1699.716<br />density: 0.0004250572","Condition: Simple<br />Condition: Simple<br />RT: 1698.411<br />density: 0.0004239902","Condition: Simple<br />Condition: Simple<br />RT: 1697.106<br />density: 0.0004228929","Condition: Simple<br />Condition: Simple<br />RT: 1695.800<br />density: 0.0004217683","Condition: Simple<br />Condition: Simple<br />RT: 1694.495<br />density: 0.0004205727","Condition: Simple<br />Condition: Simple<br />RT: 1693.190<br />density: 0.0004193036","Condition: Simple<br />Condition: Simple<br />RT: 1691.885<br />density: 0.0004179748","Condition: Simple<br />Condition: Simple<br />RT: 1690.579<br />density: 0.0004165120","Condition: Simple<br />Condition: Simple<br />RT: 1689.274<br />density: 0.0004149452","Condition: Simple<br />Condition: Simple<br />RT: 1687.969<br />density: 0.0004132910","Condition: Simple<br />Condition: Simple<br />RT: 1686.663<br />density: 0.0004114460","Condition: Simple<br />Condition: Simple<br />RT: 1685.358<br />density: 0.0004094777","Condition: Simple<br />Condition: Simple<br />RT: 1684.053<br />density: 0.0004074001","Condition: Simple<br />Condition: Simple<br />RT: 1682.748<br />density: 0.0004050827","Condition: Simple<br />Condition: Simple<br />RT: 1681.442<br />density: 0.0004026334","Condition: Simple<br />Condition: Simple<br />RT: 1680.137<br />density: 0.0004000543","Condition: Simple<br />Condition: Simple<br />RT: 1678.832<br />density: 0.0003972053","Condition: Simple<br />Condition: Simple<br />RT: 1677.526<br />density: 0.0003942204","Condition: Simple<br />Condition: Simple<br />RT: 1676.221<br />density: 0.0003910836","Condition: Simple<br />Condition: Simple<br />RT: 1674.916<br />density: 0.0003876736","Condition: Simple<br />Condition: Simple<br />RT: 1673.611<br />density: 0.0003841237","Condition: Simple<br />Condition: Simple<br />RT: 1672.305<br />density: 0.0003804057","Condition: Simple<br />Condition: Simple<br />RT: 1671.000<br />density: 0.0003764241","Condition: Simple<br />Condition: Simple<br />RT: 1671.000<br />density: 0.0003764241"],"type":"scatter","mode":"lines","line":{"width":1.88976377952756,"color":"rgba(51,51,51,1)","dash":"solid"},"fill":"toself","fillcolor":"rgba(190,174,212,1)","hoveron":"points","name":"Simple","legendgroup":"Simple","showlegend":true,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null},{"x":[1831.38974632788,2038.35672078989,2150.66797146443,1671.02775193658,2059.7099724913,2069.64340519849,1919.17924489826,1922.61932586059,1920.13829459362,1874.86586212609,1933.20271720123,1859.67613069154,1890.61739893388,2008.72168963049,2134.00667607822,1984.0554526804,1927.84833644032,1871.7077784922,1882.37066291831,2337.65444303788,2017.63915137667,1930.6779078057,1937.75069144517,2063.61155803539,1902.02022933532,1796.99596860353,2079.63742517978,1856.32295125108,1996.75890061073,1868.3559750801,2153.91332054194,1933.20965012349,1899.72390118521,1928.76231009886,1771.09269252103,1836.14477519933,1694.15178513806,1812.23813853394,1957.81172420233,1934.08072561063,2202.26636802051,1850.14286069721,1880.03093778472,1960.28848776575,1860.37591391951,1863.7915462913,1844.07592499591,1823.73653982598,2316.07470723558,2319.9503941521,2111.2883840045,2305.69019104615,2222.1785237493,2237.28757753111,2373.89372220803,2489.86737810597,2662.99635921791,2276.19148267116,2655.6814662911,2214.33340478167,2504.92244627234,2806.77262122035,2394.18217417132,2291.67594503798,2398.06293639149,2683.98834385369,2216.94459035322,2617.65279913899,2612.24448471833,2452.77147076111,2400.66020709351,2327.18176241498,2340.78559367172,2503.2711578846,2731.00794014856,2374.74507541489,2177.27350217141,2283.6417393906,2441.09052562006,2349.07900810428,2371.20309516825,2372.15162483379,2180.20015980061,2372.27298110723,2536.08788127303,2510.63181604166,2486.89027560912,2335.3377657203,2368.75278608911,2208.21071748137,2391.03763795923,2439.9369542839,2671.97470295131,2560.08188420087,2319.97373135109,2456.26335064005],"y":[2.02611042787321,1.97155308064539,2.00392867207993,2.03660359939095,2.00409531199839,2.0151534878416,2.02033717364538,2.0184996540891,1.95056112068705,1.96823672498576,1.95078426213004,2.04880457194522,2.02755229703616,2.03814915991388,2.03359289285727,1.95300738848746,1.96271973841358,1.95362754268572,1.98581835790537,1.98369752555154,1.98382887875196,2.01218925060239,1.97489071839955,2.01303089444991,2.01429345381912,2.04119460762013,1.9651123937685,1.95202706910204,2.0338625214994,1.95641624643467,2.02379591711797,2.01876617730595,2.01851489744149,2.02512498870492,2.0417694458738,1.96828512046486,1.99673915689345,1.9528847664129,2.00895818932913,1.95385560900904,2.00552820737939,1.96303298906423,2.00490192279685,1.99432927556336,2.01867215961684,1.99880472016521,1.9594416274922,1.95936304375064,0.958320486196317,0.968529670941643,0.960876272874884,1.00104448948987,1.02028262924869,1.00892131484579,1.04769343528897,0.979356401576661,0.954248838126659,0.95578915423248,1.02946169804782,0.997383651952259,0.95026032787282,1.00902966798749,0.986746519012377,1.00738267470151,0.953746554930694,0.97459417055361,0.985916717257351,0.985368410055526,0.990741345123388,0.956903458666056,0.999719737004489,1.04854333647527,0.962153589329682,0.987249068007804,0.983823340828531,1.00958356806077,0.966727676428854,1.02964681433514,0.968267931602895,0.979783974797465,1.01030974423047,0.977135410229675,0.962014683149755,1.01120564006269,0.97858151558321,0.997055452107452,1.00153068476357,1.01405759383924,1.03436509780586,0.969477182719857,0.988863835996017,0.986146638682112,1.03916704396252,1.02723725787364,1.03551168071572,0.95100826357957],"text":["Condition: Simple<br />RT: 1831<br />ID: 1","Condition: Simple<br />RT: 2038<br />ID: 2","Condition: Simple<br />RT: 2151<br />ID: 3","Condition: Simple<br />RT: 1671<br />ID: 4","Condition: Simple<br />RT: 2060<br />ID: 5","Condition: Simple<br />RT: 2070<br />ID: 6","Condition: Simple<br />RT: 1919<br />ID: 7","Condition: Simple<br />RT: 1923<br />ID: 8","Condition: Simple<br />RT: 1920<br />ID: 9","Condition: Simple<br />RT: 1875<br />ID: 10","Condition: Simple<br />RT: 1933<br />ID: 11","Condition: Simple<br />RT: 1860<br />ID: 12","Condition: Simple<br />RT: 1891<br />ID: 13","Condition: Simple<br />RT: 2009<br />ID: 14","Condition: Simple<br />RT: 2134<br />ID: 15","Condition: Simple<br />RT: 1984<br />ID: 16","Condition: Simple<br />RT: 1928<br />ID: 17","Condition: Simple<br />RT: 1872<br />ID: 18","Condition: Simple<br />RT: 1882<br />ID: 19","Condition: Simple<br />RT: 2338<br />ID: 20","Condition: Simple<br />RT: 2018<br />ID: 21","Condition: Simple<br />RT: 1931<br />ID: 22","Condition: Simple<br />RT: 1938<br />ID: 23","Condition: Simple<br />RT: 2064<br />ID: 24","Condition: Simple<br />RT: 1902<br />ID: 25","Condition: Simple<br />RT: 1797<br />ID: 26","Condition: Simple<br />RT: 2080<br />ID: 27","Condition: Simple<br />RT: 1856<br />ID: 28","Condition: Simple<br />RT: 1997<br />ID: 29","Condition: Simple<br />RT: 1868<br />ID: 30","Condition: Simple<br />RT: 2154<br />ID: 31","Condition: Simple<br />RT: 1933<br />ID: 32","Condition: Simple<br />RT: 1900<br />ID: 33","Condition: Simple<br />RT: 1929<br />ID: 34","Condition: Simple<br />RT: 1771<br />ID: 35","Condition: Simple<br />RT: 1836<br />ID: 36","Condition: Simple<br />RT: 1694<br />ID: 37","Condition: Simple<br />RT: 1812<br />ID: 38","Condition: Simple<br />RT: 1958<br />ID: 39","Condition: Simple<br />RT: 1934<br />ID: 40","Condition: Simple<br />RT: 2202<br />ID: 41","Condition: Simple<br />RT: 1850<br />ID: 42","Condition: Simple<br />RT: 1880<br />ID: 43","Condition: Simple<br />RT: 1960<br />ID: 44","Condition: Simple<br />RT: 1860<br />ID: 45","Condition: Simple<br />RT: 1864<br />ID: 46","Condition: Simple<br />RT: 1844<br />ID: 47","Condition: Simple<br />RT: 1824<br />ID: 48","Condition: Complex<br />RT: 2316<br />ID: 1","Condition: Complex<br />RT: 2320<br />ID: 2","Condition: Complex<br />RT: 2111<br />ID: 3","Condition: Complex<br />RT: 2306<br />ID: 4","Condition: Complex<br />RT: 2222<br />ID: 5","Condition: Complex<br />RT: 2237<br />ID: 6","Condition: Complex<br />RT: 2374<br />ID: 7","Condition: Complex<br />RT: 2490<br />ID: 8","Condition: Complex<br />RT: 2663<br />ID: 9","Condition: Complex<br />RT: 2276<br />ID: 10","Condition: Complex<br />RT: 2656<br />ID: 11","Condition: Complex<br />RT: 2214<br />ID: 12","Condition: Complex<br />RT: 2505<br />ID: 13","Condition: Complex<br />RT: 2807<br />ID: 14","Condition: Complex<br />RT: 2394<br />ID: 15","Condition: Complex<br />RT: 2292<br />ID: 16","Condition: Complex<br />RT: 2398<br />ID: 17","Condition: Complex<br />RT: 2684<br />ID: 18","Condition: Complex<br />RT: 2217<br />ID: 19","Condition: Complex<br />RT: 2618<br />ID: 20","Condition: Complex<br />RT: 2612<br />ID: 21","Condition: Complex<br />RT: 2453<br />ID: 22","Condition: Complex<br />RT: 2401<br />ID: 23","Condition: Complex<br />RT: 2327<br />ID: 24","Condition: Complex<br />RT: 2341<br />ID: 25","Condition: Complex<br />RT: 2503<br />ID: 26","Condition: Complex<br />RT: 2731<br />ID: 27","Condition: Complex<br />RT: 2375<br />ID: 28","Condition: Complex<br />RT: 2177<br />ID: 29","Condition: Complex<br />RT: 2284<br />ID: 30","Condition: Complex<br />RT: 2441<br />ID: 31","Condition: Complex<br />RT: 2349<br />ID: 32","Condition: Complex<br />RT: 2371<br />ID: 33","Condition: Complex<br />RT: 2372<br />ID: 34","Condition: Complex<br />RT: 2180<br />ID: 35","Condition: Complex<br />RT: 2372<br />ID: 36","Condition: Complex<br />RT: 2536<br />ID: 37","Condition: Complex<br />RT: 2511<br />ID: 38","Condition: Complex<br />RT: 2487<br />ID: 39","Condition: Complex<br />RT: 2335<br />ID: 40","Condition: Complex<br />RT: 2369<br />ID: 41","Condition: Complex<br />RT: 2208<br />ID: 42","Condition: Complex<br />RT: 2391<br />ID: 43","Condition: Complex<br />RT: 2440<br />ID: 44","Condition: Complex<br />RT: 2672<br />ID: 45","Condition: Complex<br />RT: 2560<br />ID: 46","Condition: Complex<br />RT: 2320<br />ID: 47","Condition: Complex<br />RT: 2456<br />ID: 48"],"type":"scatter","mode":"markers","marker":{"autocolorscale":false,"color":"rgba(0,0,0,1)","opacity":0.25,"size":5.66929133858268,"symbol":"circle","line":{"width":1.88976377952756,"color":"rgba(0,0,0,1)"}},"hoveron":"points","showlegend":false,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null},{"x":[2409.875,1936.35416666667],"y":[1,2],"text":["Condition: Complex<br />RT: 2409.875","Condition: Simple<br />RT: 1936.354"],"type":"scatter","mode":"lines+markers","opacity":1,"line":{"color":"transparent"},"error_x":{"array":[43.8406249999998,35.859375],"arrayminus":[40.0078124999995,32.6921875],"type":"data","width":0,"symmetric":false,"color":"rgba(0,0,0,1)"},"showlegend":false,"xaxis":"x","yaxis":"y","hoverinfo":"text","marker":{"autocolorscale":false,"color":"rgba(0,0,0,1)","opacity":1,"size":3.77952755905512,"symbol":"circle","line":{"width":3.77952755905512,"color":"rgba(0,0,0,1)"}},"hoveron":"points","frame":null}],"layout":{"margin":{"t":30.6118721461187,"r":7.30593607305936,"b":44.5662100456621,"l":66.4840182648402},"plot_bgcolor":"rgba(255,255,255,1)","paper_bgcolor":"rgba(255,255,255,1)","font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187},"xaxis":{"domain":[0,1],"automargin":true,"type":"linear","autorange":false,"range":[1614.2,2863.8],"tickmode":"array","ticktext":["2000","2400","2800"],"tickvals":[2000,2400,2800],"categoryorder":"array","categoryarray":["2000","2400","2800"],"nticks":null,"ticks":"outside","tickcolor":"rgba(51,51,51,1)","ticklen":3.65296803652968,"tickwidth":0.66417600664176,"showticklabels":true,"tickfont":{"color":"rgba(77,77,77,1)","family":"","size":11.689497716895},"tickangle":-0,"showline":true,"linecolor":"rgba(0,0,0,1)","linewidth":0.66417600664176,"showgrid":false,"gridcolor":null,"gridwidth":0,"zeroline":false,"anchor":"y","title":{"text":"Reaction Time (ms.)","font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187}},"hoverformat":".2f"},"yaxis":{"domain":[0,1],"automargin":true,"type":"linear","autorange":false,"range":[0.4,2.6],"tickmode":"array","ticktext":["Complex","Simple"],"tickvals":[1,2],"categoryorder":"array","categoryarray":["Complex","Simple"],"nticks":null,"ticks":"outside","tickcolor":"rgba(51,51,51,1)","ticklen":3.65296803652968,"tickwidth":0.66417600664176,"showticklabels":true,"tickfont":{"color":"rgba(77,77,77,1)","family":"","size":11.689497716895},"tickangle":-0,"showline":true,"linecolor":"rgba(0,0,0,1)","linewidth":0.66417600664176,"showgrid":false,"gridcolor":null,"gridwidth":0,"zeroline":false,"anchor":"x","title":{"text":"Condition","font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187}},"hoverformat":".2f"},"shapes":[{"type":"rect","fillcolor":null,"line":{"color":null,"width":0,"linetype":[]},"yref":"paper","xref":"paper","x0":0,"x1":1,"y0":0,"y1":1}],"showlegend":true,"legend":{"bgcolor":"rgba(255,255,255,1)","bordercolor":"transparent","borderwidth":1.88976377952756,"font":{"color":"rgba(0,0,0,1)","family":"","size":11.689497716895},"y":0.922047244094488},"annotations":[{"text":"Condition","x":1.02,"y":1,"showarrow":false,"ax":0,"ay":0,"font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187},"xref":"paper","yref":"paper","textangle":-0,"xanchor":"left","yanchor":"bottom","legendTitle":true}],"hovermode":"closest","width":800,"height":400,"barmode":"relative"},"config":{"doubleClick":"reset","showSendToCloud":false},"source":"A","attrs":{"1c916543cf32":{"fill":{},"x":{},"y":{},"label":{},"type":"scatter"},"1c9146d80f8e":{"x":{},"y":{},"label":{}},"1c9112e557f8":{"x":{},"y":{},"label":{}}},"cur_data":"1c916543cf32","visdat":{"1c916543cf32":["function (y) ","x"],"1c9146d80f8e":["function (y) ","x"],"1c9112e557f8":["function (y) ","x"]},"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.2,"selected":{"opacity":1},"debounce":0},"shinyEvents":["plotly_hover","plotly_click","plotly_selected","plotly_relayout","plotly_brushed","plotly_brushing","plotly_clickannotation","plotly_doubleclick","plotly_deselect","plotly_afterplot"],"base_url":"https://plot.ly"},"evals":[],"jsHooks":[]}</script> ] --- # Raincloud Plots <!-- --> .footnote[Allen M, Poggiali D, Whitaker K et al. Raincloud plots: a multi-platform tool for robust data visualization [version 1; peer review: 2 approved]. Wellcome Open Res 2019, 4:63 https://doi.org/10.12688/wellcomeopenres.15191.1 ] --- # Using Different Themes You can change the ggplot theme to a number of built in ones (or define your own.) On the next page you'll see the same plot with (a) the Economics theme, (b) the fivethirtyeight theme, (c) the Tufte theme, and (d) the solarized theme. Below is the plot with the default theme. .center[ <!-- --> ] --- class: center, middle <!-- --> --- class: center, middle <!-- --> --- class: center, middle <!-- --> --- class: center, middle <!-- --> --- # The BBC Cookbook The BBC (like many other organisations such as the FT) use R and ggplot to generate their data They have even published their own style guide and code for their BBC data visualisation theme. https://bbc.github.io/rcookbook/ .center[ <img src="images/bbc.png" width="80%" /> ] --- # World Happiness Data We can have a look at the World Happiness dataset that measures Happiness (called Life Ladder) and a bunch of other things (e.g., GDP) over countries over time. .center[ ```r vis_dat(happy_data) ``` <!-- --> ] --- .center[ ```r vis_miss(happy_data) ``` <!-- --> ] --- .top[ <!-- --> ] .bottom[ ```r happy_data %>% group_by(country) %>% filter(!is.na(`Life Ladder`) & year == 2016) %>% summarise(score = `Life Ladder`) %>% mutate(country = reorder(country, score)) %>% top_n(20) %>% ggplot(aes(x = score, y = country)) + geom_point() + labs(x = "Happiness Index Score", y = "Country", title = "Top 20 Happiest Countries in 2016") + theme_tufte(base_size = 15) ``` ] --- .top[ <!-- --> ] .bottom[ ```r country_list <- c("United Kingdom", "France", "Germany", "Italy", "Norway", "United States") happy_data %>% filter(country %in% country_list) %>% filter(!is.na(`Social support`)) %>% mutate(score = `Social support`) %>% mutate(country = reorder(country, score)) %>% ggplot(aes(y = score, x = country, fill = country)) + geom_boxplot(width = .5) + labs(y = "Boxplot of Social support", x = "Country", title = "Social support") + guides(fill = FALSE) + coord_flip() + theme_tufte(base_size = 15) ``` ] --- .top[ <!-- --> ] .bottom[ ```r happy_data %>% filter(country %in% country_list) %>% group_by(country) %>% mutate(score = `Life Ladder`) %>% ungroup() %>% mutate(country = reorder(country, score)) %>% ggplot(aes(x = country, y = score)) + geom_boxplot() + labs(x = "Country", y = "Happiness Index Score", title = "Average Happiness Index for 6 Countries") + coord_flip() + theme_fivethirtyeight(base_size = 15) ``` ] --- .top[ <!-- --> ] .bottom[ ```r country_list <- c("United Kingdom", "France", "Germany", "Italy", "Norway", "United States") happy_data %>% filter(country %in% country_list) %>% group_by(year) %>% filter(!is.na(`Life Ladder`)) %>% ggplot(aes(x = year, y = `Life Ladder`)) + geom_line() + facet_wrap(~ country) + labs(x = "Year", y = "Happiness index", title = "Happiness Index over Time for 6 Countries") + theme_fivethirtyeight(base_size = 15) + theme(axis.text.x = element_text(angle = 45, hjust = 1)) ``` ] --- # Visualising Qualitative Data Maybe you have lots of qualitative data and are interested in running a content analysis. In the next example, I'm examining all the text in HG Wells' The War of the Worlds. .center[ <!-- --> ] --- ```r # Get 2 HG Wells books #### titles <- "The War of the Worlds" books <- gutenberg_works(title %in% titles) %>% gutenberg_download(meta_fields = "title") text_waroftheworlds <- books %>% unnest_tokens(word, text) %>% anti_join(stop_words) text_waroftheworlds %>% count(word) %>% top_n(10) %>% mutate(word = reorder(word, n)) %>% ggplot(aes(x = word, y = n, fill = word)) + geom_col() + coord_flip() + guides(fill = FALSE) + labs(title = "Top 10 words in The War of the Worlds") text_waroftheworlds_count <- text_waroftheworlds %>% count(word) %>% top_n(200) ``` --- .center[.middle[ <!-- --> ]] --- ```r set.seed(1234) wordcloud(words = text_waroftheworlds_count$word, freq = text_waroftheworlds_count$n, min.freq = 1, scale = c(3, 1), max.words = 125, random.order = FALSE, rot.per = 0.35, colors = brewer.pal(8, "Dark2")) ``` .center[ <!-- --> ] --- # Sentiment Analyis .center[ <!-- --> ] --- ```r sentiments <- get_sentiments("bing") word_counts <- text_waroftheworlds %>% inner_join(sentiments) %>% count(word, sentiment, sort = TRUE) ``` ```r word_counts %>% filter(n > 20) %>% mutate(n = ifelse(sentiment == "negative", -n, n)) %>% mutate(word = reorder(word, n)) %>% ggplot(aes(word, n, fill = sentiment)) + geom_col() + coord_flip() + labs(y = "Contribution to sentiment", title = "Sentiment Analysis of Words in The War of the Worlds") ``` --- # Visualising Data from Twitter Scraping Twitter using the rtweet() package for everyone's favourite progressive Swedish death metal band, Opeth! 🤘 <p> .center[ <!-- --> ] --- class: centre # Geospatial Plotting of Tweets .center[ <div id="htmlwidget-723311d1b12a3bff68b0" style="width:576px;height:432px;" class="leaflet html-widget"></div> <script type="application/json" data-for="htmlwidget-723311d1b12a3bff68b0">{"x":{"options":{"crs":{"crsClass":"L.CRS.EPSG3857","code":null,"proj4def":null,"projectedBounds":null,"options":{}}},"calls":[{"method":"addTiles","args":["//{s}.tile.openstreetmap.org/{z}/{x}/{y}.png",null,null,{"minZoom":0,"maxZoom":18,"tileSize":256,"subdomains":"abc","errorTileUrl":"","tms":false,"noWrap":false,"zoomOffset":0,"zoomReverse":false,"opacity":1,"zIndex":1,"detectRetina":false,"attribution":"© <a href=\"http://openstreetmap.org\">OpenStreetMap<\/a> contributors, <a href=\"http://creativecommons.org/licenses/by-sa/2.0/\">CC-BY-SA<\/a>"}]},{"method":"addCircles","args":[[null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,35.2051821,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,29.59624885,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,51.4735988,null,null,null,51.7540589,null,null,null,null,14.112749,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,41.62368665,null,null,null,null,null,null,null,null,null,19.4326,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,41.39881,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,33.63933985,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,51.3854457438995,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,44.7228734,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,41.6135944,null,null,null,null,null,null,null,null,38.91436445,null,41.09993079,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,50.8324662,null,null,46.86818435,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,41.15,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-54.8059242,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-16.61605585,null,null,null,null,null,null,null,null,null,48.18733868,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,40.7207559,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,43.629311,null,null,null,null,null,6.270882997653,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,36.8783453,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,60.700368,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,41.0213205,null,null,null,-37.97256651425,null,null,32.33287645,42.913149,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,35.0922805,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-8.043603,null,43.37736025,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,40.67087955,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-31.5613888,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,18.4470345,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null],[null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,25.63968535,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,31.57060625,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,5.6531046,null,null,null,-0.23073865,null,null,null,null,-87.2007724,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-8.12054865,null,null,null,null,null,null,null,null,null,-99.1332,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,27.42360085,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-111.8583985,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-0.25275396881444,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-85.6540935,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,21.743291,null,null,null,null,null,null,null,null,-75.43003995,null,-73.51761831,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-0.32496315,null,null,0.37519385,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-73.984562,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-68.2955622,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-43.9388051,null,null,null,null,null,null,null,null,null,16.41272239,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-74.0007613,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-79.2725695,null,null,null,null,null,-75.6192130002448,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-4.4322267,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-135.0677745,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,29.0052228,null,null,null,145.053135344,null,null,-116.9291021,-85.50071195,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-80.6909725,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-34.939349,null,-70.52517065,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-73.8311875,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-52.3338952,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-66.1717845,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null],40,null,null,{"interactive":true,"className":"","stroke":true,"color":"#fb3004","weight":8,"opacity":0.5,"fill":true,"fillColor":"#fb3004","fillOpacity":0.8},null,null,null,{"interactive":false,"permanent":false,"direction":"auto","opacity":1,"offset":[0,0],"textsize":"10px","textOnly":false,"className":"","sticky":true},null,null]}],"limits":{"lat":[-54.8059242,60.700368],"lng":[-135.0677745,145.053135344]}},"evals":[],"jsHooks":[]}</script> ] --- class: middle, center # Teaching with Animations --- # Data Simulations and Data Visualisation - Hockey Game Simulation Imagine a hockey game where we know that Team A scores exactly 1 goal for sure and Team B takes 20 shots, each with a 5.5% chance of going in. Which team would you rather be? (nothing additional happens if you tie.) ```r set.seed(1234) team_b_goals <- NULL for(i in 1:10000) { score <- sum(sample(c(1, 0), size = 20, replace = TRUE, prob = c(0.055, 1-.055))) team_b_goals <- c(team_b_goals, score)} team_a_goals <- rep(1, 10000) all_games <- as_tibble(cbind(team_a_goals, team_b_goals)) ``` --- ``` ## [1] "Games where Team A scores more goals than Team B: 3145" ``` ``` ## [1] "Games where Team A scores fewer goals than Team B: 3050" ``` ``` ## [1] "Games where there is a tie : 3805" ``` .center[ <!-- --> ] --- # Illustrating sampling error with animations On the left N=20 from the <b>same</b> population. We <b>appear</b> to find differences between our conditions. On the right when N=500 it's clear the two conditions are equivalent. .pull-left[ <!-- --> ] .pull-right[ <!-- --> ] --- # Sample size of 25 when population r = .5 .center[ <!-- --> ] --- class: center <!-- --> --- # Sample size of 250 when population r = .5 .center[ <!-- --> ] --- class: center 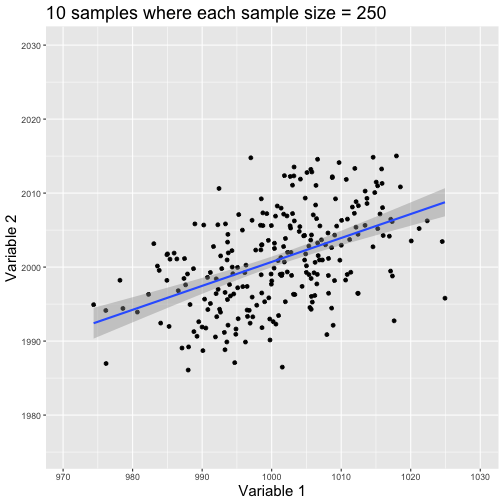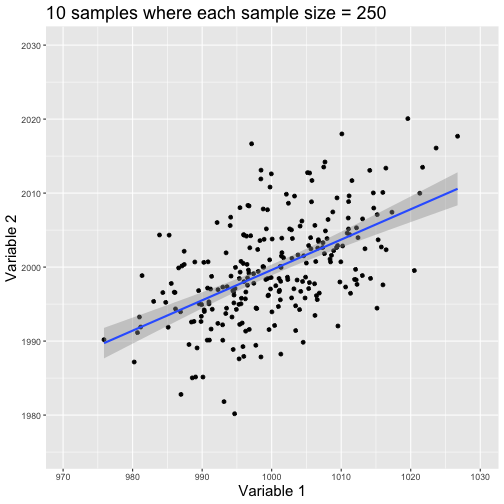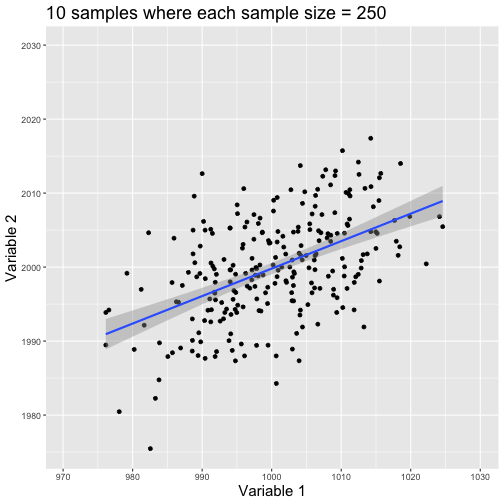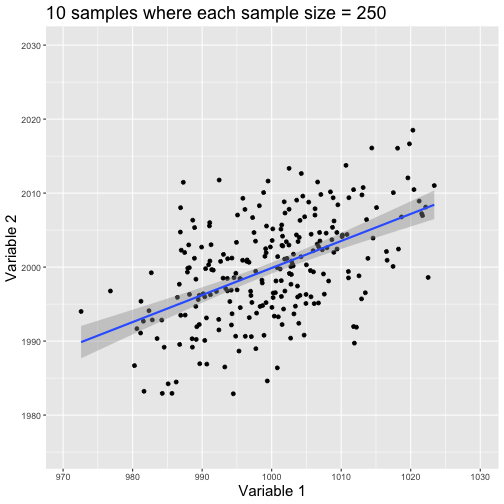<!-- --> --- class: center, middle # Make it Reproducible --- class: middle "<i>(visualisations)</i> should be autogenerated as part of the data analysis pipeline (which should also be automated), and they should come out of the pipeline ready to be sent to the printer... ...the moment you manually edit a figure, your final figure becomes irreproducible. A third party cannot generate the exact same figure you did. Interactive plot programs are a bad idea. They inherently force you to manually prepare your figures...be aware that Excel is an interactive plot program...and is not recommended for figure preparation (or data analysis)." .pull-left[ .center[ <img src="images/wilke.png" width="200" /> ] ] .pull-right[ <i>Claus Wilke, Fundamentals of Data Visualization (2019). Page xiii.</i> ] --- # Using OSF or GitHub Both the Open Science Foundation (https://osf.io) and GitHub (https://github.com) can be used to host your data and analysis code. If you have pre-registered your study or have gone down the registered report route (where your research is unconditionally accepted for publication before you've started collecting data) then you can link your data and analysis code with the pre-registration itself. However, if you just make your data and code publically available an interested reader still has to manually re-run your code to reproduce your results. They need to know which R version and which package versions you used in your analysis. --- # Use Zenodo to give your data and code a DOI .center[ <img src="images/zenodo.png" width="550" /> ] You can share this DOI alongside your output - this also allows others to cite your dataset if they use it. --- # Using R Markdown Using R Markdown you can generate a document that contains narrative, your code AND output, making your analysis transparent and allowing a reader to see your analysis, output, and text explaining what you did (and why). You can use your R Markdown script to produce HTML, Word, or PDF documents. HTML documents allow you to embed animated graphs. --- # Example R Markdown Document .center[ <img src="images/graph1.png" width="575" /> ] --- # Using R Markdown Templates .pull-left[ A number of R Markdown templates are available that allow you to write entire papers and talks (like this one) in R Markdown. <br><br> The Papaja template (https://github.com/crsh) by Frederik Aust allows you to write APA formatted outputs and render in HTML, Word, and PDF format. .center[ <img src="images/frederik.png" width="175" /> ] ] .pull-right[ This talk was written in R Markdown using the Xaringan Presentation Ninja package (https://github.com/yihui/xaringan) by Yihui Xie at RStudio. <br><br> When I 'knit' my Markdown file, all the data visualisations, Twitter scraping etc. occurs on the fly as my slides are rendered. .center[ <img src="images/yihui.png" width="175" /> ] ] --- # Interested in finding out more? .pull-left[ <img src="images/r4ds.jpg" width="175" /> <img src="images/cover.jpg" width="175" /> ] .pull-right[ <img src="images/healy.jpg" width="175" /> <img src="images/wilke.png" width="175" /> ] --- <img src="images/tidytuesday.png" width="1241" /> --- # Thanks! .pull-left[ <img src="images/ssi.png" width="1575" height="80%" /> ] .pull-right[ <img src="images/bsbr.jpg" width="640" height="70%" /> ] --- class: center # A Fully Reproducible Talk (just add my accent) All slides and R code used to generate these slides available here: https://github.com/ajstewartlang/ajstewartlang.github.io/tree/master/Lancaster_talk <img src="images/github.svg" width="50%" /> .footnote[ Slides created via the R package [**xaringan**](https://github.com/yihui/xaringan), [**knitr**](http://yihui.name/knitr), and [R Markdown](https://rmarkdown.rstudio.com). ]